



Raphael Pisoni
@4rtemi5.bsky.social
Unsupervised multimodal representation of a learning researcher.
https://www.rpisoni.dev/
https://www.rpisoni.dev/
Reposted by Raphael Pisoni

The US government should subsidize Open AI rather than OpenAI
November 7, 2025 at 6:43 AM
The US government should subsidize Open AI rather than OpenAI
Reposted by Raphael Pisoni

On the occasion of the 1000th citation of our Sinkhorn-Knopp self-supervised representation learning paper, I've written a whole post about the history and the key bits of this method that powers the state-of-the-art SSL vision models.
Read it here :): docs.google.com/document/d/1...
Read it here :): docs.google.com/document/d/1...

October 15, 2025 at 10:00 AM
On the occasion of the 1000th citation of our Sinkhorn-Knopp self-supervised representation learning paper, I've written a whole post about the history and the key bits of this method that powers the state-of-the-art SSL vision models.
Read it here :): docs.google.com/document/d/1...
Read it here :): docs.google.com/document/d/1...
We're ready!

might be time
September 21, 2025 at 6:39 AM
We're ready!
The single most undervalued property of neural networks is self-consistency. We should change that!
September 6, 2025 at 12:58 PM
The single most undervalued property of neural networks is self-consistency. We should change that!
Reposted by Raphael Pisoni

July 26, 2025 at 12:51 PM
You and Adam keep beating Sota? Stop doing that! Poor Sota!
July 26, 2025 at 9:50 AM
You and Adam keep beating Sota? Stop doing that! Poor Sota!
Have some cool idea but only evaluate it on small models? Tough luck buddy. You only get your paper accepted if your experimental results are 0.2% above SOTA and too expensive to falsify!
Is academic publishing pay to win yet?
Is academic publishing pay to win yet?
July 26, 2025 at 9:45 AM
Have some cool idea but only evaluate it on small models? Tough luck buddy. You only get your paper accepted if your experimental results are 0.2% above SOTA and too expensive to falsify!
Is academic publishing pay to win yet?
Is academic publishing pay to win yet?
Is there a reason why none of the recent models use RBF-kernel Attention to get rid of the softmax-bottleneck for long context?
I tried replacing dot-product attention with the negative squared KQ-distance and was able to remove the softmax without issues and loss in performance!
I tried replacing dot-product attention with the negative squared KQ-distance and was able to remove the softmax without issues and loss in performance!

July 23, 2025 at 8:14 PM
Is there a reason why none of the recent models use RBF-kernel Attention to get rid of the softmax-bottleneck for long context?
I tried replacing dot-product attention with the negative squared KQ-distance and was able to remove the softmax without issues and loss in performance!
I tried replacing dot-product attention with the negative squared KQ-distance and was able to remove the softmax without issues and loss in performance!
Reposted by Raphael Pisoni

NeurIPS is endorsing EurIPS, an independently-organized meeting which will offer researchers an opportunity to additionally present NeurIPS work in Europe concurrently with NeurIPS.
Read more in our blog post and on the EurIPS website:
blog.neurips.cc/2025/07/16/n...
eurips.cc
Read more in our blog post and on the EurIPS website:
blog.neurips.cc/2025/07/16/n...
eurips.cc

eurips.cc
A NeurIPS-endorsed conference in Europe held in Copenhagen, Denmark
eurips.cc
July 16, 2025 at 10:05 PM
NeurIPS is endorsing EurIPS, an independently-organized meeting which will offer researchers an opportunity to additionally present NeurIPS work in Europe concurrently with NeurIPS.
Read more in our blog post and on the EurIPS website:
blog.neurips.cc/2025/07/16/n...
eurips.cc
Read more in our blog post and on the EurIPS website:
blog.neurips.cc/2025/07/16/n...
eurips.cc
Has anyone experimented with "conditional gradients"?
Thinking about a setup where, within a specific activation range (e.g., right before a ReLU), you'd only permit positive or negative gradients.
Thinking about a setup where, within a specific activation range (e.g., right before a ReLU), you'd only permit positive or negative gradients.
July 8, 2025 at 5:59 AM
Has anyone experimented with "conditional gradients"?
Thinking about a setup where, within a specific activation range (e.g., right before a ReLU), you'd only permit positive or negative gradients.
Thinking about a setup where, within a specific activation range (e.g., right before a ReLU), you'd only permit positive or negative gradients.
Quick question to the SSL experts out there: Usually you evaluate an ssl-model by freezing it and training a linear probing layer. Would it be fair to somehow learn a final layer with more dimensions than classes and do a nearest-neighbor evaluation?
June 29, 2025 at 11:17 AM
Quick question to the SSL experts out there: Usually you evaluate an ssl-model by freezing it and training a linear probing layer. Would it be fair to somehow learn a final layer with more dimensions than classes and do a nearest-neighbor evaluation?
Reposted by Raphael Pisoni

There is an oak forest in central France that was planted 400 years ago by Colbert so that France would have quality hard wood by the 2000s to build ships for its navy.
This is the type of long term planning that Seldonian predictions can help improving.
This is the type of long term planning that Seldonian predictions can help improving.
June 17, 2025 at 8:17 AM
There is an oak forest in central France that was planted 400 years ago by Colbert so that France would have quality hard wood by the 2000s to build ships for its navy.
This is the type of long term planning that Seldonian predictions can help improving.
This is the type of long term planning that Seldonian predictions can help improving.
Reposted by Raphael Pisoni

New anti-censorship jailbreak just dropped ;)

May 13, 2025 at 2:17 AM
New anti-censorship jailbreak just dropped ;)
Currently on my way to #ICLR in Singapore where we'll present our latest paper on space folding in neural networks.
Would be happy to meet some people there so if you're at ICLR as well and want to hang out feel free to pm!🙂
Would be happy to meet some people there so if you're at ICLR as well and want to hang out feel free to pm!🙂
April 18, 2025 at 11:19 AM
Currently on my way to #ICLR in Singapore where we'll present our latest paper on space folding in neural networks.
Would be happy to meet some people there so if you're at ICLR as well and want to hang out feel free to pm!🙂
Would be happy to meet some people there so if you're at ICLR as well and want to hang out feel free to pm!🙂
Grok this! What a roller-coaster of emotions...🤪

April 16, 2025 at 7:01 PM
Grok this! What a roller-coaster of emotions...🤪
Reposted by Raphael Pisoni

ModernBERT or DeBERTaV3?
What's driving performance: architecture or data?
To find out we pretrained ModernBERT on the same dataset as CamemBERTaV2 (a DeBERTaV3 model) to isolate architecture effects.
Here are our findings:
What's driving performance: architecture or data?
To find out we pretrained ModernBERT on the same dataset as CamemBERTaV2 (a DeBERTaV3 model) to isolate architecture effects.
Here are our findings:
April 14, 2025 at 3:41 PM
ModernBERT or DeBERTaV3?
What's driving performance: architecture or data?
To find out we pretrained ModernBERT on the same dataset as CamemBERTaV2 (a DeBERTaV3 model) to isolate architecture effects.
Here are our findings:
What's driving performance: architecture or data?
To find out we pretrained ModernBERT on the same dataset as CamemBERTaV2 (a DeBERTaV3 model) to isolate architecture effects.
Here are our findings:
Reposted by Raphael Pisoni

Just assembled a slide about local feature training time/dataset size.
Anything wrong/missing?
Anything wrong/missing?

April 13, 2025 at 11:20 AM
Just assembled a slide about local feature training time/dataset size.
Anything wrong/missing?
Anything wrong/missing?
Is the project even still worth doing when wandb runs out of funny names or am I cooked?🫠
April 11, 2025 at 11:11 PM
Is the project even still worth doing when wandb runs out of funny names or am I cooked?🫠
Reposted by Raphael Pisoni

Meta introduced Llama 4 models and added this section near the very bottom of the announcement 😬
“[LLMs] historically have leaned left when it comes to debated political and social topics.”
ai.meta.com/blog/llama-4...
“[LLMs] historically have leaned left when it comes to debated political and social topics.”
ai.meta.com/blog/llama-4...
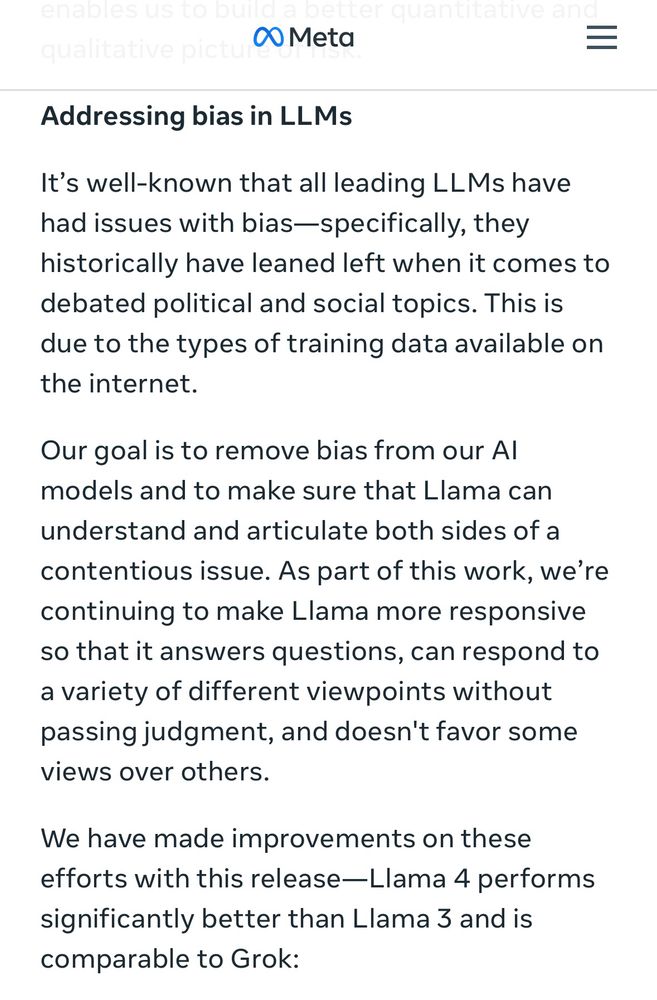

April 5, 2025 at 10:08 PM
Meta introduced Llama 4 models and added this section near the very bottom of the announcement 😬
“[LLMs] historically have leaned left when it comes to debated political and social topics.”
ai.meta.com/blog/llama-4...
“[LLMs] historically have leaned left when it comes to debated political and social topics.”
ai.meta.com/blog/llama-4...
Reposted by Raphael Pisoni

🚀Hello, world! We are now live on Bluesky. This is the official account of the Department of Computer Science at ETH Zurich. Follow us for cutting-edge research, the latest innovations, event updates and insights into the future of technology. inf.ethz.ch
@csateth.bsky.social @ethzurich.bsky.social
@csateth.bsky.social @ethzurich.bsky.social

Department of Computer Science
Computer Science Department at ETH Zurich. The department offers highest quality in computer science research and education and adds to business and industry growth.
inf.ethz.ch
March 24, 2025 at 9:24 AM
🚀Hello, world! We are now live on Bluesky. This is the official account of the Department of Computer Science at ETH Zurich. Follow us for cutting-edge research, the latest innovations, event updates and insights into the future of technology. inf.ethz.ch
@csateth.bsky.social @ethzurich.bsky.social
@csateth.bsky.social @ethzurich.bsky.social
Recently had the pleasure of helping @miclew.bsky.social with a couple of his papers in exchange for him helping me with a couple of mine!
This is the first fruit of our common work. We quantify space folding in relu neural networks with a range based measure. Lots of fun to write and read!😉
This is the first fruit of our common work. We quantify space folding in relu neural networks with a range based measure. Lots of fun to write and read!😉

On Space Folds of ReLU Neural Networks
Michal Lewandowski, Hamid Eghbalzadeh, Bernhard Heinzl, Raphael Pisoni, Bernhard A. Moser
Action editor: Petar Veličković
https://openreview.net/forum?id=RfFqBXLDQk
#cantornet #similarity #relu
Michal Lewandowski, Hamid Eghbalzadeh, Bernhard Heinzl, Raphael Pisoni, Bernhard A. Moser
Action editor: Petar Veličković
https://openreview.net/forum?id=RfFqBXLDQk
#cantornet #similarity #relu
March 24, 2025 at 12:19 PM
Recently had the pleasure of helping @miclew.bsky.social with a couple of his papers in exchange for him helping me with a couple of mine!
This is the first fruit of our common work. We quantify space folding in relu neural networks with a range based measure. Lots of fun to write and read!😉
This is the first fruit of our common work. We quantify space folding in relu neural networks with a range based measure. Lots of fun to write and read!😉


Reposted by Raphael Pisoni

🚀 Paper Release! 🚀
Curious about image retrieval and contrastive learning? We present:
📄 "All You Need to Know About Training Image Retrieval Models"
🔍 The most comprehensive retrieval benchmark—thousands of experiments across 4 datasets, dozens of losses, batch sizes, LRs, data labeling, and more!
Curious about image retrieval and contrastive learning? We present:
📄 "All You Need to Know About Training Image Retrieval Models"
🔍 The most comprehensive retrieval benchmark—thousands of experiments across 4 datasets, dozens of losses, batch sizes, LRs, data labeling, and more!

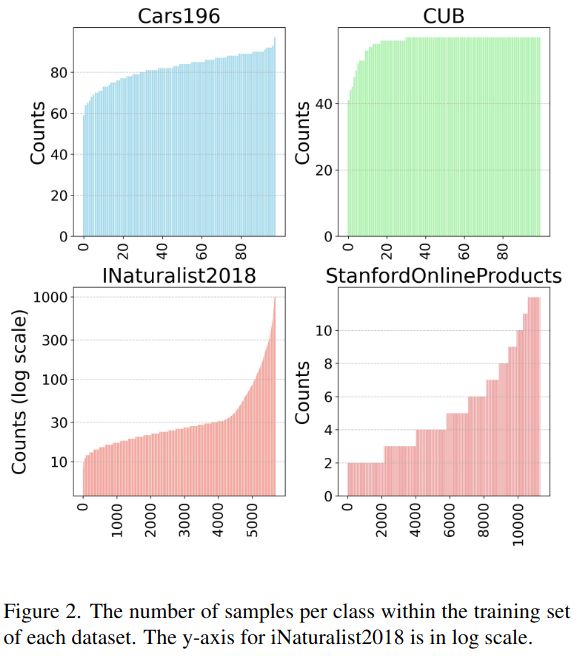
March 18, 2025 at 10:41 PM
🚀 Paper Release! 🚀
Curious about image retrieval and contrastive learning? We present:
📄 "All You Need to Know About Training Image Retrieval Models"
🔍 The most comprehensive retrieval benchmark—thousands of experiments across 4 datasets, dozens of losses, batch sizes, LRs, data labeling, and more!
Curious about image retrieval and contrastive learning? We present:
📄 "All You Need to Know About Training Image Retrieval Models"
🔍 The most comprehensive retrieval benchmark—thousands of experiments across 4 datasets, dozens of losses, batch sizes, LRs, data labeling, and more!