

Georg Bökman
@bokmangeorg.bsky.social
930 followers
410 following
230 posts
Geometric deep learning + Computer vision
Posts
Media
Videos
Starter Packs
Reposted by Georg Bökman











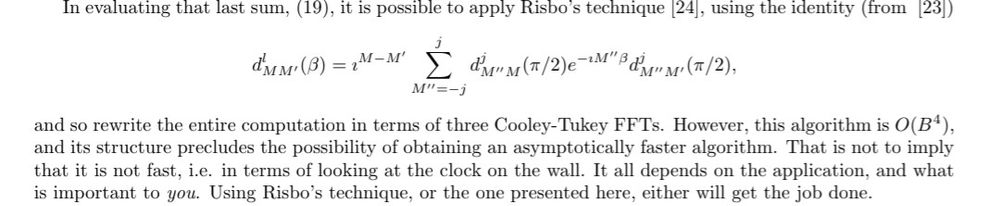


Reposted by Georg Bökman


A simple argument for equivariance at scale: 1) At scale, token-wise linear layers dominate compute. 2) Token-wise linear equivariant layers implemented in the Fourier domain are block-diagonal and hence fast.