




Zach Mueller
@muellerzr.bsky.social
Technical Lead on Accelerate @ Hugging Face | Passionate about Open Source | https://muellerzr.github.io
Pinned
Zach Mueller
@muellerzr.bsky.social
· Jun 22

Hi all 👋
Back very briefly to mention I’m working on a new course, and there’s a star-studded set of guest speakers 🎉
From Scratch to Scale: Distributed Training (from the ground up).
From now until I’m done writing the course material, it’s 25% off :)
maven.com/walk-with-co...
Back very briefly to mention I’m working on a new course, and there’s a star-studded set of guest speakers 🎉
From Scratch to Scale: Distributed Training (from the ground up).
From now until I’m done writing the course material, it’s 25% off :)
maven.com/walk-with-co...
DataLoader Dispatching
When constrained by a variety of reasons to where you can't include multiple copies (or mmaps) of datasets in memory, be it too many concurrent streams, low resource availability, or a slow CPU, dispatching is here to help.
When constrained by a variety of reasons to where you can't include multiple copies (or mmaps) of datasets in memory, be it too many concurrent streams, low resource availability, or a slow CPU, dispatching is here to help.

October 5, 2025 at 12:02 PM
DataLoader Dispatching
When constrained by a variety of reasons to where you can't include multiple copies (or mmaps) of datasets in memory, be it too many concurrent streams, low resource availability, or a slow CPU, dispatching is here to help.
When constrained by a variety of reasons to where you can't include multiple copies (or mmaps) of datasets in memory, be it too many concurrent streams, low resource availability, or a slow CPU, dispatching is here to help.
Batch Sampler Sharding

October 3, 2025 at 11:24 AM
Batch Sampler Sharding
Dataset Sharding
When performing distributed data parallelism, we split the dataset every batch so every device sees a different chunk of the data. There are different methods for doing so. One example is sharding at the *dataset* level, shown here.
When performing distributed data parallelism, we split the dataset every batch so every device sees a different chunk of the data. There are different methods for doing so. One example is sharding at the *dataset* level, shown here.

October 2, 2025 at 11:05 AM
Dataset Sharding
When performing distributed data parallelism, we split the dataset every batch so every device sees a different chunk of the data. There are different methods for doing so. One example is sharding at the *dataset* level, shown here.
When performing distributed data parallelism, we split the dataset every batch so every device sees a different chunk of the data. There are different methods for doing so. One example is sharding at the *dataset* level, shown here.
Hi all 👋
Back very briefly to mention I’m working on a new course, and there’s a star-studded set of guest speakers 🎉
From Scratch to Scale: Distributed Training (from the ground up).
From now until I’m done writing the course material, it’s 25% off :)
maven.com/walk-with-co...
Back very briefly to mention I’m working on a new course, and there’s a star-studded set of guest speakers 🎉
From Scratch to Scale: Distributed Training (from the ground up).
From now until I’m done writing the course material, it’s 25% off :)
maven.com/walk-with-co...
June 22, 2025 at 11:18 PM
Hi all 👋
Back very briefly to mention I’m working on a new course, and there’s a star-studded set of guest speakers 🎉
From Scratch to Scale: Distributed Training (from the ground up).
From now until I’m done writing the course material, it’s 25% off :)
maven.com/walk-with-co...
Back very briefly to mention I’m working on a new course, and there’s a star-studded set of guest speakers 🎉
From Scratch to Scale: Distributed Training (from the ground up).
From now until I’m done writing the course material, it’s 25% off :)
maven.com/walk-with-co...
Reposted by Zach Mueller

AAAHHHHHHHHH BE NICE TO OPEN SOURCE MAINTAINERS OH MY GOD. SOME OF YOU ARE SO RUDE, WHO RAISED YOU
March 10, 2025 at 5:32 PM
AAAHHHHHHHHH BE NICE TO OPEN SOURCE MAINTAINERS OH MY GOD. SOME OF YOU ARE SO RUDE, WHO RAISED YOU
JK STRONG is still awesome. Solution (which they were already aware of this) was literally logout -> login!
11/10 customer support
11/10 customer support
Enshittification has come to my gym app. Lord help us all 😭
March 11, 2025 at 12:02 PM
JK STRONG is still awesome. Solution (which they were already aware of this) was literally logout -> login!
11/10 customer support
11/10 customer support
Enshittification has come to my gym app. Lord help us all 😭
March 11, 2025 at 11:28 AM
Enshittification has come to my gym app. Lord help us all 😭
Reposted by Zach Mueller


Recently did my first lifting competition, overall quite happy where things ended up (bar bench) and was a ton of fun. Might wait a year and give it another go, but I did get first in the weight class!
145kg squat
180kg deadlift
90kg bench
145kg squat
180kg deadlift
90kg bench




March 2, 2025 at 4:20 PM
Recently did my first lifting competition, overall quite happy where things ended up (bar bench) and was a ton of fun. Might wait a year and give it another go, but I did get first in the weight class!
145kg squat
180kg deadlift
90kg bench
145kg squat
180kg deadlift
90kg bench
I guess work is done for the day, everyone can go home 🤷♂️
February 26, 2025 at 5:51 PM
I guess work is done for the day, everyone can go home 🤷♂️
Reposted by Zach Mueller

A federal judge in Maryland issued a temporary restraining order on Monday, blocking members of Elon Musk’s so-called Department of Government Efficiency team and anyone “working on the DOGE agenda at the Department of Education” from accessing sensitive data until March 10.
February 24, 2025 at 2:52 PM
A federal judge in Maryland issued a temporary restraining order on Monday, blocking members of Elon Musk’s so-called Department of Government Efficiency team and anyone “working on the DOGE agenda at the Department of Education” from accessing sensitive data until March 10.
Day one of new program: ✅
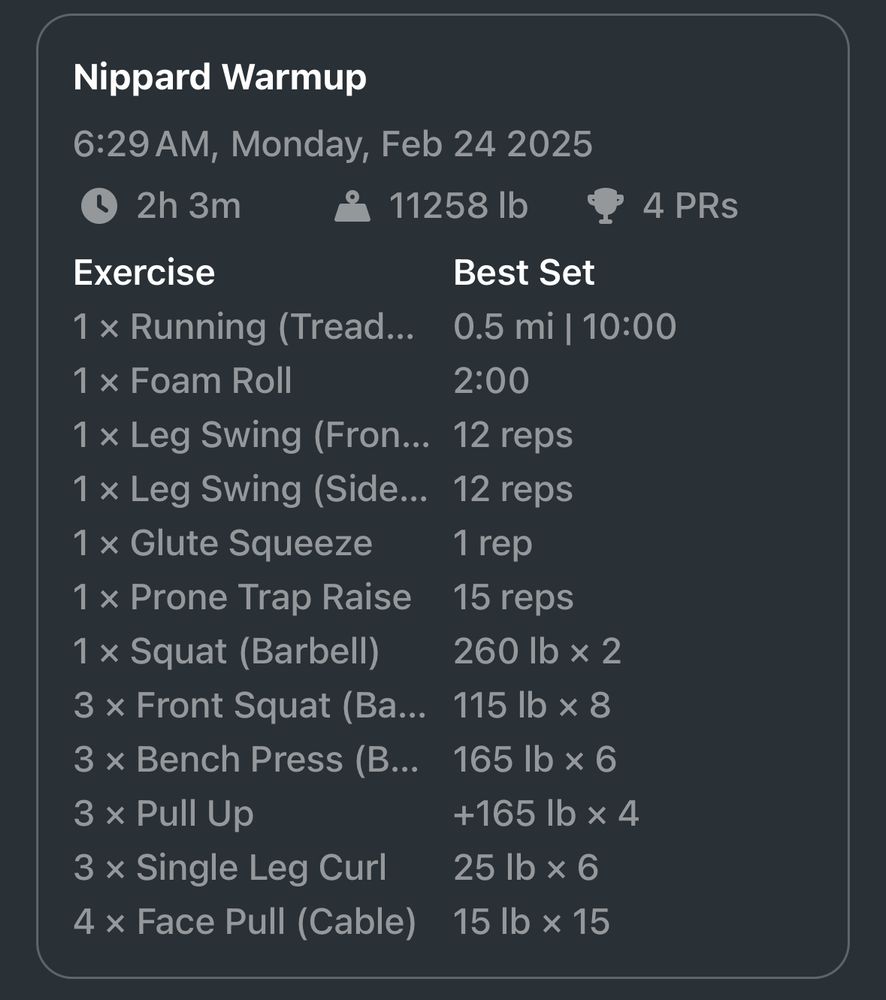
February 24, 2025 at 1:33 PM
Day one of new program: ✅
Nothing humbles you more than a front squat.
Going from 260lbs back squat to 115lbs front squat was *lovely*
Going from 260lbs back squat to 115lbs front squat was *lovely*
February 24, 2025 at 12:27 PM
Nothing humbles you more than a front squat.
Going from 260lbs back squat to 115lbs front squat was *lovely*
Going from 260lbs back squat to 115lbs front squat was *lovely*
Reposted by Zach Mueller

Interesting discussions between John Ousterhout and "Uncle Bob" on software design: method length, comments, and test-driven development. It's a great example of "agree to disagree". There is no silver bullet in software design. Let's focus on writing easy-to-parse code 👀
github.com/johnousterho...
github.com/johnousterho...
February 23, 2025 at 8:56 PM
Interesting discussions between John Ousterhout and "Uncle Bob" on software design: method length, comments, and test-driven development. It's a great example of "agree to disagree". There is no silver bullet in software design. Let's focus on writing easy-to-parse code 👀
github.com/johnousterho...
github.com/johnousterho...
Estimated read time: 2-3 days
Who’s going to be the first to start a study group?
Who’s going to be the first to start a study group?
After 6+ months in the making and over a year of GPU compute, we're excited to release the "Ultra-Scale Playbook": hf.co/spaces/nanot...
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!

The Ultra-Scale Playbook - a Hugging Face Space by nanotron
The ultimate guide to training LLM on large GPU Clusters
hf.co
February 19, 2025 at 8:42 PM
Estimated read time: 2-3 days
Who’s going to be the first to start a study group?
Who’s going to be the first to start a study group?
Reposted by Zach Mueller

After 6+ months in the making and over a year of GPU compute, we're excited to release the "Ultra-Scale Playbook": hf.co/spaces/nanot...
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
The Ultra-Scale Playbook - a Hugging Face Space by nanotron
The ultimate guide to training LLM on large GPU Clusters
hf.co
February 19, 2025 at 6:10 PM
After 6+ months in the making and over a year of GPU compute, we're excited to release the "Ultra-Scale Playbook": hf.co/spaces/nanot...
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
Anyone in my bubble built a lack rack before? 👀
Eyeballing doing this for the new place
Eyeballing doing this for the new place
February 14, 2025 at 1:57 PM
Anyone in my bubble built a lack rack before? 👀
Eyeballing doing this for the new place
Eyeballing doing this for the new place
0/10 can’t recommend:
* Selling your house
* Buying a house (*after* putting your old house on the market)
* Lifting competition
All in the same week
* Selling your house
* Buying a house (*after* putting your old house on the market)
* Lifting competition
All in the same week
February 13, 2025 at 4:56 PM
0/10 can’t recommend:
* Selling your house
* Buying a house (*after* putting your old house on the market)
* Lifting competition
All in the same week
* Selling your house
* Buying a house (*after* putting your old house on the market)
* Lifting competition
All in the same week
Update:
Ran the equivalent of this space locally via fastapi + hooked into the LLM commit message generator got the job done, and very fast (since it’s a T5 model under the hood)
huggingface.co/spaces/mamik...
Ran the equivalent of this space locally via fastapi + hooked into the LLM commit message generator got the job done, and very fast (since it’s a T5 model under the hood)
huggingface.co/spaces/mamik...
February 10, 2025 at 3:36 AM
Update:
Ran the equivalent of this space locally via fastapi + hooked into the LLM commit message generator got the job done, and very fast (since it’s a T5 model under the hood)
huggingface.co/spaces/mamik...
Ran the equivalent of this space locally via fastapi + hooked into the LLM commit message generator got the job done, and very fast (since it’s a T5 model under the hood)
huggingface.co/spaces/mamik...
Me post seeing SmolLM2 quant is fast enough to run on my tiny laptop

February 10, 2025 at 12:58 AM
Me post seeing SmolLM2 quant is fast enough to run on my tiny laptop
February 3, 2025 at 1:54 PM
Reposted by Zach Mueller

We are reproducing the full DeepSeek R1 data and training pipeline so everybody can use their recipe. Instead of doing it in secret we can do it together in the open!
Follow along: github.com/huggingface/...
Follow along: github.com/huggingface/...

GitHub - huggingface/open-r1: Fully open reproduction of DeepSeek-R1
Fully open reproduction of DeepSeek-R1. Contribute to huggingface/open-r1 development by creating an account on GitHub.
github.com
January 25, 2025 at 1:29 PM
We are reproducing the full DeepSeek R1 data and training pipeline so everybody can use their recipe. Instead of doing it in secret we can do it together in the open!
Follow along: github.com/huggingface/...
Follow along: github.com/huggingface/...
Reposted by Zach Mueller

Wrote up my selfish personal argument for releasing code as Open Source: if you solve a problem and then release it under an Open Source license you will never have to solve that problem again for the rest of your career!
simonwillison.net/2025/Jan/24/...
simonwillison.net/2025/Jan/24/...
A selfish personal argument for releasing code as Open Source
I’m the guest for the most recent episode of the Real Python podcast with Christopher Bailey, talking about Using LLMs for Python Development. We covered a lot of other topics …
simonwillison.net
January 24, 2025 at 9:47 PM
Wrote up my selfish personal argument for releasing code as Open Source: if you solve a problem and then release it under an Open Source license you will never have to solve that problem again for the rest of your career!
simonwillison.net/2025/Jan/24/...
simonwillison.net/2025/Jan/24/...
Me: huh where’s the cell signal go. Where’d the internet go
Verizon:
I suppose I’m forcibly done with work for the day, too bad I had to go to the next town over to say that 😅
Verizon:
I suppose I’m forcibly done with work for the day, too bad I had to go to the next town over to say that 😅

January 24, 2025 at 8:05 PM
Me: huh where’s the cell signal go. Where’d the internet go
Verizon:
I suppose I’m forcibly done with work for the day, too bad I had to go to the next town over to say that 😅
Verizon:
I suppose I’m forcibly done with work for the day, too bad I had to go to the next town over to say that 😅