



David Schneider-Joseph
@thedavidsj.bsky.social
Working on AI gov. Past: Technology and Security Policy @ RAND re: AI compute, telemetry database lead & 1st stage landing software @ SpaceX; AWS; Google.
Steven Pinker on my essay: x.com/sapinker/sta...

August 25, 2025 at 10:24 PM
Steven Pinker on my essay: x.com/sapinker/sta...
Claude 4 Opus seems very excitable.

May 23, 2025 at 1:59 AM
Claude 4 Opus seems very excitable.
Why are modern book covers so bad?


May 11, 2025 at 6:04 AM
Why are modern book covers so bad?
Asking Claude important questions about papal succession.
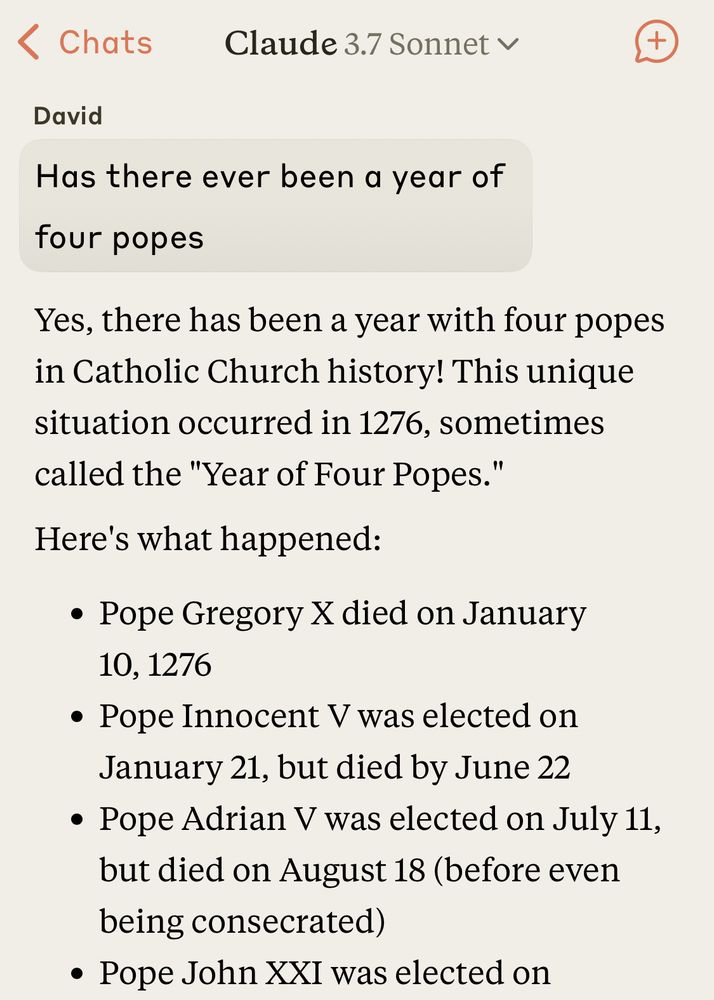



April 23, 2025 at 6:19 AM
Asking Claude important questions about papal succession.
Appears Trump admin is adversarially interpreting SCOTUS order to “facilitate” return of Garcia (who, by their admission, they sent without cause to El Salvadorian prison), to mean they must merely “remove any domestic obstacles”, rather than actually work to secure his return.

April 14, 2025 at 1:00 AM
Appears Trump admin is adversarially interpreting SCOTUS order to “facilitate” return of Garcia (who, by their admission, they sent without cause to El Salvadorian prison), to mean they must merely “remove any domestic obstacles”, rather than actually work to secure his return.
I haven’t checked these numbers myself, but it appears that the “Tariffs Charged to the US” column in the White House’s new tariff legend is actually just the ratio of the US trade deficit with that country divided by US imports from that country, with a floor at 10%. Pretty incredible really.


April 2, 2025 at 11:52 PM
I haven’t checked these numbers myself, but it appears that the “Tariffs Charged to the US” column in the White House’s new tariff legend is actually just the ratio of the US trade deficit with that country divided by US imports from that country, with a floor at 10%. Pretty incredible really.
Probably the most blatant autobiographical confabulation I’ve seen from Claude.

March 17, 2025 at 12:24 AM
Probably the most blatant autobiographical confabulation I’ve seen from Claude.
Did you all know that Hawaii was this long

March 5, 2025 at 3:58 AM
Did you all know that Hawaii was this long
Mostly false, as this applied to wage income but not capital gains. But the affected individuals mostly made their income from capital gains.

January 31, 2025 at 5:34 AM
Mostly false, as this applied to wage income but not capital gains. But the affected individuals mostly made their income from capital gains.
The key/value decompression matrices are transposed and absorbed into the query and output projection matrices to avoid the cost of decompression, giving an effective head width of 512 for values and 576 for keys (with 64 additional for decoupled positional encoding). 4/6

January 30, 2025 at 9:23 PM
The key/value decompression matrices are transposed and absorbed into the query and output projection matrices to avoid the cost of decompression, giving an effective head width of 512 for values and 576 for keys (with 64 additional for decoupled positional encoding). 4/6
R1’s Multi-head Latent Attention (MLA) achieves substantial KV compression (~1/4× compared to GQA) and requires much more arithmetic (about 4× per head). At large batch sizes and context lengths, this makes it more FLOP-bound than IO-bound, which is unusual for inference. 3/6

January 30, 2025 at 9:23 PM
R1’s Multi-head Latent Attention (MLA) achieves substantial KV compression (~1/4× compared to GQA) and requires much more arithmetic (about 4× per head). At large batch sizes and context lengths, this makes it more FLOP-bound than IO-bound, which is unusual for inference. 3/6
Assumptions: Arithmetic in FP8, response lengths of 10k output tokens (Fig 3 from R1 report), serving on H100s or H800s at $2/GPU hour. 2/6

January 30, 2025 at 9:22 PM
Assumptions: Arithmetic in FP8, response lengths of 10k output tokens (Fig 3 from R1 report), serving on H100s or H800s at $2/GPU hour. 2/6
Multi-head Latent Attention is essentially the same as Multi-Query Attention (single KV head), but with a larger head width, same vector for key and value, and low-rank factorization of query/output projection matrices (the K, V "decompression matrices" acting as one factor).


January 29, 2025 at 9:59 PM
Multi-head Latent Attention is essentially the same as Multi-Query Attention (single KV head), but with a larger head width, same vector for key and value, and low-rank factorization of query/output projection matrices (the K, V "decompression matrices" acting as one factor).
I tried this on GPT-4o, o1, o1-mini, o1-pro, Claude 3.5 Sonnet, Claude 3.0 Opus, Gemini 2.0 Experimental Advanced, Gemini 2.0 Flash Thinking Mode, DeepSeek-V3, and DeepSeek-V3 w/DeepThink.
Every "reasoning" model got it right. Every other model got it wrong. Seems notable.
Every "reasoning" model got it right. Every other model got it wrong. Seems notable.

January 17, 2025 at 4:24 AM
I tried this on GPT-4o, o1, o1-mini, o1-pro, Claude 3.5 Sonnet, Claude 3.0 Opus, Gemini 2.0 Experimental Advanced, Gemini 2.0 Flash Thinking Mode, DeepSeek-V3, and DeepSeek-V3 w/DeepThink.
Every "reasoning" model got it right. Every other model got it wrong. Seems notable.
Every "reasoning" model got it right. Every other model got it wrong. Seems notable.
And sorting.
January 16, 2025 at 9:12 PM
And sorting.
Some pretty impressive folding abilities on display here with π0 trained with FAST.
This single model can control lots of different robots and responds to language instruction inputs.
This single model can control lots of different robots and responds to language instruction inputs.
January 16, 2025 at 9:12 PM
Some pretty impressive folding abilities on display here with π0 trained with FAST.
This single model can control lots of different robots and responds to language instruction inputs.
This single model can control lots of different robots and responds to language instruction inputs.
Very cool demonstration of in-context representation learning. This figure says everything.
arxiv.org/abs/2501.00070
arxiv.org/abs/2501.00070

January 5, 2025 at 6:39 PM
Very cool demonstration of in-context representation learning. This figure says everything.
arxiv.org/abs/2501.00070
arxiv.org/abs/2501.00070
Imagine just being named Dr. Science.

December 22, 2024 at 7:49 PM
Imagine just being named Dr. Science.
Stuff like this makes me think we may still have a ways to go.

December 16, 2024 at 8:08 AM
Stuff like this makes me think we may still have a ways to go.

December 15, 2024 at 4:52 PM
In that vein there’s also this from the BIIB080 Phase 1b.

December 3, 2024 at 11:26 AM
In that vein there’s also this from the BIIB080 Phase 1b.