




Samet Oymak
@oymak.bsky.social
EECS Prof @UMich, Research on the Foundations of ML+RL+LLM
https://sota.engin.umich.edu/
https://sota.engin.umich.edu/
Some SAC context for NeurIPS 2025 review scores - out of my batch of 100 papers:
- 1 paper ≥5.0
- 6 papers ≥4.5
- 11 papers ≥4.0
- 25 papers ≥3.75
- 42 papers ≥3.5
Good luck to all with rebuttals!
- 1 paper ≥5.0
- 6 papers ≥4.5
- 11 papers ≥4.0
- 25 papers ≥3.75
- 42 papers ≥3.5
Good luck to all with rebuttals!
July 24, 2025 at 5:02 PM
Some SAC context for NeurIPS 2025 review scores - out of my batch of 100 papers:
- 1 paper ≥5.0
- 6 papers ≥4.5
- 11 papers ≥4.0
- 25 papers ≥3.75
- 42 papers ≥3.5
Good luck to all with rebuttals!
- 1 paper ≥5.0
- 6 papers ≥4.5
- 11 papers ≥4.0
- 25 papers ≥3.75
- 42 papers ≥3.5
Good luck to all with rebuttals!
I was actually discussing SimPO a few weeks ago in my LLM class. Solid work!
December 3, 2024 at 5:37 PM
I was actually discussing SimPO a few weeks ago in my LLM class. Solid work!
I like "slay" here. Makes theory research more RPG-like

arxiv.org/abs/2411.17668 Our postdoc zihan slays another COLT open problem! proceedings.mlr.press/v247/kornows...

Anytime Acceleration of Gradient Descent
This work investigates stepsize-based acceleration of gradient descent with {\em anytime} convergence guarantees. For smooth (non-strongly) convex optimization, we propose a stepsize schedule that all...
arxiv.org
November 28, 2024 at 2:59 PM
I like "slay" here. Makes theory research more RPG-like
Reposted by Samet Oymak

NeurIPS Test of Time Awards:
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
November 27, 2024 at 5:32 PM
NeurIPS Test of Time Awards:
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
All credits go to my amazing students :)

November 21, 2024 at 10:19 PM
All credits go to my amazing students :)
Our method uniformly improves language modeling evals with negligible compute overhead. During evals, we just plug in SSA and don't touch hyperparams/architecture so there is likely further headroom.
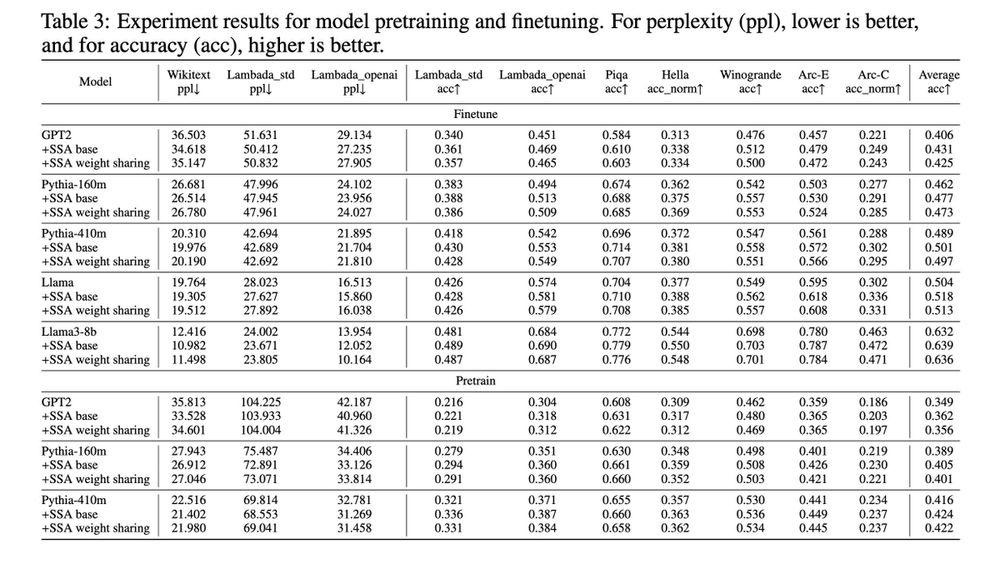
November 21, 2024 at 10:19 PM
Our method uniformly improves language modeling evals with negligible compute overhead. During evals, we just plug in SSA and don't touch hyperparams/architecture so there is likely further headroom.
We can also see the approximation benefit directly from the quality/sharpness of the attention maps.
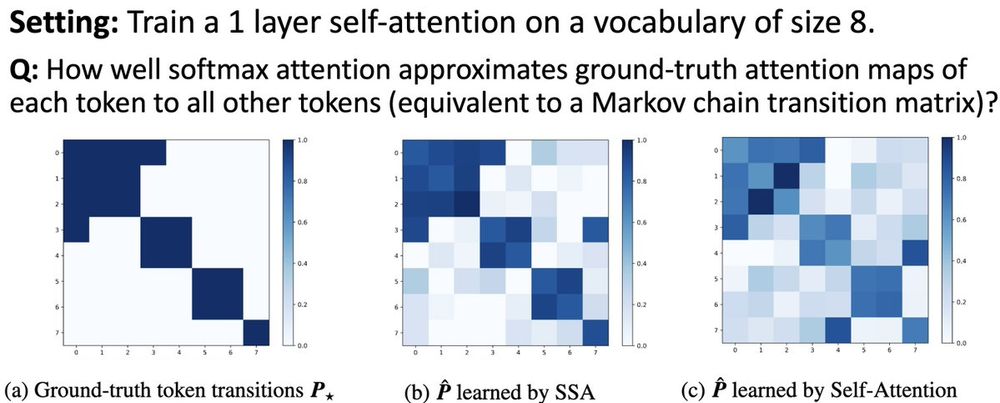
November 21, 2024 at 10:19 PM
We can also see the approximation benefit directly from the quality/sharpness of the attention maps.
Why is this useful? Consider the tokens "Hinton" and "Scientist". These have high cosine similarity but we wish to assign them different spikiness levels. We show that this is provably difficult to achieve for vanilla attention, namely its weights have to grow much larger compared to our method.
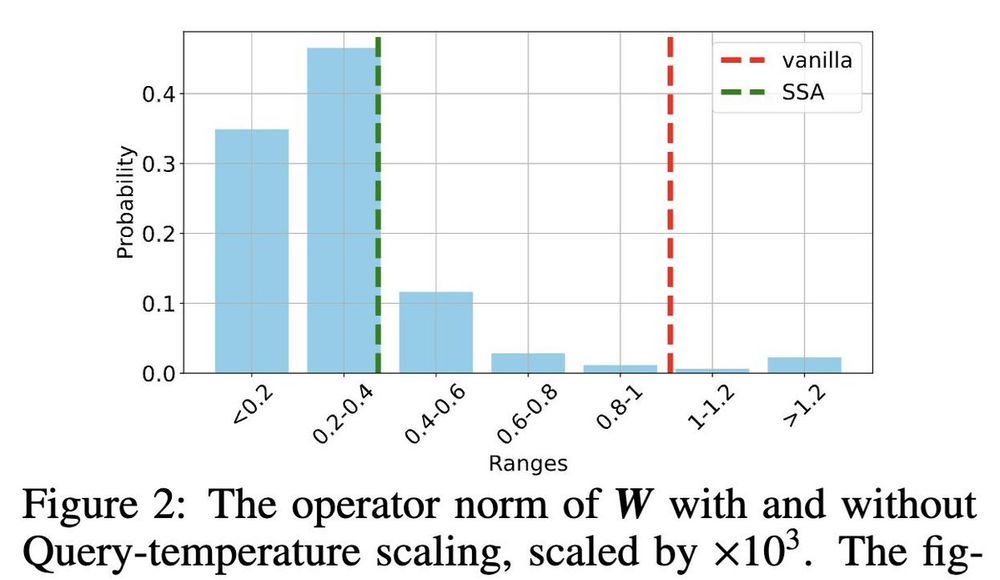
November 21, 2024 at 10:19 PM
Why is this useful? Consider the tokens "Hinton" and "Scientist". These have high cosine similarity but we wish to assign them different spikiness levels. We show that this is provably difficult to achieve for vanilla attention, namely its weights have to grow much larger compared to our method.
The method adds a temperature-scaling (scalar gating) after K/Q/V embeddings and before softmax. Temperature is a function of the token embedding and its position. Notably, this can be done by - fine-tuning rather than pretraining - using very few additional parameters
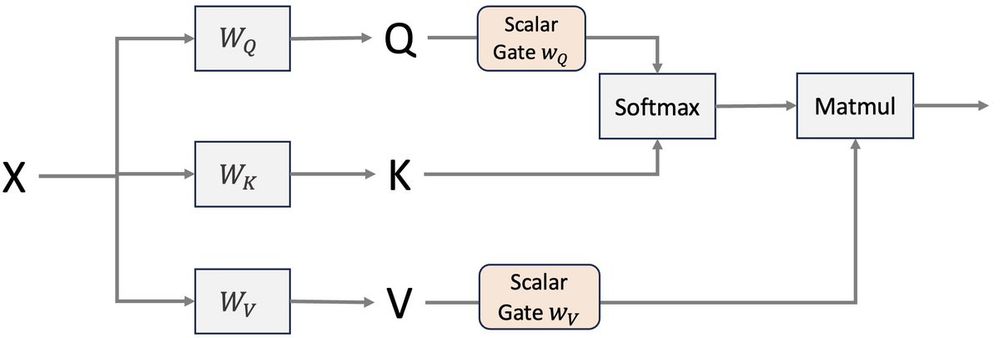
November 21, 2024 at 10:19 PM
The method adds a temperature-scaling (scalar gating) after K/Q/V embeddings and before softmax. Temperature is a function of the token embedding and its position. Notably, this can be done by - fine-tuning rather than pretraining - using very few additional parameters
The intuition is that specific tokens like "Hinton" should receive a spikier attention map compared to generalist tokens like "Scientist". Learning token-dependent temperatures with this results in the colormap above where (arguably) more specific words receive low temperatures.
November 21, 2024 at 10:19 PM
The intuition is that specific tokens like "Hinton" should receive a spikier attention map compared to generalist tokens like "Scientist". Learning token-dependent temperatures with this results in the colormap above where (arguably) more specific words receive low temperatures.
Hello world! Unfortunately, my first post happens to be a paper (thre)ad 😊: Our “Selective Attention” is a simple but effective method that dynamically adjusts the sparsity of the attention maps through temperature scaling: arxiv.org/pdf/2411.12892 (#neurips2024)

November 21, 2024 at 10:19 PM
Hello world! Unfortunately, my first post happens to be a paper (thre)ad 😊: Our “Selective Attention” is a simple but effective method that dynamically adjusts the sparsity of the attention maps through temperature scaling: arxiv.org/pdf/2411.12892 (#neurips2024)