



Chandler Smith
@chansmi.bsky.social
Multi-Agent Researcher at CAIF | applied research at IQT | Thinking about making MA systems go well
Reposted by Chandler Smith

Submitting a benchmark to
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
🚨 NeurIPS 2024 Spotlight
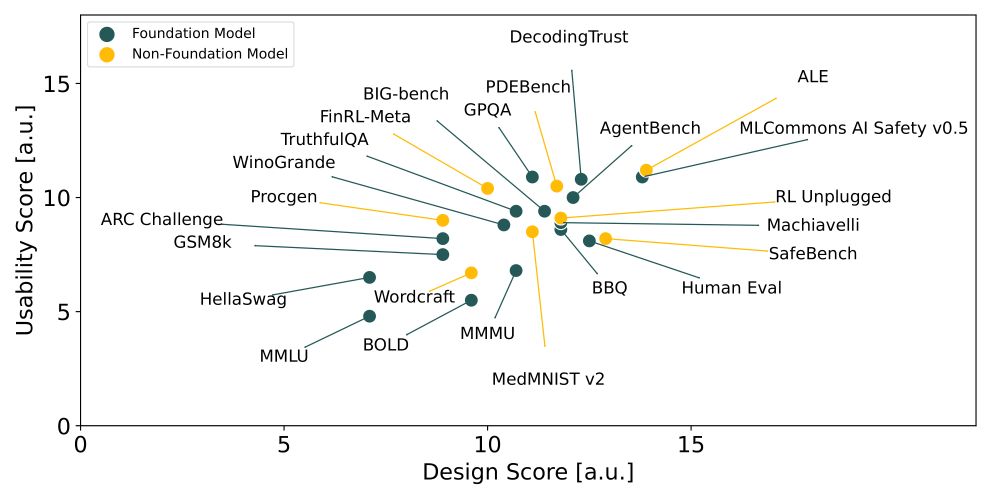
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
January 27, 2025 at 10:02 PM
Submitting a benchmark to
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
Reposted by Chandler Smith

The 2025 Cooperative AI summer school (9-13 July 2025 near London) is now accepting applications, due March 7th!
www.cooperativeai.com/summer-schoo...
www.cooperativeai.com/summer-schoo...
Cooperative AI
www.cooperativeai.com
January 9, 2025 at 7:25 PM
The 2025 Cooperative AI summer school (9-13 July 2025 near London) is now accepting applications, due March 7th!
www.cooperativeai.com/summer-schoo...
www.cooperativeai.com/summer-schoo...
Very excited to read this!

I have a draft of my introduction to cooperative multi-agent reinforcement learning on arxiv. Check it out and let me know any feedback you have. The plan is to polish and extend the material into a more comprehensive text with Frans Oliehoek.
arxiv.org/abs/2405.06161
arxiv.org/abs/2405.06161

A First Introduction to Cooperative Multi-Agent Reinforcement Learning
Multi-agent reinforcement learning (MARL) has exploded in popularity in recent years. While numerous approaches have been developed, they can be broadly categorized into three main types: centralized ...
arxiv.org
January 7, 2025 at 4:40 PM
Very excited to read this!
On my way to NeurIPS ‘24 ✈️ to present our Spotlight paper Betterbench and the Concordia Contest!
Would love to connect with folks and chat anything multi-agent, agentic AI, benchmarking, etc.
I am applying for fall ‘25 PhDs. Ping me if you have advice or there may be a fit!
Would love to connect with folks and chat anything multi-agent, agentic AI, benchmarking, etc.
I am applying for fall ‘25 PhDs. Ping me if you have advice or there may be a fit!
December 9, 2024 at 7:44 PM
On my way to NeurIPS ‘24 ✈️ to present our Spotlight paper Betterbench and the Concordia Contest!
Would love to connect with folks and chat anything multi-agent, agentic AI, benchmarking, etc.
I am applying for fall ‘25 PhDs. Ping me if you have advice or there may be a fit!
Would love to connect with folks and chat anything multi-agent, agentic AI, benchmarking, etc.
I am applying for fall ‘25 PhDs. Ping me if you have advice or there may be a fit!
🚀🚨 Excited to announce our work on Multi-Agent LLM Training!
MALT is a multi-agent configuration that leverages synthetic data generation and credit assignment strategies for post-training specialized models solving problems together
MALT is a multi-agent configuration that leverages synthetic data generation and credit assignment strategies for post-training specialized models solving problems together
December 6, 2024 at 10:38 PM
🚀🚨 Excited to announce our work on Multi-Agent LLM Training!
MALT is a multi-agent configuration that leverages synthetic data generation and credit assignment strategies for post-training specialized models solving problems together
MALT is a multi-agent configuration that leverages synthetic data generation and credit assignment strategies for post-training specialized models solving problems together
🚀 Check out our @neuripsconf.bsky.social Spotlight paper Betterbench, which outlines new standards in benchmarking AI! Delighted to have it featured in
@techreviewjp.bsky.social
@techreviewjp.bsky.social
Thrilled our NeurIPS Spotlight paper BetterBench is featured by MIT @technologyreview.com! 🎉
Article: bit.ly/3Zo1rgw
Paper: bit.ly/4eMSZfw
Website & Scores: betterbench.stanford.edu
Please share widely & join us in setting new standards for better AI benchmarking! ❤️
Article: bit.ly/3Zo1rgw
Paper: bit.ly/4eMSZfw
Website & Scores: betterbench.stanford.edu
Please share widely & join us in setting new standards for better AI benchmarking! ❤️

Many of the most popular benchmarks for AI models are outdated or poorly designed.
November 26, 2024 at 5:30 PM
🚀 Check out our @neuripsconf.bsky.social Spotlight paper Betterbench, which outlines new standards in benchmarking AI! Delighted to have it featured in
@techreviewjp.bsky.social
@techreviewjp.bsky.social
Reposted by Chandler Smith
🚨 NeurIPS 2024 Spotlight
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
November 25, 2024 at 7:02 PM
🚨 NeurIPS 2024 Spotlight
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x