



Aditya Chetan
@justachetan.bsky.social
PhD Student at Cornell. Working in Vision and Graphics. justachetan.github.io
Pinned
Aditya Chetan
@justachetan.bsky.social
· Jun 10
Check out our poster at #CVPR2025 on accurate differential operators for hybrid neural fields (like Instant NGP)!
🗓️ Fri, June 13, 10:30 AM–12:30 PM
📍 ExHall D, Poster #34
🔗 justachetan.github.io/hnf-derivati...
👉 cvpr.thecvf.com/virtual/2025...
Details ⬇️ (1/n)
🗓️ Fri, June 13, 10:30 AM–12:30 PM
📍 ExHall D, Poster #34
🔗 justachetan.github.io/hnf-derivati...
👉 cvpr.thecvf.com/virtual/2025...
Details ⬇️ (1/n)

Thrilled to attend my first-ever #CVPR2025! 🎉
Please reach out if you would like to chat about neural fields, dynamic scenes, video understanding, or just generally about gaming, musicals, or ☕️
I will also be presenting our poster ⬇️ (Come visit!)
Please reach out if you would like to chat about neural fields, dynamic scenes, video understanding, or just generally about gaming, musicals, or ☕️
I will also be presenting our poster ⬇️ (Come visit!)
Reposted by Aditya Chetan

It’s grad school application season, and I wanted to give some public advice.
Caveats:
-*-*-*-*
> These are my opinions, based on my experiences, they are not secret tricks or guarantees
> They are general guidelines, not meant to cover a host of idiosyncrasies and special cases
Caveats:
-*-*-*-*
> These are my opinions, based on my experiences, they are not secret tricks or guarantees
> They are general guidelines, not meant to cover a host of idiosyncrasies and special cases
November 6, 2025 at 2:55 PM
It’s grad school application season, and I wanted to give some public advice.
Caveats:
-*-*-*-*
> These are my opinions, based on my experiences, they are not secret tricks or guarantees
> They are general guidelines, not meant to cover a host of idiosyncrasies and special cases
Caveats:
-*-*-*-*
> These are my opinions, based on my experiences, they are not secret tricks or guarantees
> They are general guidelines, not meant to cover a host of idiosyncrasies and special cases
Reposted by Aditya Chetan

We are trying to create a list of in-copyright novels that contain maps. If you know of some, drop them in the thread below! 🧵👇
August 28, 2025 at 2:49 PM
We are trying to create a list of in-copyright novels that contain maps. If you know of some, drop them in the thread below! 🧵👇
Reposted by Aditya Chetan

For those at CVPR, @justachetan.bsky.social will be presenting this poster tomorrow at 10:30 (Exhibit hall D, Poster #34). Come hear about why neural field derivatives are noisy, and how we resurrect image processing ideas for neural fields!
Check out our poster at #CVPR2025 on accurate differential operators for hybrid neural fields (like Instant NGP)!
🗓️ Fri, June 13, 10:30 AM–12:30 PM
📍 ExHall D, Poster #34
🔗 justachetan.github.io/hnf-derivati...
👉 cvpr.thecvf.com/virtual/2025...
Details ⬇️ (1/n)
🗓️ Fri, June 13, 10:30 AM–12:30 PM
📍 ExHall D, Poster #34
🔗 justachetan.github.io/hnf-derivati...
👉 cvpr.thecvf.com/virtual/2025...
Details ⬇️ (1/n)
June 12, 2025 at 9:36 PM
For those at CVPR, @justachetan.bsky.social will be presenting this poster tomorrow at 10:30 (Exhibit hall D, Poster #34). Come hear about why neural field derivatives are noisy, and how we resurrect image processing ideas for neural fields!
Thrilled to attend my first-ever #CVPR2025! 🎉
Please reach out if you would like to chat about neural fields, dynamic scenes, video understanding, or just generally about gaming, musicals, or ☕️
I will also be presenting our poster ⬇️ (Come visit!)
Please reach out if you would like to chat about neural fields, dynamic scenes, video understanding, or just generally about gaming, musicals, or ☕️
I will also be presenting our poster ⬇️ (Come visit!)
Check out our poster at #CVPR2025 on accurate differential operators for hybrid neural fields (like Instant NGP)!
🗓️ Fri, June 13, 10:30 AM–12:30 PM
📍 ExHall D, Poster #34
🔗 justachetan.github.io/hnf-derivati...
👉 cvpr.thecvf.com/virtual/2025...
Details ⬇️ (1/n)
🗓️ Fri, June 13, 10:30 AM–12:30 PM
📍 ExHall D, Poster #34
🔗 justachetan.github.io/hnf-derivati...
👉 cvpr.thecvf.com/virtual/2025...
Details ⬇️ (1/n)
June 10, 2025 at 2:12 PM
Thrilled to attend my first-ever #CVPR2025! 🎉
Please reach out if you would like to chat about neural fields, dynamic scenes, video understanding, or just generally about gaming, musicals, or ☕️
I will also be presenting our poster ⬇️ (Come visit!)
Please reach out if you would like to chat about neural fields, dynamic scenes, video understanding, or just generally about gaming, musicals, or ☕️
I will also be presenting our poster ⬇️ (Come visit!)
Check out our poster at #CVPR2025 on accurate differential operators for hybrid neural fields (like Instant NGP)!
🗓️ Fri, June 13, 10:30 AM–12:30 PM
📍 ExHall D, Poster #34
🔗 justachetan.github.io/hnf-derivati...
👉 cvpr.thecvf.com/virtual/2025...
Details ⬇️ (1/n)
🗓️ Fri, June 13, 10:30 AM–12:30 PM
📍 ExHall D, Poster #34
🔗 justachetan.github.io/hnf-derivati...
👉 cvpr.thecvf.com/virtual/2025...
Details ⬇️ (1/n)
June 10, 2025 at 2:11 PM
Check out our poster at #CVPR2025 on accurate differential operators for hybrid neural fields (like Instant NGP)!
🗓️ Fri, June 13, 10:30 AM–12:30 PM
📍 ExHall D, Poster #34
🔗 justachetan.github.io/hnf-derivati...
👉 cvpr.thecvf.com/virtual/2025...
Details ⬇️ (1/n)
🗓️ Fri, June 13, 10:30 AM–12:30 PM
📍 ExHall D, Poster #34
🔗 justachetan.github.io/hnf-derivati...
👉 cvpr.thecvf.com/virtual/2025...
Details ⬇️ (1/n)
Reposted by Aditya Chetan

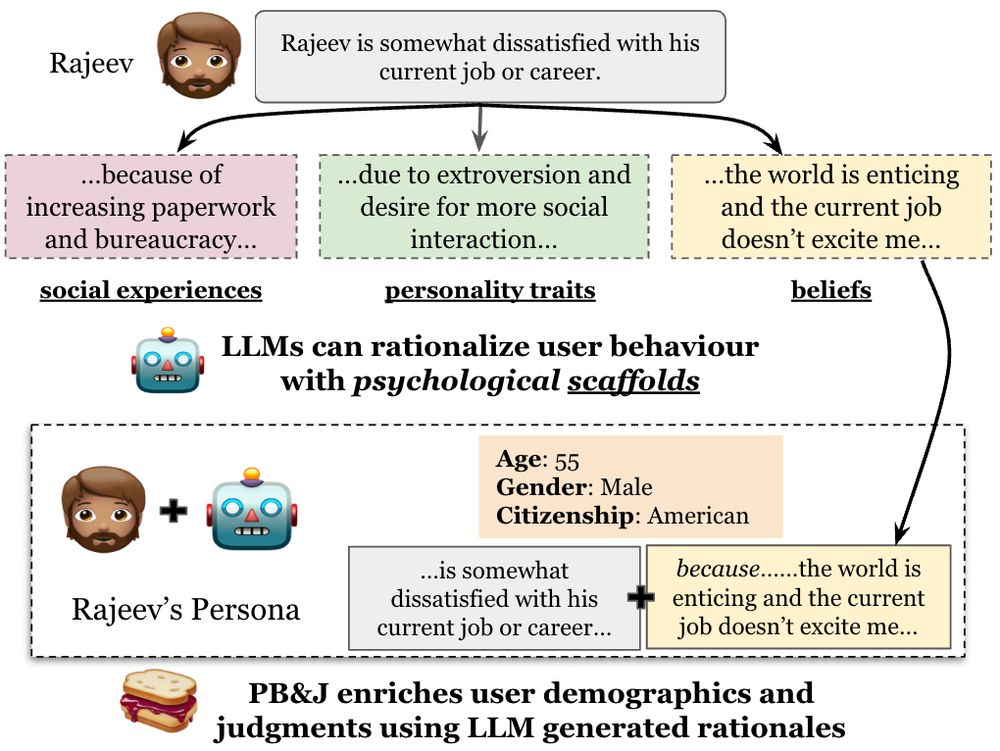
Reasoning about the "why" behind user behavior can improve LLM personas! ✨🧠📈
📝Excited to share our new work: Improving LLM Personas via Rationalization with Psychological Scaffolds
🔗 arxiv.org/abs/2504.17993
🧵 (1/n)
📝Excited to share our new work: Improving LLM Personas via Rationalization with Psychological Scaffolds
🔗 arxiv.org/abs/2504.17993
🧵 (1/n)
April 29, 2025 at 1:05 AM
Reasoning about the "why" behind user behavior can improve LLM personas! ✨🧠📈
📝Excited to share our new work: Improving LLM Personas via Rationalization with Psychological Scaffolds
🔗 arxiv.org/abs/2504.17993
🧵 (1/n)
📝Excited to share our new work: Improving LLM Personas via Rationalization with Psychological Scaffolds
🔗 arxiv.org/abs/2504.17993
🧵 (1/n)
Reposted by Aditya Chetan

[1/10] Is scene understanding solved?
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io

March 29, 2025 at 7:36 PM
[1/10] Is scene understanding solved?
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Reposted by Aditya Chetan

Introducing MegaSaM!
Accurate, fast, & robust structure + camera estimation from casual monocular videos of dynamic scenes!
MegaSaM outputs camera parameters and consistent video depth, scaling to long videos with unconstrained camera paths and complex scene dynamics!
Accurate, fast, & robust structure + camera estimation from casual monocular videos of dynamic scenes!
MegaSaM outputs camera parameters and consistent video depth, scaling to long videos with unconstrained camera paths and complex scene dynamics!
December 6, 2024 at 5:43 PM
Introducing MegaSaM!
Accurate, fast, & robust structure + camera estimation from casual monocular videos of dynamic scenes!
MegaSaM outputs camera parameters and consistent video depth, scaling to long videos with unconstrained camera paths and complex scene dynamics!
Accurate, fast, & robust structure + camera estimation from casual monocular videos of dynamic scenes!
MegaSaM outputs camera parameters and consistent video depth, scaling to long videos with unconstrained camera paths and complex scene dynamics!