



@testerpce.bsky.social
Reposted

Can't wait for when I can vibe code a production recommender system.
Until then, here's some system designs:
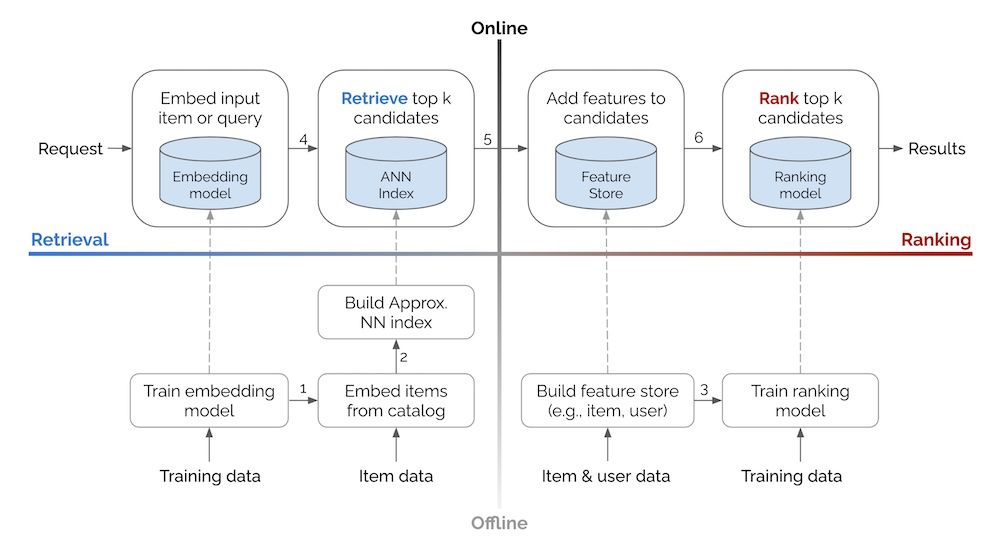
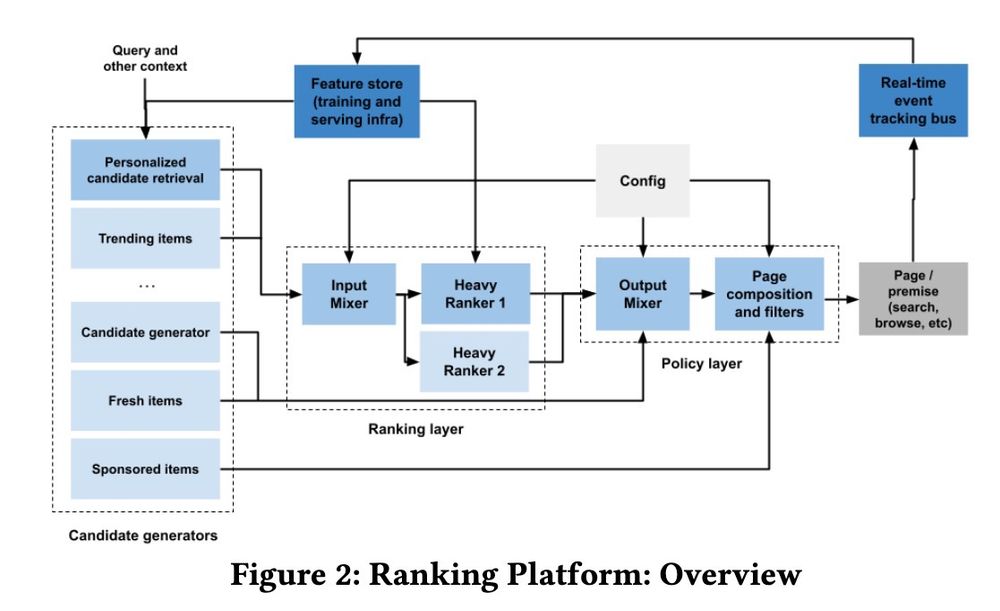
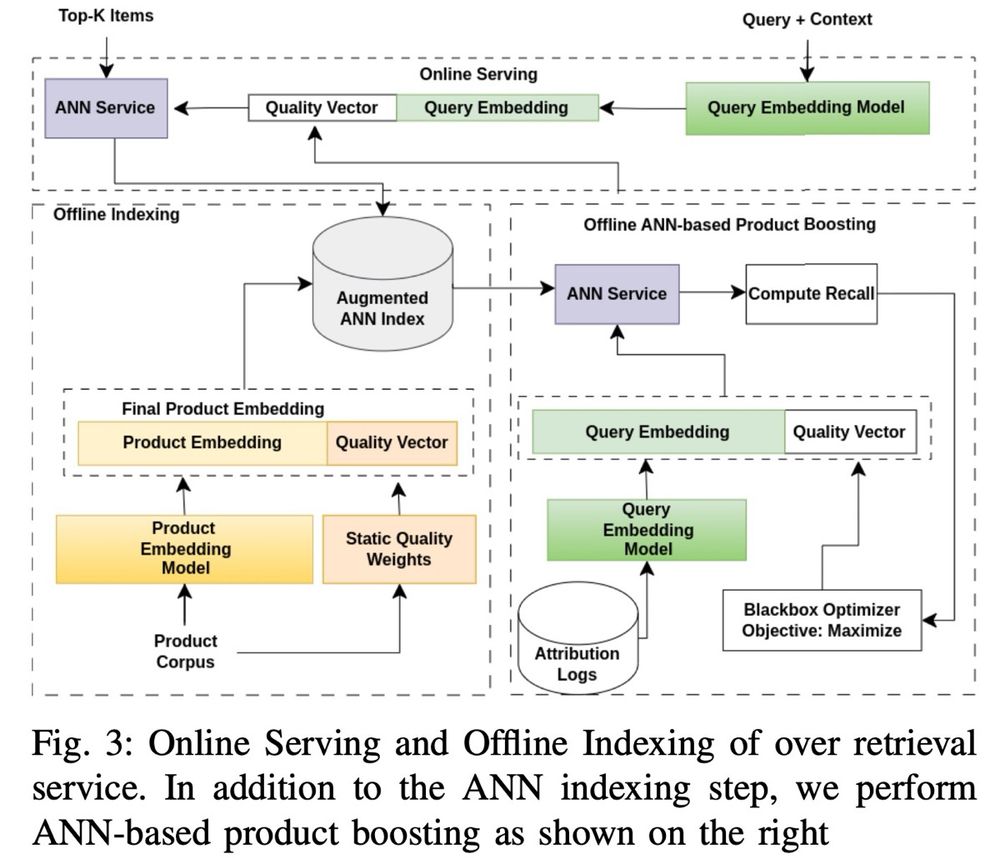
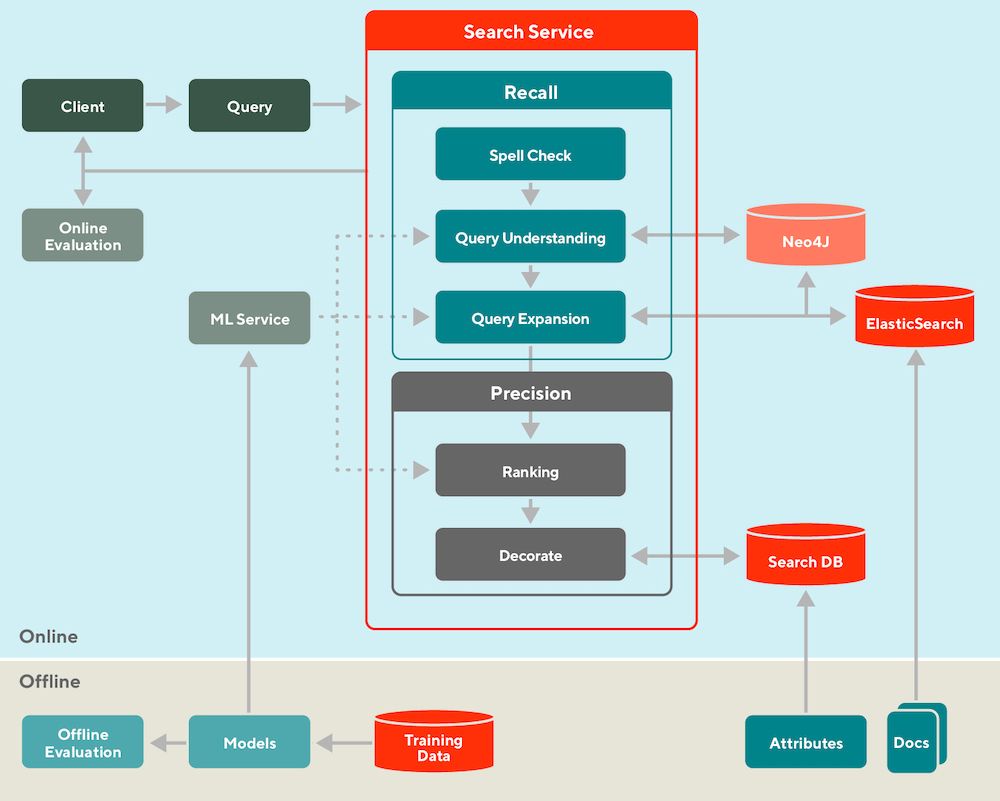
• Retrieval vs. Ranking: eugeneyan.com/writing/syst...
• Real-time retrieval: eugeneyan.com/writing/real...
• Personalization: eugeneyan.com/writing/patt...
Until then, here's some system designs:
• Retrieval vs. Ranking: eugeneyan.com/writing/syst...
• Real-time retrieval: eugeneyan.com/writing/real...
• Personalization: eugeneyan.com/writing/patt...
April 8, 2025 at 5:14 AM
Can't wait for when I can vibe code a production recommender system.
Until then, here's some system designs:
• Retrieval vs. Ranking: eugeneyan.com/writing/syst...
• Real-time retrieval: eugeneyan.com/writing/real...
• Personalization: eugeneyan.com/writing/patt...
Until then, here's some system designs:
• Retrieval vs. Ranking: eugeneyan.com/writing/syst...
• Real-time retrieval: eugeneyan.com/writing/real...
• Personalization: eugeneyan.com/writing/patt...
Awesome working with the IITB folks. Super happy to see this
Soumen Kumar Mondal, Sayambhu Sen, Abhishek Singhania, Preethi Jyothi
Language-specific Neurons Do Not Facilitate Cross-Lingual Transfer
https://arxiv.org/abs/2503.17456
Language-specific Neurons Do Not Facilitate Cross-Lingual Transfer
https://arxiv.org/abs/2503.17456
March 25, 2025 at 2:52 PM
Awesome working with the IITB folks. Super happy to see this
Reposted

Dataset Distillation (2018/2020)
They show that it is possible to compress 60,000 MNIST training images into just 10 synthetic distilled images (one per class) and achieve close to original performance with only a few gradient descent steps, given a fixed network initialization.
They show that it is possible to compress 60,000 MNIST training images into just 10 synthetic distilled images (one per class) and achieve close to original performance with only a few gradient descent steps, given a fixed network initialization.

March 5, 2025 at 12:23 AM
Dataset Distillation (2018/2020)
They show that it is possible to compress 60,000 MNIST training images into just 10 synthetic distilled images (one per class) and achieve close to original performance with only a few gradient descent steps, given a fixed network initialization.
They show that it is possible to compress 60,000 MNIST training images into just 10 synthetic distilled images (one per class) and achieve close to original performance with only a few gradient descent steps, given a fixed network initialization.
Reposted

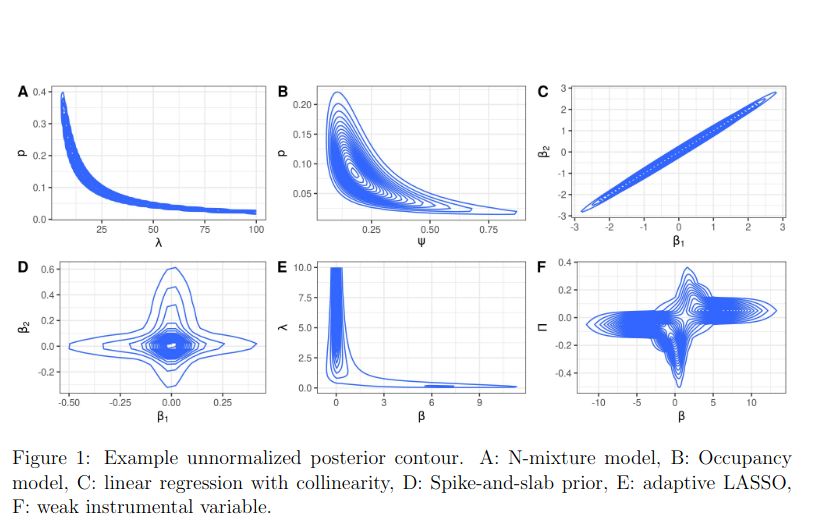
"Wild posteriors in the wild"
A cool-looking paper if you're interested in funky posterior geometry
Link: arxiv.org/abs/2503.00239
Code: github.com/YunyiShen/we...
#stats
A cool-looking paper if you're interested in funky posterior geometry
Link: arxiv.org/abs/2503.00239
Code: github.com/YunyiShen/we...
#stats

March 5, 2025 at 3:36 AM
"Wild posteriors in the wild"
A cool-looking paper if you're interested in funky posterior geometry
Link: arxiv.org/abs/2503.00239
Code: github.com/YunyiShen/we...
#stats
A cool-looking paper if you're interested in funky posterior geometry
Link: arxiv.org/abs/2503.00239
Code: github.com/YunyiShen/we...
#stats
Reposted

Anyone interested in interactive story generation? I genuinely love this stuff, and would love to talk about it with anyone who's interested
This is a little tool I made to experiment with generating like murder mysteries automatically~
This is a little tool I made to experiment with generating like murder mysteries automatically~
February 28, 2025 at 9:29 PM
Anyone interested in interactive story generation? I genuinely love this stuff, and would love to talk about it with anyone who's interested
This is a little tool I made to experiment with generating like murder mysteries automatically~
This is a little tool I made to experiment with generating like murder mysteries automatically~
Reposted

Xiaoyu Deng, Ye Zhang, Tianmin Guo, Yongzhe Zhang, Zhengjian Kang, Hang Yang
ChallengeMe: An Adversarial Learning-enabled Text Summarization Framework
https://arxiv.org/abs/2502.05084
ChallengeMe: An Adversarial Learning-enabled Text Summarization Framework
https://arxiv.org/abs/2502.05084
February 10, 2025 at 6:36 AM
Xiaoyu Deng, Ye Zhang, Tianmin Guo, Yongzhe Zhang, Zhengjian Kang, Hang Yang
ChallengeMe: An Adversarial Learning-enabled Text Summarization Framework
https://arxiv.org/abs/2502.05084
ChallengeMe: An Adversarial Learning-enabled Text Summarization Framework
https://arxiv.org/abs/2502.05084
Reposted
Roman Vashurin (Mohamed bin Zayed University of Artificial Intelligence), ...
CoCoA: A Generalized Approach to Uncertainty Quantification by Integrating Confidence and Consistency of LLM Outputs
https://arxiv.org/abs/2502.04964
CoCoA: A Generalized Approach to Uncertainty Quantification by Integrating Confidence and Consistency of LLM Outputs
https://arxiv.org/abs/2502.04964
February 10, 2025 at 6:37 AM
Roman Vashurin (Mohamed bin Zayed University of Artificial Intelligence), ...
CoCoA: A Generalized Approach to Uncertainty Quantification by Integrating Confidence and Consistency of LLM Outputs
https://arxiv.org/abs/2502.04964
CoCoA: A Generalized Approach to Uncertainty Quantification by Integrating Confidence and Consistency of LLM Outputs
https://arxiv.org/abs/2502.04964
Reposted
Haohao Zhu, Junyu Lu, Zeyuan Zeng, Zewen Bai, Xiaokun Zhang, Liang Yang, Hongfei Lin
Commonality and Individuality! Integrating Humor Commonality with Speaker Individuality for Humor Recognition
https://arxiv.org/abs/2502.04960
Commonality and Individuality! Integrating Humor Commonality with Speaker Individuality for Humor Recognition
https://arxiv.org/abs/2502.04960
February 10, 2025 at 6:38 AM
Haohao Zhu, Junyu Lu, Zeyuan Zeng, Zewen Bai, Xiaokun Zhang, Liang Yang, Hongfei Lin
Commonality and Individuality! Integrating Humor Commonality with Speaker Individuality for Humor Recognition
https://arxiv.org/abs/2502.04960
Commonality and Individuality! Integrating Humor Commonality with Speaker Individuality for Humor Recognition
https://arxiv.org/abs/2502.04960
Reposted

@xtimv.bsky.social and I were just discussing this interesting comment in the DeepSeek paper introducing GRPO: a different way of setting up the KL loss.
It's a little hard to reason about what this does to the objective. 1/
It's a little hard to reason about what this does to the objective. 1/

February 10, 2025 at 4:32 AM
@xtimv.bsky.social and I were just discussing this interesting comment in the DeepSeek paper introducing GRPO: a different way of setting up the KL loss.
It's a little hard to reason about what this does to the objective. 1/
It's a little hard to reason about what this does to the objective. 1/
Reposted
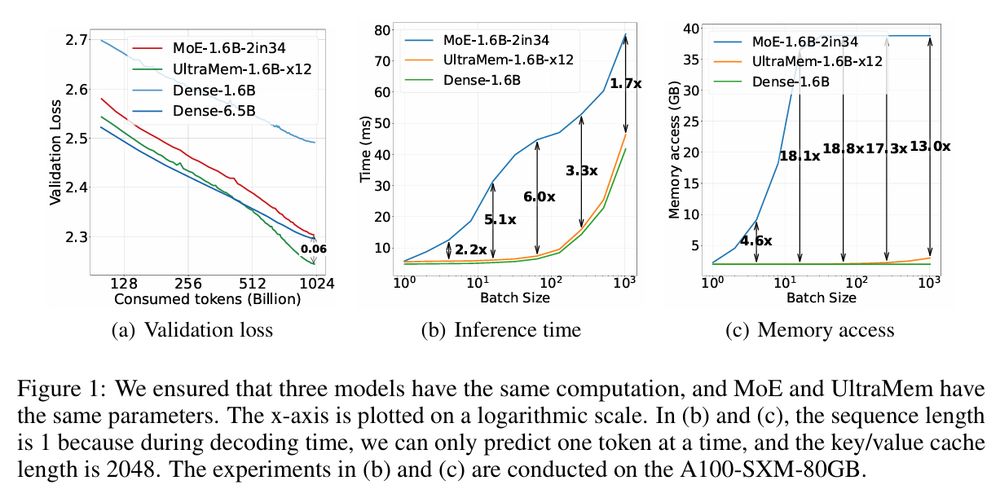
ByteDance's UltraMem
A new ultra sparse model that
- exhibits favorable scaling properties but outperforms MoE
- inference speed is 1.7x to 6.0x faster than MoE
Paper: Ultra-Sparse Memory Network ( arxiv.org/abs/2411.12364 )
A new ultra sparse model that
- exhibits favorable scaling properties but outperforms MoE
- inference speed is 1.7x to 6.0x faster than MoE
Paper: Ultra-Sparse Memory Network ( arxiv.org/abs/2411.12364 )
February 10, 2025 at 6:42 AM
ByteDance's UltraMem
A new ultra sparse model that
- exhibits favorable scaling properties but outperforms MoE
- inference speed is 1.7x to 6.0x faster than MoE
Paper: Ultra-Sparse Memory Network ( arxiv.org/abs/2411.12364 )
A new ultra sparse model that
- exhibits favorable scaling properties but outperforms MoE
- inference speed is 1.7x to 6.0x faster than MoE
Paper: Ultra-Sparse Memory Network ( arxiv.org/abs/2411.12364 )
Reposted
Masato Mita, Ryo Yoshida, Yohei Oseki
Developmentally-plausible Working Memory Shapes a Critical Period for Language Acquisition
https://arxiv.org/abs/2502.04795
Developmentally-plausible Working Memory Shapes a Critical Period for Language Acquisition
https://arxiv.org/abs/2502.04795
February 10, 2025 at 6:47 AM
Masato Mita, Ryo Yoshida, Yohei Oseki
Developmentally-plausible Working Memory Shapes a Critical Period for Language Acquisition
https://arxiv.org/abs/2502.04795
Developmentally-plausible Working Memory Shapes a Critical Period for Language Acquisition
https://arxiv.org/abs/2502.04795
Reposted
Jing Yang, Max Glockner, Anderson Rocha, Iryna Gurevych
Self-Rationalization in the Wild: A Large Scale Out-of-Distribution Evaluation on NLI-related tasks
https://arxiv.org/abs/2502.04797
Self-Rationalization in the Wild: A Large Scale Out-of-Distribution Evaluation on NLI-related tasks
https://arxiv.org/abs/2502.04797
February 10, 2025 at 6:47 AM
Jing Yang, Max Glockner, Anderson Rocha, Iryna Gurevych
Self-Rationalization in the Wild: A Large Scale Out-of-Distribution Evaluation on NLI-related tasks
https://arxiv.org/abs/2502.04797
Self-Rationalization in the Wild: A Large Scale Out-of-Distribution Evaluation on NLI-related tasks
https://arxiv.org/abs/2502.04797
Reposted
Santiago Gonz\'alez-Silot, Andr\'es Montoro-Montarroso, Eugenio Mart\'inez C\'amara, Juan G\'omez-Romero
Enhancing Disinformation Detection with Explainable AI and Named Entity Replacement
https://arxiv.org/abs/2502.04863
Enhancing Disinformation Detection with Explainable AI and Named Entity Replacement
https://arxiv.org/abs/2502.04863
February 10, 2025 at 6:46 AM
Santiago Gonz\'alez-Silot, Andr\'es Montoro-Montarroso, Eugenio Mart\'inez C\'amara, Juan G\'omez-Romero
Enhancing Disinformation Detection with Explainable AI and Named Entity Replacement
https://arxiv.org/abs/2502.04863
Enhancing Disinformation Detection with Explainable AI and Named Entity Replacement
https://arxiv.org/abs/2502.04863
Reposted
Herbert Ullrich, Tom\'a\v{s} Mlyn\'a\v{r}, Jan Drchal
Claim Extraction for Fact-Checking: Data, Models, and Automated Metrics
https://arxiv.org/abs/2502.04955
Claim Extraction for Fact-Checking: Data, Models, and Automated Metrics
https://arxiv.org/abs/2502.04955
February 10, 2025 at 6:45 AM
Herbert Ullrich, Tom\'a\v{s} Mlyn\'a\v{r}, Jan Drchal
Claim Extraction for Fact-Checking: Data, Models, and Automated Metrics
https://arxiv.org/abs/2502.04955
Claim Extraction for Fact-Checking: Data, Models, and Automated Metrics
https://arxiv.org/abs/2502.04955
Reposted

"All you need to build a strong reasoning model is the right data mix."
The pipeline that creates the data mix:
The pipeline that creates the data mix:
January 26, 2025 at 11:30 PM
"All you need to build a strong reasoning model is the right data mix."
The pipeline that creates the data mix:
The pipeline that creates the data mix:
Reposted
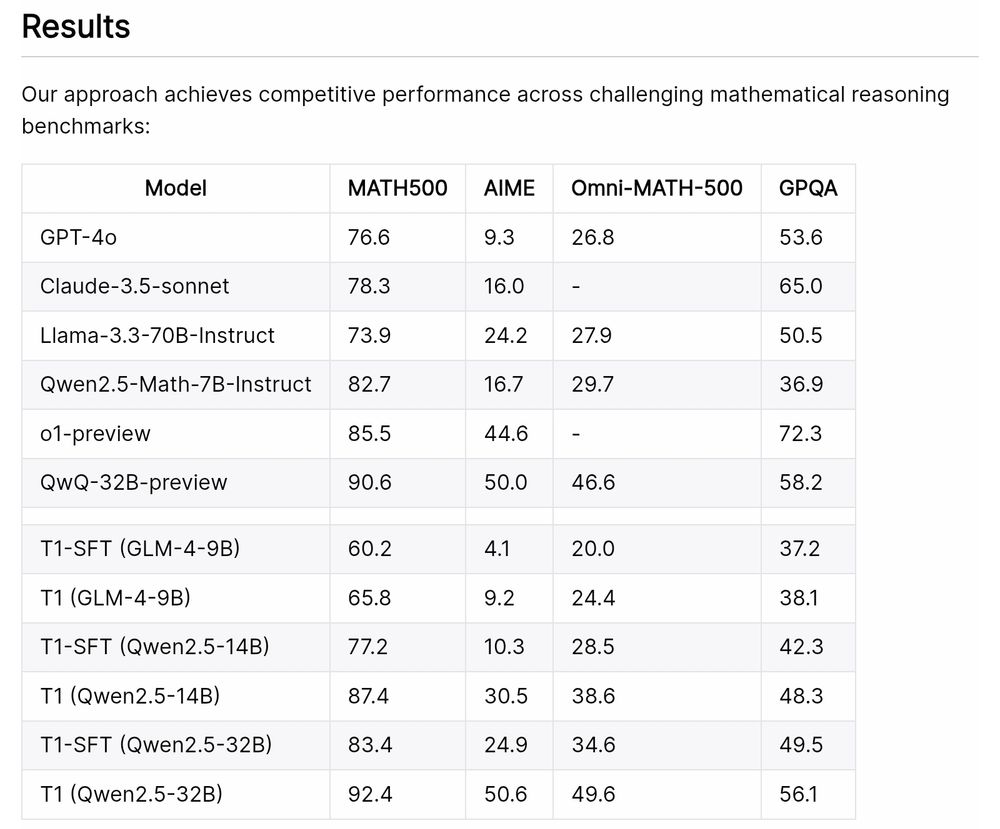
Zhipu AI's T1 (open-source: paper, code, dataset, and model)
Advancing Language Model Reasoning through Reinforcement Learning and Inference Scaling
T1 is trained by scaling RL by encouraging exploration and understand inference scaling.
Advancing Language Model Reasoning through Reinforcement Learning and Inference Scaling
T1 is trained by scaling RL by encouraging exploration and understand inference scaling.
January 27, 2025 at 1:49 AM
Zhipu AI's T1 (open-source: paper, code, dataset, and model)
Advancing Language Model Reasoning through Reinforcement Learning and Inference Scaling
T1 is trained by scaling RL by encouraging exploration and understand inference scaling.
Advancing Language Model Reasoning through Reinforcement Learning and Inference Scaling
T1 is trained by scaling RL by encouraging exploration and understand inference scaling.
Reposted
Naihao Deng, Sheng Zhang, Henghui Zhu, Shuaichen Chang, Jiani Zhang, Alexander Hanbo Li, Chung-Wei Hang, Hideo Kobayashi, Yiqun Hu, Patrick Ng
Towards Better Understanding Table Instruction Tuning: Decoupling the Effects from Data versus Models
https://arxiv.org/abs/2501.14717
Towards Better Understanding Table Instruction Tuning: Decoupling the Effects from Data versus Models
https://arxiv.org/abs/2501.14717
January 27, 2025 at 5:45 AM
Naihao Deng, Sheng Zhang, Henghui Zhu, Shuaichen Chang, Jiani Zhang, Alexander Hanbo Li, Chung-Wei Hang, Hideo Kobayashi, Yiqun Hu, Patrick Ng
Towards Better Understanding Table Instruction Tuning: Decoupling the Effects from Data versus Models
https://arxiv.org/abs/2501.14717
Towards Better Understanding Table Instruction Tuning: Decoupling the Effects from Data versus Models
https://arxiv.org/abs/2501.14717
Reposted
Ziyao Xu, Houfeng Wang
Investigating the (De)Composition Capabilities of Large Language Models in Natural-to-Formal Language Conversion
https://arxiv.org/abs/2501.14649
Investigating the (De)Composition Capabilities of Large Language Models in Natural-to-Formal Language Conversion
https://arxiv.org/abs/2501.14649
January 27, 2025 at 6:26 AM
Ziyao Xu, Houfeng Wang
Investigating the (De)Composition Capabilities of Large Language Models in Natural-to-Formal Language Conversion
https://arxiv.org/abs/2501.14649
Investigating the (De)Composition Capabilities of Large Language Models in Natural-to-Formal Language Conversion
https://arxiv.org/abs/2501.14649
Reposted
Jia Yu, Fei Yuan, Rui Min, Jing Yu, Pei Chu, Jiayang Li, Wei Li, Ruijie Zhang, Zhenxiang Li, Zhifei Ren, Dong Zheng, Wenjian Zhang, Yan Teng, Lingyu Meng, ...
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
https://arxiv.org/abs/2501.14506
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
https://arxiv.org/abs/2501.14506
January 27, 2025 at 6:42 AM
Jia Yu, Fei Yuan, Rui Min, Jing Yu, Pei Chu, Jiayang Li, Wei Li, Ruijie Zhang, Zhenxiang Li, Zhifei Ren, Dong Zheng, Wenjian Zhang, Yan Teng, Lingyu Meng, ...
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
https://arxiv.org/abs/2501.14506
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
https://arxiv.org/abs/2501.14506
Reposted
Jie He, Yijun Yang, Wanqiu Long, Deyi Xiong, Victor Gutierrez Basulto, Jeff Z. Pan
Evaluating and Improving Graph to Text Generation with Large Language Models
https://arxiv.org/abs/2501.14497
Evaluating and Improving Graph to Text Generation with Large Language Models
https://arxiv.org/abs/2501.14497
January 27, 2025 at 6:43 AM
Jie He, Yijun Yang, Wanqiu Long, Deyi Xiong, Victor Gutierrez Basulto, Jeff Z. Pan
Evaluating and Improving Graph to Text Generation with Large Language Models
https://arxiv.org/abs/2501.14497
Evaluating and Improving Graph to Text Generation with Large Language Models
https://arxiv.org/abs/2501.14497
Reposted
Verena Blaschke, Masha Fedzechkina, Maartje ter Hoeve
Analyzing the Effect of Linguistic Similarity on Cross-Lingual Transfer: Tasks and Experimental Setups Matter
https://arxiv.org/abs/2501.14491
Analyzing the Effect of Linguistic Similarity on Cross-Lingual Transfer: Tasks and Experimental Setups Matter
https://arxiv.org/abs/2501.14491
January 27, 2025 at 6:56 AM
Verena Blaschke, Masha Fedzechkina, Maartje ter Hoeve
Analyzing the Effect of Linguistic Similarity on Cross-Lingual Transfer: Tasks and Experimental Setups Matter
https://arxiv.org/abs/2501.14491
Analyzing the Effect of Linguistic Similarity on Cross-Lingual Transfer: Tasks and Experimental Setups Matter
https://arxiv.org/abs/2501.14491
Reposted
Zeping Yu, Sophia Ananiadou
Understanding and Mitigating Gender Bias in LLMs via Interpretable Neuron Editing
https://arxiv.org/abs/2501.14457
Understanding and Mitigating Gender Bias in LLMs via Interpretable Neuron Editing
https://arxiv.org/abs/2501.14457
January 27, 2025 at 7:06 AM
Zeping Yu, Sophia Ananiadou
Understanding and Mitigating Gender Bias in LLMs via Interpretable Neuron Editing
https://arxiv.org/abs/2501.14457
Understanding and Mitigating Gender Bias in LLMs via Interpretable Neuron Editing
https://arxiv.org/abs/2501.14457
Reposted
Xu Chu, Zhijie Tan, Hanlin Xue, Guanyu Wang, Tong Mo, Weiping Li
Domaino1s: Guiding LLM Reasoning for Explainable Answers in High-Stakes Domains
https://arxiv.org/abs/2501.14431
Domaino1s: Guiding LLM Reasoning for Explainable Answers in High-Stakes Domains
https://arxiv.org/abs/2501.14431
January 27, 2025 at 7:06 AM
Xu Chu, Zhijie Tan, Hanlin Xue, Guanyu Wang, Tong Mo, Weiping Li
Domaino1s: Guiding LLM Reasoning for Explainable Answers in High-Stakes Domains
https://arxiv.org/abs/2501.14431
Domaino1s: Guiding LLM Reasoning for Explainable Answers in High-Stakes Domains
https://arxiv.org/abs/2501.14431
Reposted
Xinyu Ma, Yifeng Xu, Yang Lin, Tianlong Wang, Xu Chu, Xin Gao, Junfeng Zhao, Yasha Wang
DRESSing Up LLM: Efficient Stylized Question-Answering via Style Subspace Editing
https://arxiv.org/abs/2501.14371
DRESSing Up LLM: Efficient Stylized Question-Answering via Style Subspace Editing
https://arxiv.org/abs/2501.14371
January 27, 2025 at 7:12 AM
Xinyu Ma, Yifeng Xu, Yang Lin, Tianlong Wang, Xu Chu, Xin Gao, Junfeng Zhao, Yasha Wang
DRESSing Up LLM: Efficient Stylized Question-Answering via Style Subspace Editing
https://arxiv.org/abs/2501.14371
DRESSing Up LLM: Efficient Stylized Question-Answering via Style Subspace Editing
https://arxiv.org/abs/2501.14371