




James Steele
@jamessteeleii.bsky.social
I'm just a guy who's an academic for fun
Pinned
James Steele
@jamessteeleii.bsky.social
· Sep 30

Excited to have now started new role as Head of Research with Macrofactor (macrofactorapp.com). Looking forward to getting stuck into some really cool projects and getting that out to all the users!
This is the sort of thing I want to be reading in journal submission guidelines... don't make me put the important details in the supplemental materials.

November 27, 2025 at 9:19 AM
This is the sort of thing I want to be reading in journal submission guidelines... don't make me put the important details in the supplemental materials.
Reposted by James Steele

I don't know how I've missed it because it's *right on the documentation home page*, but if you use {glue} for nice string interpolation in #rstats and you have {stringr} loaded (likely through the tidyverse), you can use str_glue() instead of glue::glue() or loading library(glue) glue.tidyverse.org

November 25, 2025 at 6:00 PM
I don't know how I've missed it because it's *right on the documentation home page*, but if you use {glue} for nice string interpolation in #rstats and you have {stringr} loaded (likely through the tidyverse), you can use str_glue() instead of glue::glue() or loading library(glue) glue.tidyverse.org
A month later and I am still thinking about it...

米津玄師,宇多田ヒカル「JANE DOE」×『チェンソーマン レゼ篇』MV/KenshiYonezu,HikaruUtada-JANE DOE×ChainsawMan–TheMovie:RezeArc
YouTube video by Kenshi Yonezu 米津玄師
youtu.be
November 25, 2025 at 10:51 AM
A month later and I am still thinking about it...
Reposted by James Steele

🚨 New working paper!
How well do people predict the results of studies?
@sdellavi.bsky.social and I leverage data from the first 100 studies to have been posted on the SSPP, containing 1,482 key questions, on which over 50,000 forecasts were placed. Some surprising results below.... 🧵👇
How well do people predict the results of studies?
@sdellavi.bsky.social and I leverage data from the first 100 studies to have been posted on the SSPP, containing 1,482 key questions, on which over 50,000 forecasts were placed. Some surprising results below.... 🧵👇

November 24, 2025 at 3:43 PM
🚨 New working paper!
How well do people predict the results of studies?
@sdellavi.bsky.social and I leverage data from the first 100 studies to have been posted on the SSPP, containing 1,482 key questions, on which over 50,000 forecasts were placed. Some surprising results below.... 🧵👇
How well do people predict the results of studies?
@sdellavi.bsky.social and I leverage data from the first 100 studies to have been posted on the SSPP, containing 1,482 key questions, on which over 50,000 forecasts were placed. Some surprising results below.... 🧵👇
Here's a presentation tip and something I've started doing recently 👇🏻
November 22, 2025 at 11:26 AM
Here's a presentation tip and something I've started doing recently 👇🏻
PSA: Observed outcomes after an intervention vary and this does not necessarily mean there is interindividual heterogeneity in the underlying causal effect of the intervention. Further, finding predictors of observed outcomes does not mean you have found predictors of any underlying causal effects.
November 19, 2025 at 4:40 PM
PSA: Observed outcomes after an intervention vary and this does not necessarily mean there is interindividual heterogeneity in the underlying causal effect of the intervention. Further, finding predictors of observed outcomes does not mean you have found predictors of any underlying causal effects.
Reposted by James Steele

There's got to be SOME hypothesis that makes our experiment useless. THINK!
COMIC ◆ www.smbc-comics.com/comic/stats-3
PATREON ◆ www.patreon.com/ZachWeinersm...
STORE ◆ smbc-store.myshopify.com
COMIC ◆ www.smbc-comics.com/comic/stats-3
PATREON ◆ www.patreon.com/ZachWeinersm...
STORE ◆ smbc-store.myshopify.com

November 18, 2025 at 11:30 PM
There's got to be SOME hypothesis that makes our experiment useless. THINK!
COMIC ◆ www.smbc-comics.com/comic/stats-3
PATREON ◆ www.patreon.com/ZachWeinersm...
STORE ◆ smbc-store.myshopify.com
COMIC ◆ www.smbc-comics.com/comic/stats-3
PATREON ◆ www.patreon.com/ZachWeinersm...
STORE ◆ smbc-store.myshopify.com
Reposted by James Steele

1. Ran Tian: Statistical Practice in Sport and Exercise Science: A Meta-Research Study.
We studied 146 studies. Most used multilevel models or t-tests/correlations/ANOVA. In 27% the wrong methods were used (statistical test did not match data structure). Collaborate with a statistician!
#AIMOS2025
We studied 146 studies. Most used multilevel models or t-tests/correlations/ANOVA. In 27% the wrong methods were used (statistical test did not match data structure). Collaborate with a statistician!
#AIMOS2025

November 19, 2025 at 3:07 AM
1. Ran Tian: Statistical Practice in Sport and Exercise Science: A Meta-Research Study.
We studied 146 studies. Most used multilevel models or t-tests/correlations/ANOVA. In 27% the wrong methods were used (statistical test did not match data structure). Collaborate with a statistician!
#AIMOS2025
We studied 146 studies. Most used multilevel models or t-tests/correlations/ANOVA. In 27% the wrong methods were used (statistical test did not match data structure). Collaborate with a statistician!
#AIMOS2025
Always check your priors on the scale with which you intend to interpret things folks!

The default prior for the intercept in both {rstanarm} and {brms} are very wide.
Counterintuitively - being on the logit scale, this is actually translates to a **strong** prior that p(y=1) is near 1 or near 0.
Always check your priors!
#rstats
Counterintuitively - being on the logit scale, this is actually translates to a **strong** prior that p(y=1) is near 1 or near 0.
Always check your priors!
#rstats


November 18, 2025 at 2:13 PM
Always check your priors on the scale with which you intend to interpret things folks!
Finland bound to preach the gospel of The Black Pill and myth of intervention effect heterogeneity 😁

Inter-Individual Variation in Resistance Training Responses
Welcome to the INTER-INDIVIDUAL VARIATION IN RESISTANCE TRAINING RESPONSES Conference 19th November - 21st November 2025 at University of Jyväskylä!
www.jyu.fi
November 17, 2025 at 8:44 PM
Finland bound to preach the gospel of The Black Pill and myth of intervention effect heterogeneity 😁
Reposted by James Steele
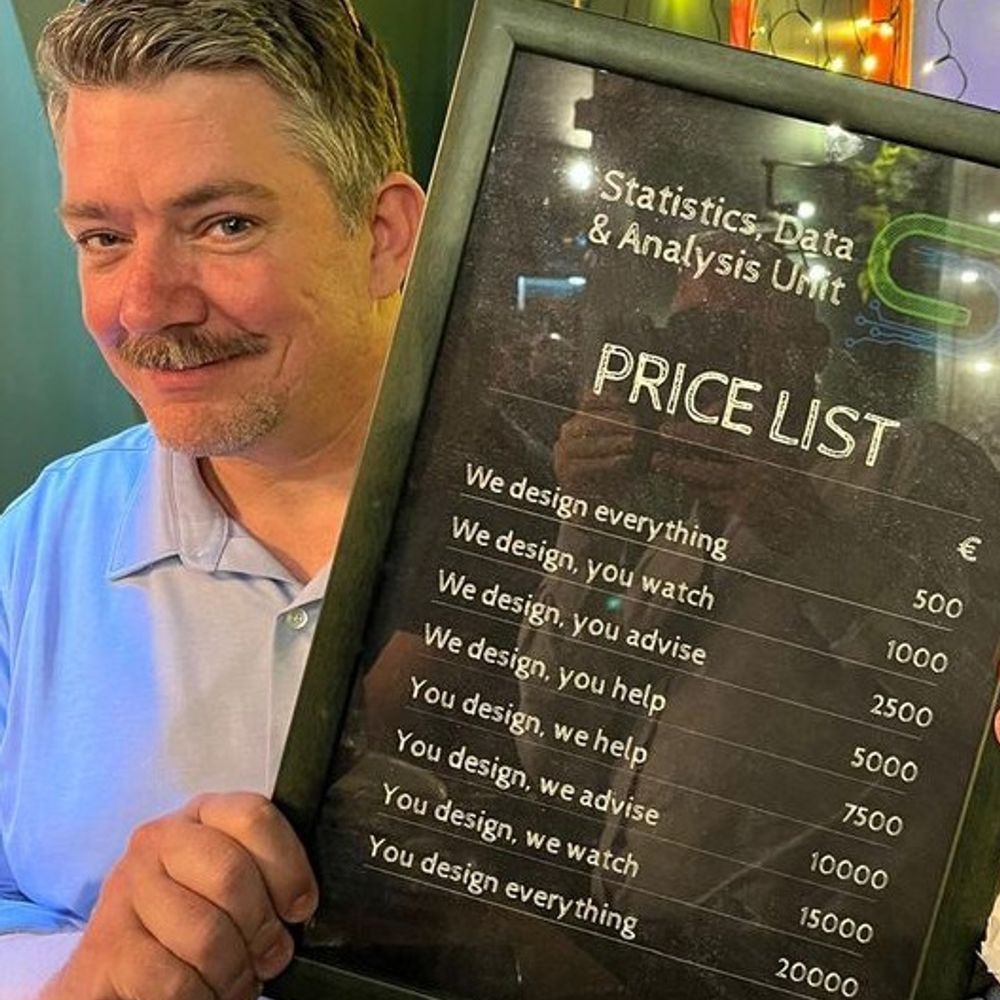
Confusing stats language:
The "linear" is linear regression means "linear in the parameters".
It does not mean "can only fit straight lines", and things like polynomials and splines can be included in linear models.
online.stat.psu.edu/stat501/less...
1/2
The "linear" is linear regression means "linear in the parameters".
It does not mean "can only fit straight lines", and things like polynomials and splines can be included in linear models.
online.stat.psu.edu/stat501/less...
1/2

November 14, 2025 at 9:08 AM
Confusing stats language:
The "linear" is linear regression means "linear in the parameters".
It does not mean "can only fit straight lines", and things like polynomials and splines can be included in linear models.
online.stat.psu.edu/stat501/less...
1/2
The "linear" is linear regression means "linear in the parameters".
It does not mean "can only fit straight lines", and things like polynomials and splines can be included in linear models.
online.stat.psu.edu/stat501/less...
1/2
Reposted by James Steele

Two-group pre/post data are deceptively simple, and you could analyze them in many different ways, depending on your goals. Here are three blog posts on the topic:
solomonkurz.netlify.app/blog/2022-06...
solomonkurz.netlify.app/blog/2020-12...
solomonkurz.netlify.app/blog/2023-06...
solomonkurz.netlify.app/blog/2022-06...
solomonkurz.netlify.app/blog/2020-12...
solomonkurz.netlify.app/blog/2023-06...
November 10, 2025 at 7:19 PM
Two-group pre/post data are deceptively simple, and you could analyze them in many different ways, depending on your goals. Here are three blog posts on the topic:
solomonkurz.netlify.app/blog/2022-06...
solomonkurz.netlify.app/blog/2020-12...
solomonkurz.netlify.app/blog/2023-06...
solomonkurz.netlify.app/blog/2022-06...
solomonkurz.netlify.app/blog/2020-12...
solomonkurz.netlify.app/blog/2023-06...
Goddamit, my stiches itch... wait a minute! St-itch-es 🤔
November 10, 2025 at 8:44 AM
Goddamit, my stiches itch... wait a minute! St-itch-es 🤔
Anyone have a copy of the following (pic because citation too long for character limit, also see alt text).

November 10, 2025 at 8:38 AM
Anyone have a copy of the following (pic because citation too long for character limit, also see alt text).
I've made the decision to step down from all editorial positions at journals. Mostly due to shifting personal and professional situation, priorities, and wanting to avoid the psychological burden of obligation such formal roles tend to bring me...
November 9, 2025 at 2:06 PM
I've made the decision to step down from all editorial positions at journals. Mostly due to shifting personal and professional situation, priorities, and wanting to avoid the psychological burden of obligation such formal roles tend to bring me...
Reposted by James Steele

New 'Preliminary Report' submission format at Science and Medicine in Football. An idea that should be interesting for other journals! Explicitly make space for honestly reported smaller sample-size studies www.tandfonline.com/doi/full/10....

November 6, 2025 at 2:40 PM
New 'Preliminary Report' submission format at Science and Medicine in Football. An idea that should be interesting for other journals! Explicitly make space for honestly reported smaller sample-size studies www.tandfonline.com/doi/full/10....
Ah man, just got reminded about that methods paper on Item Response Theory for measurement of sporting abilities that I had on my to do list to write a few years back and never got round to.
We did some initial work with Elite Skills Arena and presented the results at the BASES conference in 2022.
We did some initial work with Elite Skills Arena and presented the results at the BASES conference in 2022.

(PDF) Measurement of sporting abilities using item response theory: an introduction and example using passing ability in soccer
PDF | Measurement of performance in sport has historically followed operationist tendencies and applications of Classical Test Theory (i.e., true score... | Find, read and cite all the research you ne...
doi.org
November 5, 2025 at 11:12 AM
Ah man, just got reminded about that methods paper on Item Response Theory for measurement of sporting abilities that I had on my to do list to write a few years back and never got round to.
We did some initial work with Elite Skills Arena and presented the results at the BASES conference in 2022.
We did some initial work with Elite Skills Arena and presented the results at the BASES conference in 2022.
Honestly, the film was soo good... watched twice in the cinema and if it was still on here in the UK I would go watch again in a heartbeat #chainsawman #rezearc

劇場版『チェンソーマン レゼ篇』オープニングムービー 主題歌:米津玄師「IRIS OUT」“Chainsaw Man – The Movie: Reze Arc” – Opening Movie
YouTube video by Kenshi Yonezu 米津玄師
www.youtube.com
November 4, 2025 at 2:03 PM
Honestly, the film was soo good... watched twice in the cinema and if it was still on here in the UK I would go watch again in a heartbeat #chainsawman #rezearc
Reposted by James Steele

The package formerly known as papercheck has changed its name to metacheck! We're checking more than just papers, with functions to assess OSF projects, github repos, and AsPredicted pre-registrations, with more being developed all the time.
scienceverse.github.io/metacheck/
scienceverse.github.io/metacheck/

Check Research Outputs for Best Practices
A modular, extendable system for automatically checking research outputs for best practices using text search, R code, and/or (optional) LLM queries.
scienceverse.github.io
November 3, 2025 at 4:20 PM
The package formerly known as papercheck has changed its name to metacheck! We're checking more than just papers, with functions to assess OSF projects, github repos, and AsPredicted pre-registrations, with more being developed all the time.
scienceverse.github.io/metacheck/
scienceverse.github.io/metacheck/
My old role at Kieser Australia has now been advertised.
employmenthero.com/jobs/positio...
employmenthero.com/jobs/positio...

Head Of Research
Head Office (NCS) • South Melbourne, Victoria 3205, Australia • Full-time. Apply now and secure your next job today!
employmenthero.com
November 2, 2025 at 3:37 PM
My old role at Kieser Australia has now been advertised.
employmenthero.com/jobs/positio...
employmenthero.com/jobs/positio...
Reposted by James Steele

How to ensure your research data is error-free & understandable by other users & your future self?🗂️ This tutorial by LMU OSC is on documenting & validating data in R to make it more reusable.
Self-Paced Tutorial of the Day: Data Documentation & Validation using R📑 lmu-osc.github.io/data-documen...
Self-Paced Tutorial of the Day: Data Documentation & Validation using R📑 lmu-osc.github.io/data-documen...
lmu-osc.github.io
October 31, 2025 at 11:00 AM
How to ensure your research data is error-free & understandable by other users & your future self?🗂️ This tutorial by LMU OSC is on documenting & validating data in R to make it more reusable.
Self-Paced Tutorial of the Day: Data Documentation & Validation using R📑 lmu-osc.github.io/data-documen...
Self-Paced Tutorial of the Day: Data Documentation & Validation using R📑 lmu-osc.github.io/data-documen...
Reposted by James Steele

There still seems to be a lot of confusion about significance testing in psych. No, p-values *don’t* become useless at large N. This flawed point also used to be framed as "too much power". But power isn't the problem – it's 1) unbalanced error rates and 2) the (lack of a) SESOI. 1/ >

But here's, the thing, p values and significance become useless at such large sample sizes. When you're dividing the coefficient by the SE and the sample size is in the tens of thousands, EVERYTHING IS SIGNIFICANT. All you're testing is whether the coefficient is different than zero.
October 31, 2025 at 8:13 AM
There still seems to be a lot of confusion about significance testing in psych. No, p-values *don’t* become useless at large N. This flawed point also used to be framed as "too much power". But power isn't the problem – it's 1) unbalanced error rates and 2) the (lack of a) SESOI. 1/ >
Reposted by James Steele

New Commentary published in the German Journal for Sport and Exercise Research, emphasizing not only the need to specify a SESOI when testing a claim, but recommending also to start a discussion about best practices to determine a SESOI
link.springer.com/article/10.1...

From best practices to severe testing: A methodological response to Büsch and Loffing (2024) - German Journal of Exercise and Sport Research
This commentary builds on the Büsch and Loffing (2024) exploration of methodological best practices for validly evaluating intervention studies. Extending their perspective, it is argued that research...
link.springer.com
October 30, 2025 at 9:43 PM
New Commentary published in the German Journal for Sport and Exercise Research, emphasizing not only the need to specify a SESOI when testing a claim, but recommending also to start a discussion about best practices to determine a SESOI
link.springer.com/article/10.1...
Reposted by James Steele

Which reminds me of this old classic on the Noise Miners.
“'Noise mining is a funny thing,' he said. 'When you first see a bit of noise, it doesn’t look so impressive. But as you work it out of the rock, it gets more and more refined.' This process, he explained, is called 'shucking.'"
“'Noise mining is a funny thing,' he said. 'When you first see a bit of noise, it doesn’t look so impressive. But as you work it out of the rock, it gets more and more refined.' This process, he explained, is called 'shucking.'"
October 30, 2025 at 9:24 AM
Which reminds me of this old classic on the Noise Miners.
“'Noise mining is a funny thing,' he said. 'When you first see a bit of noise, it doesn’t look so impressive. But as you work it out of the rock, it gets more and more refined.' This process, he explained, is called 'shucking.'"
“'Noise mining is a funny thing,' he said. 'When you first see a bit of noise, it doesn’t look so impressive. But as you work it out of the rock, it gets more and more refined.' This process, he explained, is called 'shucking.'"
Note to folks getting into meta-analysis... when extracting data from studies extract it EXACTLY as reported by the authors. Don't do any calculations outside of analysis scripts. This means have a column for units, mean/median/SD/SE/IQR/lower range/upper range or whatever else you might need...
October 29, 2025 at 4:13 PM
Note to folks getting into meta-analysis... when extracting data from studies extract it EXACTLY as reported by the authors. Don't do any calculations outside of analysis scripts. This means have a column for units, mean/median/SD/SE/IQR/lower range/upper range or whatever else you might need...