




Tensorlake
@tensorlake.ai
Document parsing benchmarks have been measuring the wrong thing.
We tested every major parser on real enterprise documents.
The results will change how you think about OCR accuracy 🧵
We tested every major parser on real enterprise documents.
The results will change how you think about OCR accuracy 🧵

November 5, 2025 at 5:05 PM
Document parsing benchmarks have been measuring the wrong thing.
We tested every major parser on real enterprise documents.
The results will change how you think about OCR accuracy 🧵
We tested every major parser on real enterprise documents.
The results will change how you think about OCR accuracy 🧵
Want to build scalable data lakes w/ Tensorlake + @qdrant.bsky.social?
In the free Qdrant Essentials Course, learn how to:
- Architect vector-powered data lakes
- Optimize ETL pipelines
- Create knowledge graphs
- Integrate @langchain.bsky.social agents for natural language queries
t.co/OoPZswrL7z
In the free Qdrant Essentials Course, learn how to:
- Architect vector-powered data lakes
- Optimize ETL pipelines
- Create knowledge graphs
- Integrate @langchain.bsky.social agents for natural language queries
t.co/OoPZswrL7z

October 23, 2025 at 7:37 PM
Want to build scalable data lakes w/ Tensorlake + @qdrant.bsky.social?
In the free Qdrant Essentials Course, learn how to:
- Architect vector-powered data lakes
- Optimize ETL pipelines
- Create knowledge graphs
- Integrate @langchain.bsky.social agents for natural language queries
t.co/OoPZswrL7z
In the free Qdrant Essentials Course, learn how to:
- Architect vector-powered data lakes
- Optimize ETL pipelines
- Create knowledge graphs
- Integrate @langchain.bsky.social agents for natural language queries
t.co/OoPZswrL7z
Most parsers strip all tracked changes when you extract the text.
That means:
❌ Lost audit trails
❌ Manual review of revision history
❌ No programmatic access to reviewer comments
❌ Workflows that can't route based on specific edits
That means:
❌ Lost audit trails
❌ Manual review of revision history
❌ No programmatic access to reviewer comments
❌ Workflows that can't route based on specific edits

October 10, 2025 at 5:25 PM
Most parsers strip all tracked changes when you extract the text.
That means:
❌ Lost audit trails
❌ Manual review of revision history
❌ No programmatic access to reviewer comments
❌ Workflows that can't route based on specific edits
That means:
❌ Lost audit trails
❌ Manual review of revision history
❌ No programmatic access to reviewer comments
❌ Workflows that can't route based on specific edits
OCR engines constantly mess up document hierarchy.
Section 2.2 becomes a top-level header (##) instead of nested (###).
We just shipped automatic header correction.
🧵 How it works:
Section 2.2 becomes a top-level header (##) instead of nested (###).
We just shipped automatic header correction.
🧵 How it works:

October 2, 2025 at 4:21 PM
OCR engines constantly mess up document hierarchy.
Section 2.2 becomes a top-level header (##) instead of nested (###).
We just shipped automatic header correction.
🧵 How it works:
Section 2.2 becomes a top-level header (##) instead of nested (###).
We just shipped automatic header correction.
🧵 How it works:
Step 3: Generating AI responses with verifiable citations
Once your chunks carry anchors, retrieval doesn’t change. You can use the dense, hybrid, or reranker setup you already have. Consider hiding the anchors in prose, while keeping them in output and making IDs clickable.
Once your chunks carry anchors, retrieval doesn’t change. You can use the dense, hybrid, or reranker setup you already have. Consider hiding the anchors in prose, while keeping them in output and making IDs clickable.

September 19, 2025 at 5:44 PM
Step 3: Generating AI responses with verifiable citations
Once your chunks carry anchors, retrieval doesn’t change. You can use the dense, hybrid, or reranker setup you already have. Consider hiding the anchors in prose, while keeping them in output and making IDs clickable.
Once your chunks carry anchors, retrieval doesn’t change. You can use the dense, hybrid, or reranker setup you already have. Consider hiding the anchors in prose, while keeping them in output and making IDs clickable.
Step 2: Create contextualized chunks
Iterate through page fragment objects and create appropriately sized chunks by combining them. As you create the chunks, you can create contextualized metadata to help during retrieval.
Iterate through page fragment objects and create appropriately sized chunks by combining them. As you create the chunks, you can create contextualized metadata to help during retrieval.

September 19, 2025 at 5:44 PM
Step 2: Create contextualized chunks
Iterate through page fragment objects and create appropriately sized chunks by combining them. As you create the chunks, you can create contextualized metadata to help during retrieval.
Iterate through page fragment objects and create appropriately sized chunks by combining them. As you create the chunks, you can create contextualized metadata to help during retrieval.
Step 1: Parse docs with bounding boxes
Using our Document AI API you get a full document layout. For each page fragment you have access to the page number, fragment type, content, and bounding box. Making it easy to add metadata and anchor points to chunks before embedding.
Using our Document AI API you get a full document layout. For each page fragment you have access to the page number, fragment type, content, and bounding box. Making it easy to add metadata and anchor points to chunks before embedding.

September 19, 2025 at 5:44 PM
Step 1: Parse docs with bounding boxes
Using our Document AI API you get a full document layout. For each page fragment you have access to the page number, fragment type, content, and bounding box. Making it easy to add metadata and anchor points to chunks before embedding.
Using our Document AI API you get a full document layout. For each page fragment you have access to the page number, fragment type, content, and bounding box. Making it easy to add metadata and anchor points to chunks before embedding.
In finance, clinical trials, or performance benchmarks, dense tables contain mission-critical data.
But flatten that data like most parsers do and trust is lost.
Tensorlake restores trust by preserving structure, generating summaries for effective embeddings, and attaching evidence via b-boxes.
But flatten that data like most parsers do and trust is lost.
Tensorlake restores trust by preserving structure, generating summaries for effective embeddings, and attaching evidence via b-boxes.

September 11, 2025 at 8:00 PM
In finance, clinical trials, or performance benchmarks, dense tables contain mission-critical data.
But flatten that data like most parsers do and trust is lost.
Tensorlake restores trust by preserving structure, generating summaries for effective embeddings, and attaching evidence via b-boxes.
But flatten that data like most parsers do and trust is lost.
Tensorlake restores trust by preserving structure, generating summaries for effective embeddings, and attaching evidence via b-boxes.
You can now login into Tensorlake using Microsoft and Azure SSO credentials.
This is the beginning of better integration with Microsoft Azure and Tensorlake.
If you are using Azure, and need better Document Ingestion and ETL for unstructured data reach out to us!
This is the beginning of better integration with Microsoft Azure and Tensorlake.
If you are using Azure, and need better Document Ingestion and ETL for unstructured data reach out to us!

September 5, 2025 at 5:49 PM
You can now login into Tensorlake using Microsoft and Azure SSO credentials.
This is the beginning of better integration with Microsoft Azure and Tensorlake.
If you are using Azure, and need better Document Ingestion and ETL for unstructured data reach out to us!
This is the beginning of better integration with Microsoft Azure and Tensorlake.
If you are using Azure, and need better Document Ingestion and ETL for unstructured data reach out to us!
To build trustworthy AI, your data needs proof.
Get citations for every field extracted with Tensorlake.
Read the blog and try our citations with the example notebooks: tlake.link/blog/citations
Get citations for every field extracted with Tensorlake.
Read the blog and try our citations with the example notebooks: tlake.link/blog/citations
September 5, 2025 at 4:30 PM
To build trustworthy AI, your data needs proof.
Get citations for every field extracted with Tensorlake.
Read the blog and try our citations with the example notebooks: tlake.link/blog/citations
Get citations for every field extracted with Tensorlake.
Read the blog and try our citations with the example notebooks: tlake.link/blog/citations
Step 4: Test your context-aware agents
This is the fun part, use Tensorlake to extract key claims from news articles, then use your @langchain.bsky.social agent to query ChromaDB and determine whether the claims are rooted in fact.
This is the fun part, use Tensorlake to extract key claims from news articles, then use your @langchain.bsky.social agent to query ChromaDB and determine whether the claims are rooted in fact.


August 21, 2025 at 2:59 AM
Step 4: Test your context-aware agents
This is the fun part, use Tensorlake to extract key claims from news articles, then use your @langchain.bsky.social agent to query ChromaDB and determine whether the claims are rooted in fact.
This is the fun part, use Tensorlake to extract key claims from news articles, then use your @langchain.bsky.social agent to query ChromaDB and determine whether the claims are rooted in fact.
Step 3: Contextualize Queries
Don't rely on users to make queries that are specific for your data. Instead, make sure you contextualize your query so that during hybrid search you're finding the most relevant and accurate chunks.
In our example, we used @langchain.bsky.social to help
Don't rely on users to make queries that are specific for your data. Instead, make sure you contextualize your query so that during hybrid search you're finding the most relevant and accurate chunks.
In our example, we used @langchain.bsky.social to help

August 21, 2025 at 2:59 AM
Step 3: Contextualize Queries
Don't rely on users to make queries that are specific for your data. Instead, make sure you contextualize your query so that during hybrid search you're finding the most relevant and accurate chunks.
In our example, we used @langchain.bsky.social to help
Don't rely on users to make queries that are specific for your data. Instead, make sure you contextualize your query so that during hybrid search you're finding the most relevant and accurate chunks.
In our example, we used @langchain.bsky.social to help
Step 2: Chunk, Store, and Retrieve Data
With clean, structured, and accurate data you can chunk and embed your documents in a way that is effectively and accurately retrievable by agents.
In our example, we used @chonkieai.bsky.social and ChromaDB.
With clean, structured, and accurate data you can chunk and embed your documents in a way that is effectively and accurately retrievable by agents.
In our example, we used @chonkieai.bsky.social and ChromaDB.

August 21, 2025 at 2:59 AM
Step 2: Chunk, Store, and Retrieve Data
With clean, structured, and accurate data you can chunk and embed your documents in a way that is effectively and accurately retrievable by agents.
In our example, we used @chonkieai.bsky.social and ChromaDB.
With clean, structured, and accurate data you can chunk and embed your documents in a way that is effectively and accurately retrievable by agents.
In our example, we used @chonkieai.bsky.social and ChromaDB.
Step 1: Ingest and pre-process your documents
With a single API call, you can turn messy PDFs into page-aware, table-preserving, structured context. Simply:
1. Define page classes for different documents
2. Define schemas to extract relevant data
3. Parse
With a single API call, you can turn messy PDFs into page-aware, table-preserving, structured context. Simply:
1. Define page classes for different documents
2. Define schemas to extract relevant data
3. Parse

August 21, 2025 at 2:59 AM
Step 1: Ingest and pre-process your documents
With a single API call, you can turn messy PDFs into page-aware, table-preserving, structured context. Simply:
1. Define page classes for different documents
2. Define schemas to extract relevant data
3. Parse
With a single API call, you can turn messy PDFs into page-aware, table-preserving, structured context. Simply:
1. Define page classes for different documents
2. Define schemas to extract relevant data
3. Parse
“RAG is dead” is lazy.
What’s dead is cosine‑N without a retrieval plan.
We ship advanced RAG...out of the box:
• Classify pages → target sections
• Extract structured fields → filter by form_type, fiscal_period
• Verify data; cite page/bbox
Want to know how? 🧵👇
What’s dead is cosine‑N without a retrieval plan.
We ship advanced RAG...out of the box:
• Classify pages → target sections
• Extract structured fields → filter by form_type, fiscal_period
• Verify data; cite page/bbox
Want to know how? 🧵👇

August 21, 2025 at 2:59 AM
“RAG is dead” is lazy.
What’s dead is cosine‑N without a retrieval plan.
We ship advanced RAG...out of the box:
• Classify pages → target sections
• Extract structured fields → filter by form_type, fiscal_period
• Verify data; cite page/bbox
Want to know how? 🧵👇
What’s dead is cosine‑N without a retrieval plan.
We ship advanced RAG...out of the box:
• Classify pages → target sections
• Extract structured fields → filter by form_type, fiscal_period
• Verify data; cite page/bbox
Want to know how? 🧵👇
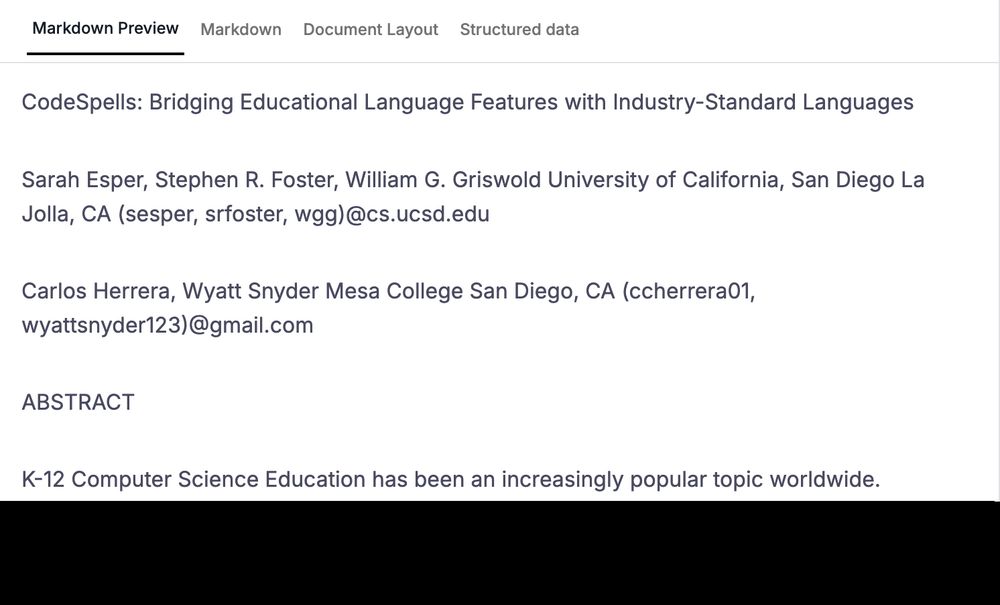
Most "unstructured" parses fail on when layout gets tricky:
multiple columns, fragmented text blocks, mixed reading order
Tensorlake doesn't.
✅ Authors parsed as one clean chunk
✅ Abstract follows, exactly as it should
Unstructured ≠ unordered
Preserve reading order. Parse with Tensorlake.
multiple columns, fragmented text blocks, mixed reading order
Tensorlake doesn't.
✅ Authors parsed as one clean chunk
✅ Abstract follows, exactly as it should
Unstructured ≠ unordered
Preserve reading order. Parse with Tensorlake.

July 14, 2025 at 4:38 PM
Most "unstructured" parses fail on when layout gets tricky:
multiple columns, fragmented text blocks, mixed reading order
Tensorlake doesn't.
✅ Authors parsed as one clean chunk
✅ Abstract follows, exactly as it should
Unstructured ≠ unordered
Preserve reading order. Parse with Tensorlake.
multiple columns, fragmented text blocks, mixed reading order
Tensorlake doesn't.
✅ Authors parsed as one clean chunk
✅ Abstract follows, exactly as it should
Unstructured ≠ unordered
Preserve reading order. Parse with Tensorlake.
🚀 We’re in the top 3 on Product Hunt today just 6.5 hours after launch!
Huge thanks to everyone supporting Tensorlake 🎉
From devs wrangling PDFs to teams automating high-stakes workflows.
If you haven’t yet, check us out 👇
Huge thanks to everyone supporting Tensorlake 🎉
From devs wrangling PDFs to teams automating high-stakes workflows.
If you haven’t yet, check us out 👇

May 16, 2025 at 1:27 PM
🚀 We’re in the top 3 on Product Hunt today just 6.5 hours after launch!
Huge thanks to everyone supporting Tensorlake 🎉
From devs wrangling PDFs to teams automating high-stakes workflows.
If you haven’t yet, check us out 👇
Huge thanks to everyone supporting Tensorlake 🎉
From devs wrangling PDFs to teams automating high-stakes workflows.
If you haven’t yet, check us out 👇
We just launched Tensorlake Cloud on Product Hunt 🎉
If you’ve dealt with messy document workflows and trying to parse complex documents (insurance claims, financial docs, multi-page forms), this is for you.
Would love your support 💚
www.producthunt.com/products/te...
If you’ve dealt with messy document workflows and trying to parse complex documents (insurance claims, financial docs, multi-page forms), this is for you.
Would love your support 💚
www.producthunt.com/products/te...

May 16, 2025 at 7:04 AM
We just launched Tensorlake Cloud on Product Hunt 🎉
If you’ve dealt with messy document workflows and trying to parse complex documents (insurance claims, financial docs, multi-page forms), this is for you.
Would love your support 💚
www.producthunt.com/products/te...
If you’ve dealt with messy document workflows and trying to parse complex documents (insurance claims, financial docs, multi-page forms), this is for you.
Would love your support 💚
www.producthunt.com/products/te...