




Davide Paglieri
@dpaglieri.bsky.social
PhD Student at UCL.
Previously AI Research Engineer at Bending Spoons
Previously AI Research Engineer at Bending Spoons
🚨This week's new entry on balrogai.com is Microsoft Phi-4 (14B model)
While Phi-4 excels on benchmarks like math competitions, BALROG reveals that Phi-4 falls short as an agent. More research on how to improve agentic performance is needed.
While Phi-4 excels on benchmarks like math competitions, BALROG reveals that Phi-4 falls short as an agent. More research on how to improve agentic performance is needed.

January 16, 2025 at 11:30 AM
🚨This week's new entry on balrogai.com is Microsoft Phi-4 (14B model)
While Phi-4 excels on benchmarks like math competitions, BALROG reveals that Phi-4 falls short as an agent. More research on how to improve agentic performance is needed.
While Phi-4 excels on benchmarks like math competitions, BALROG reveals that Phi-4 falls short as an agent. More research on how to improve agentic performance is needed.
🚨BALROG leaderboard update
This week's new entries on balrogai.com are:
Llama 3.3 70B Instruct 🫤
Claude 3.5 Haiku✨
Mistral-Nemo-it (12B) 🆗
Github: github.com/balrog-ai/BA...
This week's new entries on balrogai.com are:
Llama 3.3 70B Instruct 🫤
Claude 3.5 Haiku✨
Mistral-Nemo-it (12B) 🆗
Github: github.com/balrog-ai/BA...

December 12, 2024 at 11:30 AM
🚨BALROG leaderboard update
This week's new entries on balrogai.com are:
Llama 3.3 70B Instruct 🫤
Claude 3.5 Haiku✨
Mistral-Nemo-it (12B) 🆗
Github: github.com/balrog-ai/BA...
This week's new entries on balrogai.com are:
Llama 3.3 70B Instruct 🫤
Claude 3.5 Haiku✨
Mistral-Nemo-it (12B) 🆗
Github: github.com/balrog-ai/BA...
Reposted by Davide Paglieri

I'm excited to share a new paper: "Mastering Board Games by External and Internal Planning with Language Models"
storage.googleapis.com/deepmind-med...
(also soon to be up on Arxiv, once it's been processed there)
storage.googleapis.com/deepmind-med...
(also soon to be up on Arxiv, once it's been processed there)
storage.googleapis.com
December 5, 2024 at 7:49 AM
I'm excited to share a new paper: "Mastering Board Games by External and Internal Planning with Language Models"
storage.googleapis.com/deepmind-med...
(also soon to be up on Arxiv, once it's been processed there)
storage.googleapis.com/deepmind-med...
(also soon to be up on Arxiv, once it's been processed there)
Reposted by Davide Paglieri

Introducing 🧞Genie 2 🧞 - our most capable large-scale foundation world model, which can generate a diverse array of consistent worlds, playable for up to a minute. We believe Genie 2 could unlock the next wave of capabilities for embodied agents 🧠.
December 4, 2024 at 4:01 PM
Introducing 🧞Genie 2 🧞 - our most capable large-scale foundation world model, which can generate a diverse array of consistent worlds, playable for up to a minute. We believe Genie 2 could unlock the next wave of capabilities for embodied agents 🧠.
It's great to see BALROG featured on Jack Clark's Import AI newsletter!
Check out what he had to say about it here:
jack-clark.net
And check out BALROG's leaderboard on balrogai.com
Check out what he had to say about it here:
jack-clark.net
And check out BALROG's leaderboard on balrogai.com

December 4, 2024 at 9:37 AM
It's great to see BALROG featured on Jack Clark's Import AI newsletter!
Check out what he had to say about it here:
jack-clark.net
And check out BALROG's leaderboard on balrogai.com
Check out what he had to say about it here:
jack-clark.net
And check out BALROG's leaderboard on balrogai.com
Reposted by Davide Paglieri

Do you know what rating you’ll give after reading the intro? Are your confidence scores 4 or higher? Do you not respond in rebuttal phases? Are you worried how it will look if your rating is the only 8 among 3’s? This thread is for you.
November 27, 2024 at 5:25 PM
Do you know what rating you’ll give after reading the intro? Are your confidence scores 4 or higher? Do you not respond in rebuttal phases? Are you worried how it will look if your rating is the only 8 among 3’s? This thread is for you.
Reposted by Davide Paglieri

Excited to announce "BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games" led b UCL DARK's @dpaglieri.bsky.social! Douwe Kiela plot below is maybe the scariest for AI progress — LLM benchmarks are saturating at an accelerating rate. BALROG to the rescue. This will keep us busy for years.

November 22, 2024 at 11:27 AM
Excited to announce "BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games" led b UCL DARK's @dpaglieri.bsky.social! Douwe Kiela plot below is maybe the scariest for AI progress — LLM benchmarks are saturating at an accelerating rate. BALROG to the rescue. This will keep us busy for years.
Reposted by Davide Paglieri

This may sound odd, but game-based benchmarks are some of the most useful for AI, since we have human scores and they require reasoning, planning & vision
The hardest of all is Nethack. No AI is close, and I suspect that an AI that can fairly win/ascend would need to be AGI-ish. Paper: balrogai.com
The hardest of all is Nethack. No AI is close, and I suspect that an AI that can fairly win/ascend would need to be AGI-ish. Paper: balrogai.com
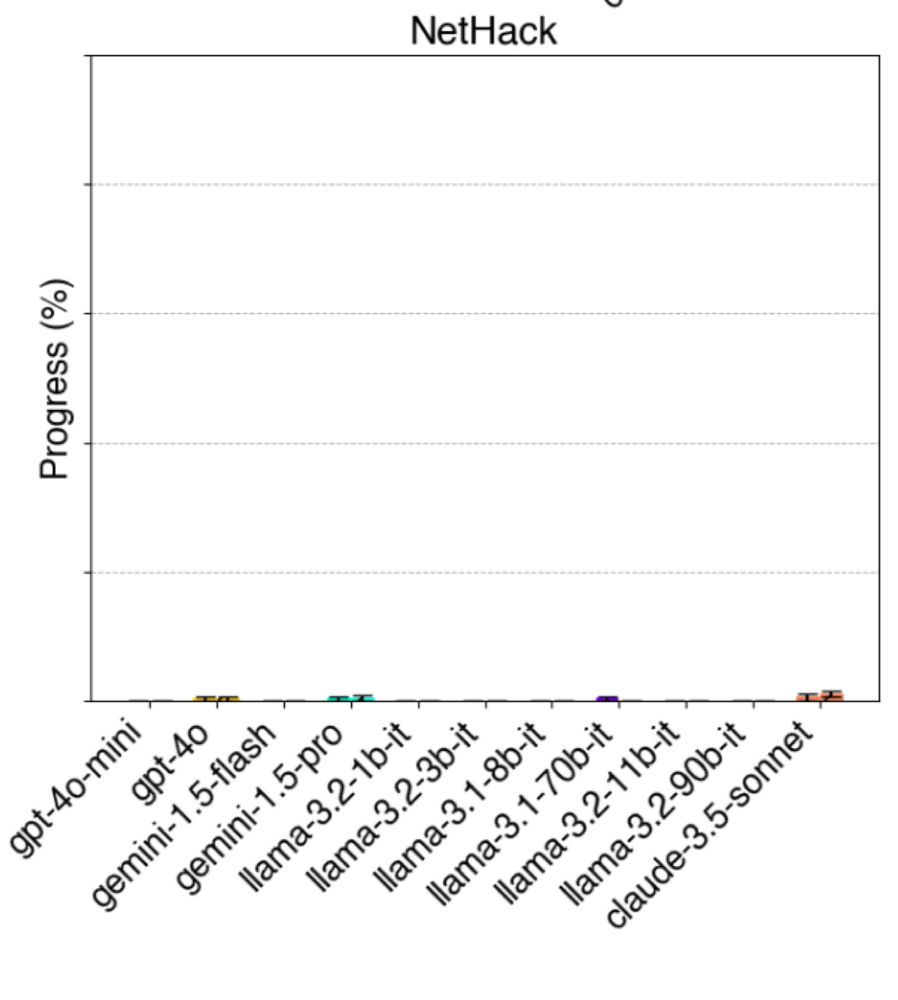


November 23, 2024 at 4:32 AM
This may sound odd, but game-based benchmarks are some of the most useful for AI, since we have human scores and they require reasoning, planning & vision
The hardest of all is Nethack. No AI is close, and I suspect that an AI that can fairly win/ascend would need to be AGI-ish. Paper: balrogai.com
The hardest of all is Nethack. No AI is close, and I suspect that an AI that can fairly win/ascend would need to be AGI-ish. Paper: balrogai.com
Reposted by Davide Paglieri

Your LLM shall not pass! 🧙♂️
... unless it's really good in reasoning and games!
Check out this new amazing benchmark BALROG 👾 from @dpaglieri.bsky.social and team 👇
... unless it's really good in reasoning and games!
Check out this new amazing benchmark BALROG 👾 from @dpaglieri.bsky.social and team 👇
Tired of saturated benchmarks? Want scope for a significant leap in capabilities?
🔥 Introducing BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games!
BALROG is a challenging benchmark for LLM agentic capabilities, designed to stay relevant for years to come.
1/🧵
🔥 Introducing BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games!
BALROG is a challenging benchmark for LLM agentic capabilities, designed to stay relevant for years to come.
1/🧵

November 21, 2024 at 4:47 PM
Your LLM shall not pass! 🧙♂️
... unless it's really good in reasoning and games!
Check out this new amazing benchmark BALROG 👾 from @dpaglieri.bsky.social and team 👇
... unless it's really good in reasoning and games!
Check out this new amazing benchmark BALROG 👾 from @dpaglieri.bsky.social and team 👇
Tired of saturated benchmarks? Want scope for a significant leap in capabilities?
🔥 Introducing BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games!
BALROG is a challenging benchmark for LLM agentic capabilities, designed to stay relevant for years to come.
1/🧵
🔥 Introducing BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games!
BALROG is a challenging benchmark for LLM agentic capabilities, designed to stay relevant for years to come.
1/🧵
November 21, 2024 at 4:24 PM
Tired of saturated benchmarks? Want scope for a significant leap in capabilities?
🔥 Introducing BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games!
BALROG is a challenging benchmark for LLM agentic capabilities, designed to stay relevant for years to come.
1/🧵
🔥 Introducing BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games!
BALROG is a challenging benchmark for LLM agentic capabilities, designed to stay relevant for years to come.
1/🧵