



青龍聖者
@bdsqlsz.bsky.social
Hugging Face has just announced their storage plan.
25$/TB/month
They do not measure public datasets, only private datasets are calculated.
Deleted a 14TB outdated dataset, now it fits perfectly.
huggingface.co/docs/hub/sto...
25$/TB/month
They do not measure public datasets, only private datasets are calculated.
Deleted a 14TB outdated dataset, now it fits perfectly.
huggingface.co/docs/hub/sto...


December 11, 2024 at 6:19 AM
Hugging Face has just announced their storage plan.
25$/TB/month
They do not measure public datasets, only private datasets are calculated.
Deleted a 14TB outdated dataset, now it fits perfectly.
huggingface.co/docs/hub/sto...
25$/TB/month
They do not measure public datasets, only private datasets are calculated.
Deleted a 14TB outdated dataset, now it fits perfectly.
huggingface.co/docs/hub/sto...
Generative Photography:Scene-Consistent Camera Control for Realistic Text-to-Image Synthesis
generative-photography.github.io/project/
I am glad that I did not delete the ICC information of the images when I organized the dataset before...
generative-photography.github.io/project/
I am glad that I did not delete the ICC information of the images when I organized the dataset before...




December 10, 2024 at 6:19 PM
Generative Photography:Scene-Consistent Camera Control for Realistic Text-to-Image Synthesis
generative-photography.github.io/project/
I am glad that I did not delete the ICC information of the images when I organized the dataset before...
generative-photography.github.io/project/
I am glad that I did not delete the ICC information of the images when I organized the dataset before...
TRELLIS on windows, 16G VRAM need Auto install and Download Model.
I spent 2 hours compiling all the libraries needed for Windows and the one-click installation script.
github.com/sdbds/TRELLI...
I spent 2 hours compiling all the libraries needed for Windows and the one-click installation script.
github.com/sdbds/TRELLI...


December 10, 2024 at 6:18 PM
TRELLIS on windows, 16G VRAM need Auto install and Download Model.
I spent 2 hours compiling all the libraries needed for Windows and the one-click installation script.
github.com/sdbds/TRELLI...
I spent 2 hours compiling all the libraries needed for Windows and the one-click installation script.
github.com/sdbds/TRELLI...
Pixtral-large just became the current SOTA open source VLM.
Just processed 100K datasets captions with it (insert Danbooru tags)
Only took 24 hours and it's free.😁
I want to complete the captions of all 210K datasets today.
Just processed 100K datasets captions with it (insert Danbooru tags)
Only took 24 hours and it's free.😁
I want to complete the captions of all 210K datasets today.


December 4, 2024 at 4:28 PM
Pixtral-large just became the current SOTA open source VLM.
Just processed 100K datasets captions with it (insert Danbooru tags)
Only took 24 hours and it's free.😁
I want to complete the captions of all 210K datasets today.
Just processed 100K datasets captions with it (insert Danbooru tags)
Only took 24 hours and it's free.😁
I want to complete the captions of all 210K datasets today.
Tencent open source 13B HuanYuanVideo,SOTA GenVideoModel!
page:https://aivideo.hunyuan.tencent.com
code:https://github.com/Tencent/HunyuanVideo
page:https://aivideo.hunyuan.tencent.com
code:https://github.com/Tencent/HunyuanVideo
December 3, 2024 at 5:55 AM
Tencent open source 13B HuanYuanVideo,SOTA GenVideoModel!
page:https://aivideo.hunyuan.tencent.com
code:https://github.com/Tencent/HunyuanVideo
page:https://aivideo.hunyuan.tencent.com
code:https://github.com/Tencent/HunyuanVideo
Reposted by 青龍聖者

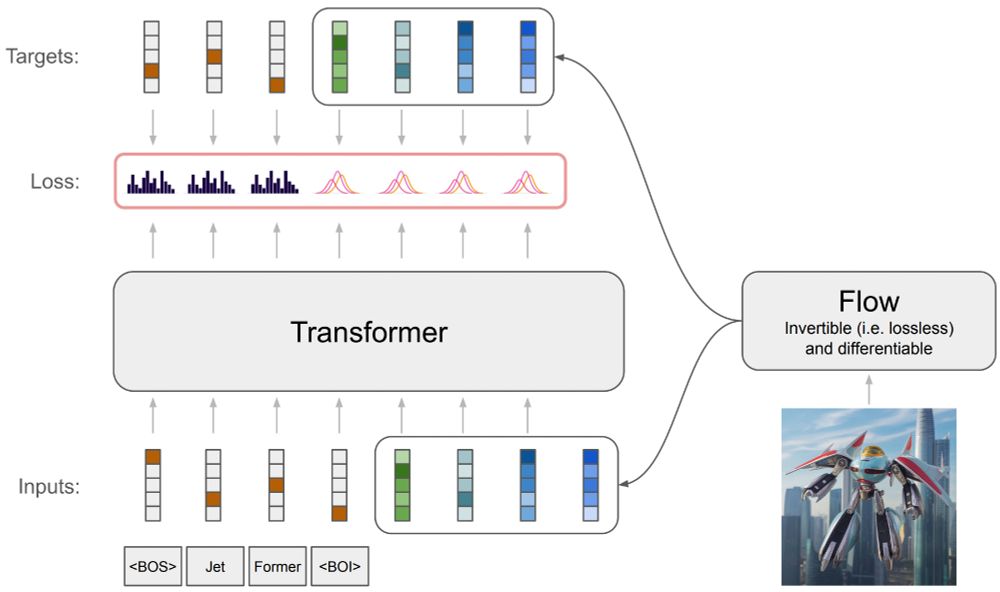
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
December 2, 2024 at 4:41 PM
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
Publish a 23M generated dataset from Midjourney Captioned Full Dataset. Thanks to the contribution of a certain third-party data provider who wishes to remain anonymous.
huggingface.co/datasets/dee...
huggingface.co/datasets/dee...

December 2, 2024 at 10:36 AM
Publish a 23M generated dataset from Midjourney Captioned Full Dataset. Thanks to the contribution of a certain third-party data provider who wishes to remain anonymous.
huggingface.co/datasets/dee...
huggingface.co/datasets/dee...
New tagger model is coming! Thank Mr. SmilingWolf!
huggingface.co/spaces/Smili...
huggingface.co/spaces/Smili...

November 30, 2024 at 2:07 PM
New tagger model is coming! Thank Mr. SmilingWolf!
huggingface.co/spaces/Smili...
huggingface.co/spaces/Smili...
Style-Friendly SNR Sampler for Style-Driven Generation
Just change SNR can make better style model!
μ=−6,α = 2
if you use kohya, just set
--weighting_scheme=logit_normal
--logit_mean=-6,
--logit_std=2
arxiv.org/abs/2411.147...
Just change SNR can make better style model!
μ=−6,α = 2
if you use kohya, just set
--weighting_scheme=logit_normal
--logit_mean=-6,
--logit_std=2
arxiv.org/abs/2411.147...




November 27, 2024 at 6:04 AM
Style-Friendly SNR Sampler for Style-Driven Generation
Just change SNR can make better style model!
μ=−6,α = 2
if you use kohya, just set
--weighting_scheme=logit_normal
--logit_mean=-6,
--logit_std=2
arxiv.org/abs/2411.147...
Just change SNR can make better style model!
μ=−6,α = 2
if you use kohya, just set
--weighting_scheme=logit_normal
--logit_mean=-6,
--logit_std=2
arxiv.org/abs/2411.147...
Reposted by 青龍聖者

Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!

November 26, 2024 at 3:57 PM
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
Sora was initially amazing, but now it's way behind.
huggingface.co/spaces/PR-Pu...
huggingface.co/spaces/PR-Pu...

November 26, 2024 at 6:23 PM
Sora was initially amazing, but now it's way behind.
huggingface.co/spaces/PR-Pu...
huggingface.co/spaces/PR-Pu...
Stability AI drop ControlNets for Stable Diffusion 3.5 Large
stability.ai/news/sd3-5-l...
Blur、Canny、Depth
stability.ai/news/sd3-5-l...
Blur、Canny、Depth




November 26, 2024 at 4:22 PM
Stability AI drop ControlNets for Stable Diffusion 3.5 Large
stability.ai/news/sd3-5-l...
Blur、Canny、Depth
stability.ai/news/sd3-5-l...
Blur、Canny、Depth
Kaze AI, a watermark cleaning tool.
kaze.ai/toolkit/wate...
kaze.ai/toolkit/wate...



November 26, 2024 at 1:58 PM
Kaze AI, a watermark cleaning tool.
kaze.ai/toolkit/wate...
kaze.ai/toolkit/wate...
Qwen2vl-Flux is a SOTA multimodal image generation model that enhances FLUX with Qwen2VL's vision-language understanding capabilities.
huggingface.co/Djrango/Qwen...
huggingface.co/Djrango/Qwen...




November 25, 2024 at 2:06 PM
Qwen2vl-Flux is a SOTA multimodal image generation model that enhances FLUX with Qwen2VL's vision-language understanding capabilities.
huggingface.co/Djrango/Qwen...
huggingface.co/Djrango/Qwen...
OminiControl: Minimal and Universal Control for Diffusion Transformer
Flux 1. model
Code:https://github.com/Yuanshi9815/OminiControl
Demo:https://huggingface.co/spaces/Yuanshi/OminiControl
Flux 1. model
Code:https://github.com/Yuanshi9815/OminiControl
Demo:https://huggingface.co/spaces/Yuanshi/OminiControl




November 25, 2024 at 11:24 AM
OminiControl: Minimal and Universal Control for Diffusion Transformer
Flux 1. model
Code:https://github.com/Yuanshi9815/OminiControl
Demo:https://huggingface.co/spaces/Yuanshi/OminiControl
Flux 1. model
Code:https://github.com/Yuanshi9815/OminiControl
Demo:https://huggingface.co/spaces/Yuanshi/OminiControl
Reposted by 青龍聖者

So first version of an ml anon starter pack. go.bsky.app/VgWL5L Kept half-anons (like me and Vic). Not all anime pfp, but generally drawn.
November 24, 2024 at 4:55 PM
So first version of an ml anon starter pack. go.bsky.app/VgWL5L Kept half-anons (like me and Vic). Not all anime pfp, but generally drawn.