


Craig Sherstan
@craigsherstan.bsky.social
18 followers
3 following
13 posts
AI Research Scientist - Reinforcement Learning.
Tokyo based.
Posts
Media
Videos
Starter Packs
Reposted by Craig Sherstan

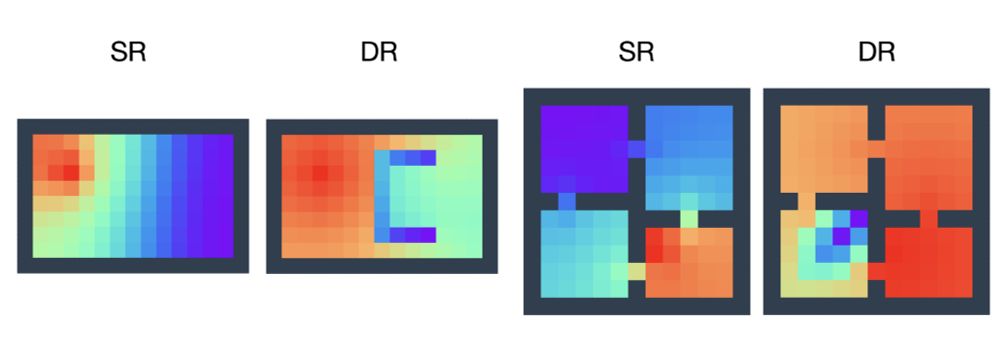
📢 I'm happy to share the preprint: _Reward-Aware Proto-Representations in Reinforcement Learning_ ‼️
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
Reposted by Craig Sherstan

James MacGlashan
@jmac-ai.bsky.social
· Sep 9
Reposted by Craig Sherstan
James MacGlashan
@jmac-ai.bsky.social
· Sep 9

Senior AI Integration Engineer for Game AI
Sony AI America, a branch of Sony AI, is a remotely distributed organization spread across the U.S. and Canada. Sony AI is Sony’s new research organization pursuing the mission to use AI to unleash hu...
sonyglobal.wd1.myworkdayjobs.com
Reposted by Craig Sherstan


Craig Sherstan
@craigsherstan.bsky.social
· Aug 25
Reposted by Craig Sherstan
James MacGlashan
@jmac-ai.bsky.social
· Aug 25
Craig Sherstan
@craigsherstan.bsky.social
· Jul 31
Craig Sherstan
@craigsherstan.bsky.social
· Jul 13
Craig Sherstan
@craigsherstan.bsky.social
· Jul 11


Craig Sherstan
@craigsherstan.bsky.social
· Nov 25
DynaSaur: Large Language Agents Beyond Predefined Actions
Existing LLM agent systems typically select actions from a fixed and predefined set at every step. While this approach is effective in closed, narrowly-scoped environments, we argue that it presents t...
doi.org

Craig Sherstan
@craigsherstan.bsky.social
· Nov 24