



Matt Groh
@mattgroh.bsky.social
Assistant professor at Northwestern Kellogg | human AI collaboration | computational social science | affective computing
Pinned
Matt Groh
@mattgroh.bsky.social
· Jun 17

How do we reliably judge if AI companions are performing well on subjective, context-dependent, and deeply human tasks? 🤖
Excited to share the first paper from my postdoc (!!) investigating when LLMs are reliable judges - with empathic communication as a case study 🧐
🧵👇
Excited to share the first paper from my postdoc (!!) investigating when LLMs are reliable judges - with empathic communication as a case study 🧐
🧵👇

When are LLMs-as-judge reliable?
That's a big question for frontier labs and it's a big question for computational social science.
Excited to share our findings (led by @aakriti1kumar.bsky.social!) on how to address this question for any subjective task & specifically for empathic communications
That's a big question for frontier labs and it's a big question for computational social science.
Excited to share our findings (led by @aakriti1kumar.bsky.social!) on how to address this question for any subjective task & specifically for empathic communications
Looking forward to @maxkreminski.bsky.social speaking @nicoatnu.bsky.social tomorrow!

It’s notoriously difficulty to evaluate interfaces intended to support creative work. This Wednesday, NICO is thrilled to host @maxkreminski.bsky.social from Midjourney to discuss: "Tracing and Shaping Paths in Design Space". #WedatNICO #AI
🗓️ Wed 10/22 at 12pm US Central
🔗 bit.ly/WedatNICO
🗓️ Wed 10/22 at 12pm US Central
🔗 bit.ly/WedatNICO

October 21, 2025 at 9:16 PM
Looking forward to @maxkreminski.bsky.social speaking @nicoatnu.bsky.social tomorrow!
Happening today!
People handle the everyday physical world with remarkable ease, but how do we do it? This Wednesday, NICO is thrilled to host @tomerullman.bsky.social, to discuss: "Good Enough: Approximations in Mental Simulation and Intuitive Physics".
🗓️ Wed 10/8 at 12pm US Central
🔗 bit.ly/WedatNICO
🗓️ Wed 10/8 at 12pm US Central
🔗 bit.ly/WedatNICO

October 8, 2025 at 1:49 PM
Happening today!
On my way to @ic2s2.bsky.social in Norrköping!! Super excited to share this year’s projects in the HAIC lab revealing how (M)LLMs can offer insights into human behavior & cognition
More at human-ai-collaboration-lab.kellogg.northwestern.edu/ic2s2
See you there!
#IC2S2
More at human-ai-collaboration-lab.kellogg.northwestern.edu/ic2s2
See you there!
#IC2S2

July 21, 2025 at 8:25 AM
On my way to @ic2s2.bsky.social in Norrköping!! Super excited to share this year’s projects in the HAIC lab revealing how (M)LLMs can offer insights into human behavior & cognition
More at human-ai-collaboration-lab.kellogg.northwestern.edu/ic2s2
See you there!
#IC2S2
More at human-ai-collaboration-lab.kellogg.northwestern.edu/ic2s2
See you there!
#IC2S2
When are LLMs-as-judge reliable?
That's a big question for frontier labs and it's a big question for computational social science.
Excited to share our findings (led by @aakriti1kumar.bsky.social!) on how to address this question for any subjective task & specifically for empathic communications
That's a big question for frontier labs and it's a big question for computational social science.
Excited to share our findings (led by @aakriti1kumar.bsky.social!) on how to address this question for any subjective task & specifically for empathic communications
How do we reliably judge if AI companions are performing well on subjective, context-dependent, and deeply human tasks? 🤖
Excited to share the first paper from my postdoc (!!) investigating when LLMs are reliable judges - with empathic communication as a case study 🧐
🧵👇
Excited to share the first paper from my postdoc (!!) investigating when LLMs are reliable judges - with empathic communication as a case study 🧐
🧵👇
June 17, 2025 at 3:23 PM
When are LLMs-as-judge reliable?
That's a big question for frontier labs and it's a big question for computational social science.
Excited to share our findings (led by @aakriti1kumar.bsky.social!) on how to address this question for any subjective task & specifically for empathic communications
That's a big question for frontier labs and it's a big question for computational social science.
Excited to share our findings (led by @aakriti1kumar.bsky.social!) on how to address this question for any subjective task & specifically for empathic communications
Awesome write up in Kellogg Insight on our paper published at #CHI2025 this week!
insight.kellogg.northwestern.edu/article/are-...
insight.kellogg.northwestern.edu/article/are-...

When Put to the Test, Are We Any Good at Spotting AI Fakes?
For the most part, yes! And the more we look, the better we get.
insight.kellogg.northwestern.edu
May 1, 2025 at 7:10 PM
Awesome write up in Kellogg Insight on our paper published at #CHI2025 this week!
insight.kellogg.northwestern.edu/article/are-...
insight.kellogg.northwestern.edu/article/are-...
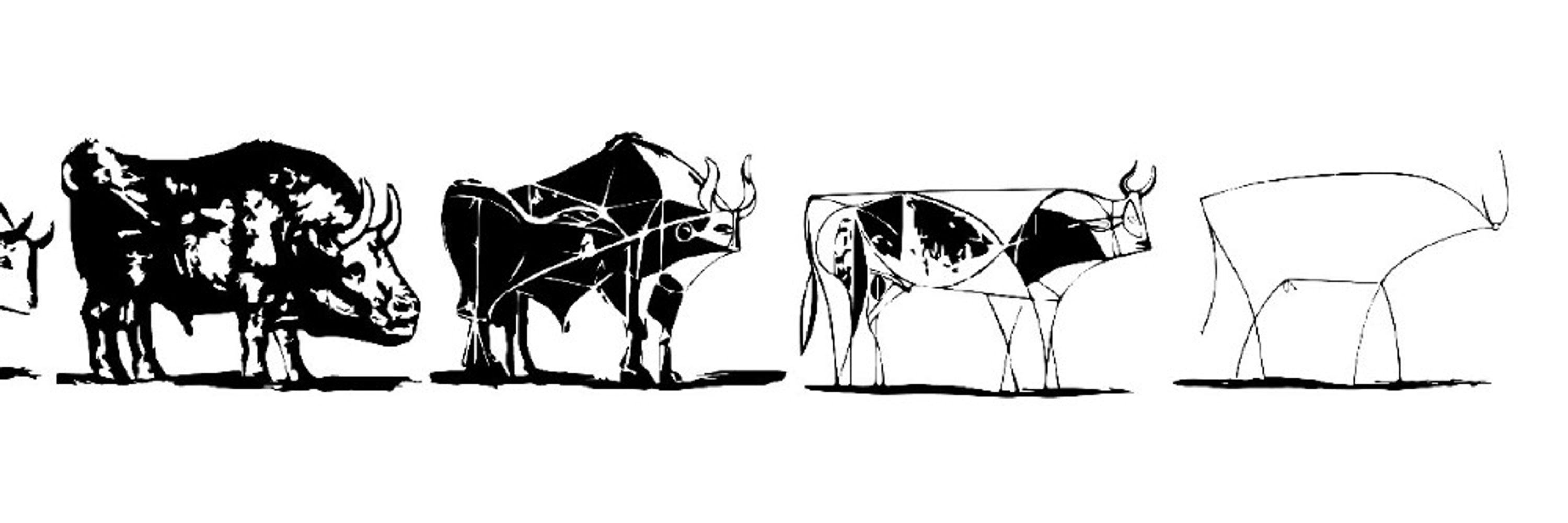
💡New paper at #CHI2025 💡
Large scale experiment with 750k obs addressing
(1) How photorealistic are today's AI-generated images?
(2) What features of images influence people's ability to distinguish real/fake?
(3) How should we categorize artifacts?
Large scale experiment with 750k obs addressing
(1) How photorealistic are today's AI-generated images?
(2) What features of images influence people's ability to distinguish real/fake?
(3) How should we categorize artifacts?
April 25, 2025 at 3:15 PM
💡New paper at #CHI2025 💡
Large scale experiment with 750k obs addressing
(1) How photorealistic are today's AI-generated images?
(2) What features of images influence people's ability to distinguish real/fake?
(3) How should we categorize artifacts?
Large scale experiment with 750k obs addressing
(1) How photorealistic are today's AI-generated images?
(2) What features of images influence people's ability to distinguish real/fake?
(3) How should we categorize artifacts?
📣 📣 Postdoc Opportunity at Northwestern
Dashun Wang and I are seeking a creative, technical, interdisciplinary researcher for a joint postdoc fellowship between our labs.
If you're passionate about Human-AI Collaboration and Science of Science, this may be for you! 🚀
Please share widely!
Dashun Wang and I are seeking a creative, technical, interdisciplinary researcher for a joint postdoc fellowship between our labs.
If you're passionate about Human-AI Collaboration and Science of Science, this may be for you! 🚀
Please share widely!

April 2, 2025 at 1:00 PM
📣 📣 Postdoc Opportunity at Northwestern
Dashun Wang and I are seeking a creative, technical, interdisciplinary researcher for a joint postdoc fellowship between our labs.
If you're passionate about Human-AI Collaboration and Science of Science, this may be for you! 🚀
Please share widely!
Dashun Wang and I are seeking a creative, technical, interdisciplinary researcher for a joint postdoc fellowship between our labs.
If you're passionate about Human-AI Collaboration and Science of Science, this may be for you! 🚀
Please share widely!
V2 of the Human and Machine Intelligence 😊🤖🧠 is in the books!
So many fantastic discussions as we witnessed the frontier of AI shift even further into hyperdrive✨
Props to students for all the hard work and big thanks to teaching assistants and guest speakers 🙏
So many fantastic discussions as we witnessed the frontier of AI shift even further into hyperdrive✨
Props to students for all the hard work and big thanks to teaching assistants and guest speakers 🙏


March 20, 2025 at 12:53 AM
V2 of the Human and Machine Intelligence 😊🤖🧠 is in the books!
So many fantastic discussions as we witnessed the frontier of AI shift even further into hyperdrive✨
Props to students for all the hard work and big thanks to teaching assistants and guest speakers 🙏
So many fantastic discussions as we witnessed the frontier of AI shift even further into hyperdrive✨
Props to students for all the hard work and big thanks to teaching assistants and guest speakers 🙏
What is perception? What do we really see when we look at the world?
And, why does the amodal completion illusion lead us to see a super long reindeer in the image on the right?
This week @chazfirestone.bsky.social joined the NU CogSci seminar series to address these fundamental questions
And, why does the amodal completion illusion lead us to see a super long reindeer in the image on the right?
This week @chazfirestone.bsky.social joined the NU CogSci seminar series to address these fundamental questions


March 7, 2025 at 4:01 PM
What is perception? What do we really see when we look at the world?
And, why does the amodal completion illusion lead us to see a super long reindeer in the image on the right?
This week @chazfirestone.bsky.social joined the NU CogSci seminar series to address these fundamental questions
And, why does the amodal completion illusion lead us to see a super long reindeer in the image on the right?
This week @chazfirestone.bsky.social joined the NU CogSci seminar series to address these fundamental questions
2024 marks the official launch of the Human-AI Collaboration Lab, so I wrote a one page letter to introduce the lab, share highlights, and begin a lab tradition of reflecting on the year and sharing what we're working on in an easy to digest annual letter to share with friends and colleagues.

December 31, 2024 at 6:54 PM
2024 marks the official launch of the Human-AI Collaboration Lab, so I wrote a one page letter to introduce the lab, share highlights, and begin a lab tradition of reflecting on the year and sharing what we're working on in an easy to digest annual letter to share with friends and colleagues.
Fun to join Ellie, Joanna, and Naira on the She's Thinking podcast about our research on human-AI collaboration in medicine
And really cool to hear Dr. Katie Fraser's research on AI for early detection of neurodegenerative diseases in the first half of the episode!
open.spotify.com/episode/3X5H...
And really cool to hear Dr. Katie Fraser's research on AI for early detection of neurodegenerative diseases in the first half of the episode!
open.spotify.com/episode/3X5H...

Closing Health Disparities: A.I. in Medicine
She's Thinking Podcast · Episode
open.spotify.com
December 12, 2024 at 4:54 PM
Fun to join Ellie, Joanna, and Naira on the She's Thinking podcast about our research on human-AI collaboration in medicine
And really cool to hear Dr. Katie Fraser's research on AI for early detection of neurodegenerative diseases in the first half of the episode!
open.spotify.com/episode/3X5H...
And really cool to hear Dr. Katie Fraser's research on AI for early detection of neurodegenerative diseases in the first half of the episode!
open.spotify.com/episode/3X5H...
I'm teaching my second iteration of "Human and Machine Intelligence" 🧠🤖 for Kellogg MBAs.
I updated the syllabus with a couple 2024 books + new lectures and readings.
What else do you think MBA students should be reading on this topic?
docs.google.com/document/d/1...
I updated the syllabus with a couple 2024 books + new lectures and readings.
What else do you think MBA students should be reading on this topic?
docs.google.com/document/d/1...

Copy of W25_MORS950_Human_and_Machine_Intelligence.docx
Human and Machine Intelligence (MORS 950) Professor Matt Groh | he/him/his | [email protected] Section 31 | Evanston Section 81 | Chicago Office Hours: Schedule available on Ca...
docs.google.com
December 11, 2024 at 9:56 PM
I'm teaching my second iteration of "Human and Machine Intelligence" 🧠🤖 for Kellogg MBAs.
I updated the syllabus with a couple 2024 books + new lectures and readings.
What else do you think MBA students should be reading on this topic?
docs.google.com/document/d/1...
I updated the syllabus with a couple 2024 books + new lectures and readings.
What else do you think MBA students should be reading on this topic?
docs.google.com/document/d/1...
Reposted by Matt Groh

"Media literacy is super awesome. But it needs to extend to AI literacy," says @mattgroh.bsky.social in this story ⤵️
We agree, which is why we have a page dedicated to teaching about #AI, with resources including quizzes & an infographic: newslit.org/ai/
www.fox47news.com/politics/dis...
We agree, which is why we have a page dedicated to teaching about #AI, with resources including quizzes & an infographic: newslit.org/ai/
www.fox47news.com/politics/dis...

Real vs. fake: Can you spot AI-generated images?
Some images generated by artificial intelligence have become so convincingly real that there is no surefire way to spot the fakes. But experts say there are still things we can try to detect fakes.
www.fox47news.com
December 10, 2024 at 10:08 PM
"Media literacy is super awesome. But it needs to extend to AI literacy," says @mattgroh.bsky.social in this story ⤵️
We agree, which is why we have a page dedicated to teaching about #AI, with resources including quizzes & an infographic: newslit.org/ai/
www.fox47news.com/politics/dis...
We agree, which is why we have a page dedicated to teaching about #AI, with resources including quizzes & an infographic: newslit.org/ai/
www.fox47news.com/politics/dis...
Reposted by Matt Groh

New paper out in @ScienceMagazine! In 8 studies (multiple platforms, methods, time periods) we find: misinformation evokes more outrage than trustworthy news, when it does it's shared more + ppl are less likely to read before sharing. w/ @killianmcl1 @Klonick @mollycrockett 🧵👇

November 28, 2024 at 7:07 PM
New paper out in @ScienceMagazine! In 8 studies (multiple platforms, methods, time periods) we find: misinformation evokes more outrage than trustworthy news, when it does it's shared more + ppl are less likely to read before sharing. w/ @killianmcl1 @Klonick @mollycrockett 🧵👇
Reposted by Matt Groh

Welcome Bluesky followers!
A 🧵 about my JMP: Using language to generate hypotheses
This paper explores how language shapes behavior. Our contribution, however, is not in testing specific hypotheses- its in generating them (using #LLMs + #ML + #BehSci)
But how exactly?
www.rafaelmbatista.com/jmp/
A 🧵 about my JMP: Using language to generate hypotheses
This paper explores how language shapes behavior. Our contribution, however, is not in testing specific hypotheses- its in generating them (using #LLMs + #ML + #BehSci)
But how exactly?
www.rafaelmbatista.com/jmp/

November 15, 2024 at 4:50 PM
Welcome Bluesky followers!
A 🧵 about my JMP: Using language to generate hypotheses
This paper explores how language shapes behavior. Our contribution, however, is not in testing specific hypotheses- its in generating them (using #LLMs + #ML + #BehSci)
But how exactly?
www.rafaelmbatista.com/jmp/
A 🧵 about my JMP: Using language to generate hypotheses
This paper explores how language shapes behavior. Our contribution, however, is not in testing specific hypotheses- its in generating them (using #LLMs + #ML + #BehSci)
But how exactly?
www.rafaelmbatista.com/jmp/
Long before "deepfakes" and AI-generated media created anxiety of whether we can trust images' authenticity, @stewartbrand.bsky.social speculated on the "End of Photography as Evidence"
Re-reading this before joining a panel of lawyers to speak on deepfakes
go.activecalendar.com/FordhamUnive...
Re-reading this before joining a panel of lawyers to speak on deepfakes
go.activecalendar.com/FordhamUnive...



November 22, 2024 at 2:15 AM
Long before "deepfakes" and AI-generated media created anxiety of whether we can trust images' authenticity, @stewartbrand.bsky.social speculated on the "End of Photography as Evidence"
Re-reading this before joining a panel of lawyers to speak on deepfakes
go.activecalendar.com/FordhamUnive...
Re-reading this before joining a panel of lawyers to speak on deepfakes
go.activecalendar.com/FordhamUnive...
The ability for thoughtful people to spot AI-generated poetry in a couple seconds vs. the study's participants reveals classic problems inherent to Imitation Game research:
Lack of domain expertise & lack of knowledge of AI's capabilities and limitations -> falling for & even preferring simulacra
Lack of domain expertise & lack of knowledge of AI's capabilities and limitations -> falling for & even preferring simulacra

November 22, 2024 at 1:31 AM
The ability for thoughtful people to spot AI-generated poetry in a couple seconds vs. the study's participants reveals classic problems inherent to Imitation Game research:
Lack of domain expertise & lack of knowledge of AI's capabilities and limitations -> falling for & even preferring simulacra
Lack of domain expertise & lack of knowledge of AI's capabilities and limitations -> falling for & even preferring simulacra
I'm recruiting a PhD student to join the Human AI Collaboration lab at Kellogg, NU CS, and @nicoatnu.bsky.social
If you're excited about computational social science, LLMs, digital experiments, real-world problem solving, this could be a great fit
Please reshare!
Deets 👇
If you're excited about computational social science, LLMs, digital experiments, real-world problem solving, this could be a great fit
Please reshare!
Deets 👇

November 19, 2024 at 9:41 PM
I'm recruiting a PhD student to join the Human AI Collaboration lab at Kellogg, NU CS, and @nicoatnu.bsky.social
If you're excited about computational social science, LLMs, digital experiments, real-world problem solving, this could be a great fit
Please reshare!
Deets 👇
If you're excited about computational social science, LLMs, digital experiments, real-world problem solving, this could be a great fit
Please reshare!
Deets 👇
Reposted by Matt Groh

I created a starter pack for human-AI collaboration in case that this would be helpful for some newcomers, which overlaps with several existing starter packs. Let me know if you would like to be added.
go.bsky.app/MRV1Wa1
go.bsky.app/MRV1Wa1
November 15, 2024 at 7:05 PM
I created a starter pack for human-AI collaboration in case that this would be helpful for some newcomers, which overlaps with several existing starter packs. Let me know if you would like to be added.
go.bsky.app/MRV1Wa1
go.bsky.app/MRV1Wa1
Why does ChatGPT outperform physicians + ChatGPT in this clinical vignette study?
User error seems to be the culprit
If users don't know how to interact with the technology (however easy it may seem), then the experiment misses out on what would happen if participants had basic knowledge LLMs
User error seems to be the culprit
If users don't know how to interact with the technology (however easy it may seem), then the experiment misses out on what would happen if participants had basic knowledge LLMs


November 18, 2024 at 3:36 PM
Why does ChatGPT outperform physicians + ChatGPT in this clinical vignette study?
User error seems to be the culprit
If users don't know how to interact with the technology (however easy it may seem), then the experiment misses out on what would happen if participants had basic knowledge LLMs
User error seems to be the culprit
If users don't know how to interact with the technology (however easy it may seem), then the experiment misses out on what would happen if participants had basic knowledge LLMs
So psyched to start out with such amazing scholars who are also tons of fun and quite good at beach style spikeball
www.kellogg.northwestern.edu/news/blog/20...
www.kellogg.northwestern.edu/news/blog/20...

New academic year, new faculty perspectives
Get to know the newest professors at Kellogg! Hear what’s inspiring them this fall as they step into the classroom.
www.kellogg.northwestern.edu
October 19, 2023 at 9:10 PM
So psyched to start out with such amazing scholars who are also tons of fun and quite good at beach style spikeball
www.kellogg.northwestern.edu/news/blog/20...
www.kellogg.northwestern.edu/news/blog/20...