




Tensorlake
@tensorlake.ai
Pinned
Tensorlake
@tensorlake.ai
· 8d

Document parsing benchmarks have been measuring the wrong thing.
We tested every major parser on real enterprise documents.
The results will change how you think about OCR accuracy 🧵
We tested every major parser on real enterprise documents.
The results will change how you think about OCR accuracy 🧵
Reposted by Tensorlake

The tensorlake playground was, unlike AWS textract and every other tool I have tried, able to parse my angled, low-quality scan of Norwegian pay statistics from 1926.
Not that 1926 Norwegian statistical tables is a generally useful benchmark…
Not that 1926 Norwegian statistical tables is a generally useful benchmark…
Document parsing benchmarks have been measuring the wrong thing.
We tested every major parser on real enterprise documents.
The results will change how you think about OCR accuracy 🧵
We tested every major parser on real enterprise documents.
The results will change how you think about OCR accuracy 🧵
November 5, 2025 at 7:52 PM
The tensorlake playground was, unlike AWS textract and every other tool I have tried, able to parse my angled, low-quality scan of Norwegian pay statistics from 1926.
Not that 1926 Norwegian statistical tables is a generally useful benchmark…
Not that 1926 Norwegian statistical tables is a generally useful benchmark…
Document parsing benchmarks have been measuring the wrong thing.
We tested every major parser on real enterprise documents.
The results will change how you think about OCR accuracy 🧵
We tested every major parser on real enterprise documents.
The results will change how you think about OCR accuracy 🧵
November 5, 2025 at 5:05 PM
Document parsing benchmarks have been measuring the wrong thing.
We tested every major parser on real enterprise documents.
The results will change how you think about OCR accuracy 🧵
We tested every major parser on real enterprise documents.
The results will change how you think about OCR accuracy 🧵
Want to build scalable data lakes w/ Tensorlake + @qdrant.bsky.social?
In the free Qdrant Essentials Course, learn how to:
- Architect vector-powered data lakes
- Optimize ETL pipelines
- Create knowledge graphs
- Integrate @langchain.bsky.social agents for natural language queries
t.co/OoPZswrL7z
In the free Qdrant Essentials Course, learn how to:
- Architect vector-powered data lakes
- Optimize ETL pipelines
- Create knowledge graphs
- Integrate @langchain.bsky.social agents for natural language queries
t.co/OoPZswrL7z

October 23, 2025 at 7:37 PM
Want to build scalable data lakes w/ Tensorlake + @qdrant.bsky.social?
In the free Qdrant Essentials Course, learn how to:
- Architect vector-powered data lakes
- Optimize ETL pipelines
- Create knowledge graphs
- Integrate @langchain.bsky.social agents for natural language queries
t.co/OoPZswrL7z
In the free Qdrant Essentials Course, learn how to:
- Architect vector-powered data lakes
- Optimize ETL pipelines
- Create knowledge graphs
- Integrate @langchain.bsky.social agents for natural language queries
t.co/OoPZswrL7z
New: Vision Language Models now power key document processing features
We're using VLMs for:
- Page classification in large documents
- Table/figure summarization
- Fast structured extraction (skip_ocr mode)
Here's what this means for document processing 🧵
We're using VLMs for:
- Page classification in large documents
- Table/figure summarization
- Fast structured extraction (skip_ocr mode)
Here's what this means for document processing 🧵
October 16, 2025 at 9:44 PM
New: Vision Language Models now power key document processing features
We're using VLMs for:
- Page classification in large documents
- Table/figure summarization
- Fast structured extraction (skip_ocr mode)
Here's what this means for document processing 🧵
We're using VLMs for:
- Page classification in large documents
- Table/figure summarization
- Fast structured extraction (skip_ocr mode)
Here's what this means for document processing 🧵
Reposted by Tensorlake

The company I work for, @tensorlake.ai, is hiring a couple of roles remote within the US: tensorlake.ai/careers
You might be a great fit if you like working with Rust, Python, K8s, me?, and you enjoy building products for developers.
You might be a great fit if you like working with Rust, Python, K8s, me?, and you enjoy building products for developers.

Tensorlake
Transform Data Into Knowledege
tensorlake.ai
October 14, 2025 at 10:21 PM
The company I work for, @tensorlake.ai, is hiring a couple of roles remote within the US: tensorlake.ai/careers
You might be a great fit if you like working with Rust, Python, K8s, me?, and you enjoy building products for developers.
You might be a great fit if you like working with Rust, Python, K8s, me?, and you enjoy building products for developers.
Most parsers strip all tracked changes when you extract the text.
That means:
❌ Lost audit trails
❌ Manual review of revision history
❌ No programmatic access to reviewer comments
❌ Workflows that can't route based on specific edits
That means:
❌ Lost audit trails
❌ Manual review of revision history
❌ No programmatic access to reviewer comments
❌ Workflows that can't route based on specific edits

October 10, 2025 at 5:25 PM
Most parsers strip all tracked changes when you extract the text.
That means:
❌ Lost audit trails
❌ Manual review of revision history
❌ No programmatic access to reviewer comments
❌ Workflows that can't route based on specific edits
That means:
❌ Lost audit trails
❌ Manual review of revision history
❌ No programmatic access to reviewer comments
❌ Workflows that can't route based on specific edits
OCR engines constantly mess up document hierarchy.
Section 2.2 becomes a top-level header (##) instead of nested (###).
We just shipped automatic header correction.
🧵 How it works:
Section 2.2 becomes a top-level header (##) instead of nested (###).
We just shipped automatic header correction.
🧵 How it works:

October 2, 2025 at 4:21 PM
OCR engines constantly mess up document hierarchy.
Section 2.2 becomes a top-level header (##) instead of nested (###).
We just shipped automatic header correction.
🧵 How it works:
Section 2.2 becomes a top-level header (##) instead of nested (###).
We just shipped automatic header correction.
🧵 How it works:
Citations.
When users ask "where did this come from?" your system should point to the exact page fragment...not just "file_name.pdf".
Built citation-aware RAG with spatial metadata has:
→ Parse docs with bounding boxes
→ Embed citation anchors in chunks
→ Return page numbers + coordinates
A 🧵
When users ask "where did this come from?" your system should point to the exact page fragment...not just "file_name.pdf".
Built citation-aware RAG with spatial metadata has:
→ Parse docs with bounding boxes
→ Embed citation anchors in chunks
→ Return page numbers + coordinates
A 🧵
September 19, 2025 at 5:44 PM
Citations.
When users ask "where did this come from?" your system should point to the exact page fragment...not just "file_name.pdf".
Built citation-aware RAG with spatial metadata has:
→ Parse docs with bounding boxes
→ Embed citation anchors in chunks
→ Return page numbers + coordinates
A 🧵
When users ask "where did this come from?" your system should point to the exact page fragment...not just "file_name.pdf".
Built citation-aware RAG with spatial metadata has:
→ Parse docs with bounding boxes
→ Embed citation anchors in chunks
→ Return page numbers + coordinates
A 🧵
Reposted by Tensorlake
Job update: a couple of weeks ago, I joined @tensorlake.ai full time. I’m having a lot of fun building the product with @diptanu.bsky.social and the rest of this wonderful team.
We have a few open positions if you’d like to work with us: www.linkedin.com/jobs/search/...
We have a few open positions if you’d like to work with us: www.linkedin.com/jobs/search/...
September 15, 2025 at 7:29 PM
Job update: a couple of weeks ago, I joined @tensorlake.ai full time. I’m having a lot of fun building the product with @diptanu.bsky.social and the rest of this wonderful team.
We have a few open positions if you’d like to work with us: www.linkedin.com/jobs/search/...
We have a few open positions if you’d like to work with us: www.linkedin.com/jobs/search/...
In finance, clinical trials, or performance benchmarks, dense tables contain mission-critical data.
But flatten that data like most parsers do and trust is lost.
Tensorlake restores trust by preserving structure, generating summaries for effective embeddings, and attaching evidence via b-boxes.
But flatten that data like most parsers do and trust is lost.
Tensorlake restores trust by preserving structure, generating summaries for effective embeddings, and attaching evidence via b-boxes.

September 11, 2025 at 8:00 PM
In finance, clinical trials, or performance benchmarks, dense tables contain mission-critical data.
But flatten that data like most parsers do and trust is lost.
Tensorlake restores trust by preserving structure, generating summaries for effective embeddings, and attaching evidence via b-boxes.
But flatten that data like most parsers do and trust is lost.
Tensorlake restores trust by preserving structure, generating summaries for effective embeddings, and attaching evidence via b-boxes.
“Because the AI said so” isn’t good enough.
Every answer should come with receipts (citations + context).
Learn how to make your AI correct and verifiable in this month’s Document Digest newsletter 👇
Every answer should come with receipts (citations + context).
Learn how to make your AI correct and verifiable in this month’s Document Digest newsletter 👇

The Document Digest by Tensorlake
Product updates and dev insights from the Tensorlake team.
tlake.link
September 11, 2025 at 5:53 PM
“Because the AI said so” isn’t good enough.
Every answer should come with receipts (citations + context).
Learn how to make your AI correct and verifiable in this month’s Document Digest newsletter 👇
Every answer should come with receipts (citations + context).
Learn how to make your AI correct and verifiable in this month’s Document Digest newsletter 👇
You can now login into Tensorlake using Microsoft and Azure SSO credentials.
This is the beginning of better integration with Microsoft Azure and Tensorlake.
If you are using Azure, and need better Document Ingestion and ETL for unstructured data reach out to us!
This is the beginning of better integration with Microsoft Azure and Tensorlake.
If you are using Azure, and need better Document Ingestion and ETL for unstructured data reach out to us!

September 5, 2025 at 5:49 PM
You can now login into Tensorlake using Microsoft and Azure SSO credentials.
This is the beginning of better integration with Microsoft Azure and Tensorlake.
If you are using Azure, and need better Document Ingestion and ETL for unstructured data reach out to us!
This is the beginning of better integration with Microsoft Azure and Tensorlake.
If you are using Azure, and need better Document Ingestion and ETL for unstructured data reach out to us!
To build trustworthy AI, your data needs proof.
Get citations for every field extracted with Tensorlake.
Read the blog and try our citations with the example notebooks: tlake.link/blog/citations
Get citations for every field extracted with Tensorlake.
Read the blog and try our citations with the example notebooks: tlake.link/blog/citations
September 5, 2025 at 4:30 PM
To build trustworthy AI, your data needs proof.
Get citations for every field extracted with Tensorlake.
Read the blog and try our citations with the example notebooks: tlake.link/blog/citations
Get citations for every field extracted with Tensorlake.
Read the blog and try our citations with the example notebooks: tlake.link/blog/citations
“RAG is dead” is lazy.
What’s dead is cosine‑N without a retrieval plan.
We ship advanced RAG...out of the box:
• Classify pages → target sections
• Extract structured fields → filter by form_type, fiscal_period
• Verify data; cite page/bbox
Want to know how? 🧵👇
What’s dead is cosine‑N without a retrieval plan.
We ship advanced RAG...out of the box:
• Classify pages → target sections
• Extract structured fields → filter by form_type, fiscal_period
• Verify data; cite page/bbox
Want to know how? 🧵👇

August 21, 2025 at 2:59 AM
“RAG is dead” is lazy.
What’s dead is cosine‑N without a retrieval plan.
We ship advanced RAG...out of the box:
• Classify pages → target sections
• Extract structured fields → filter by form_type, fiscal_period
• Verify data; cite page/bbox
Want to know how? 🧵👇
What’s dead is cosine‑N without a retrieval plan.
We ship advanced RAG...out of the box:
• Classify pages → target sections
• Extract structured fields → filter by form_type, fiscal_period
• Verify data; cite page/bbox
Want to know how? 🧵👇
Build a smart real estate agent (no license required).
🧠 LangGraph (by @langchain.bsky.social)
+ 📝 Tensorlake Contextual Signature Detection =
✅ Knows who signed
✅ When they signed
✅ If it’s ready to close
Full tutorial + code linked below 👇
🧠 LangGraph (by @langchain.bsky.social)
+ 📝 Tensorlake Contextual Signature Detection =
✅ Knows who signed
✅ When they signed
✅ If it’s ready to close
Full tutorial + code linked below 👇
July 29, 2025 at 2:00 AM
Build a smart real estate agent (no license required).
🧠 LangGraph (by @langchain.bsky.social)
+ 📝 Tensorlake Contextual Signature Detection =
✅ Knows who signed
✅ When they signed
✅ If it’s ready to close
Full tutorial + code linked below 👇
🧠 LangGraph (by @langchain.bsky.social)
+ 📝 Tensorlake Contextual Signature Detection =
✅ Knows who signed
✅ When they signed
✅ If it’s ready to close
Full tutorial + code linked below 👇
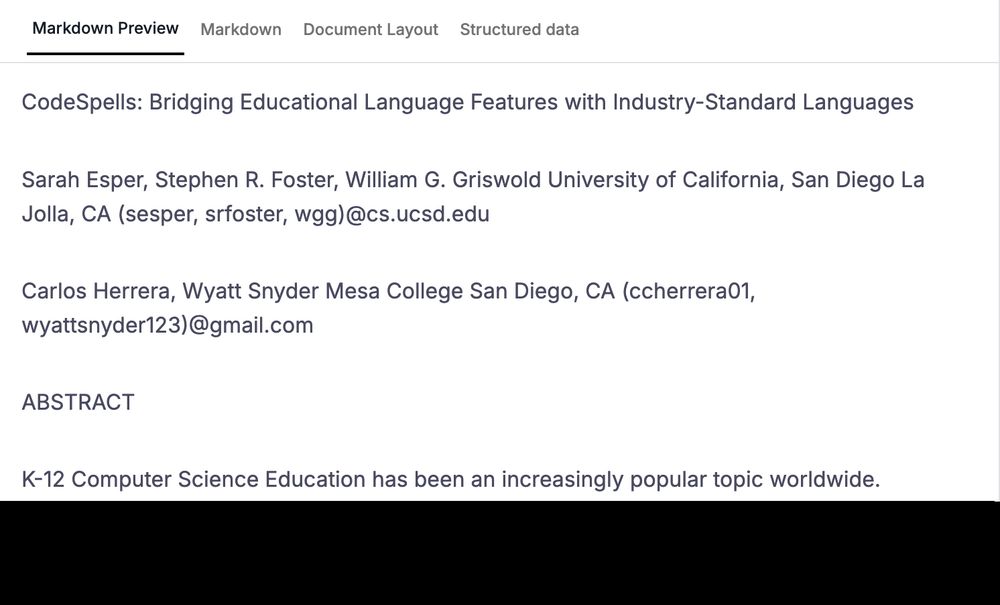
Most "unstructured" parses fail on when layout gets tricky:
multiple columns, fragmented text blocks, mixed reading order
Tensorlake doesn't.
✅ Authors parsed as one clean chunk
✅ Abstract follows, exactly as it should
Unstructured ≠ unordered
Preserve reading order. Parse with Tensorlake.
multiple columns, fragmented text blocks, mixed reading order
Tensorlake doesn't.
✅ Authors parsed as one clean chunk
✅ Abstract follows, exactly as it should
Unstructured ≠ unordered
Preserve reading order. Parse with Tensorlake.

July 14, 2025 at 4:38 PM
Most "unstructured" parses fail on when layout gets tricky:
multiple columns, fragmented text blocks, mixed reading order
Tensorlake doesn't.
✅ Authors parsed as one clean chunk
✅ Abstract follows, exactly as it should
Unstructured ≠ unordered
Preserve reading order. Parse with Tensorlake.
multiple columns, fragmented text blocks, mixed reading order
Tensorlake doesn't.
✅ Authors parsed as one clean chunk
✅ Abstract follows, exactly as it should
Unstructured ≠ unordered
Preserve reading order. Parse with Tensorlake.
Reposted by Tensorlake

Over the last few weeks we have been working a ton on some huge improvements to the @tensorlake.ai API and SDK.
They are finally live 🥳
More announcements around this is coming soon, but if you didn't see the announcement in our Slack, make sure you use v2 API and SDK 0.2.20 🙌
They are finally live 🥳
More announcements around this is coming soon, but if you didn't see the announcement in our Slack, make sure you use v2 API and SDK 0.2.20 🙌
July 10, 2025 at 1:12 AM
Over the last few weeks we have been working a ton on some huge improvements to the @tensorlake.ai API and SDK.
They are finally live 🥳
More announcements around this is coming soon, but if you didn't see the announcement in our Slack, make sure you use v2 API and SDK 0.2.20 🙌
They are finally live 🥳
More announcements around this is coming soon, but if you didn't see the announcement in our Slack, make sure you use v2 API and SDK 0.2.20 🙌
Want to see the tool in action?
Check out this quick demo or try it out in the Colab Notebook (linked in the comments)
Check out this quick demo or try it out in the Colab Notebook (linked in the comments)
June 12, 2025 at 7:41 PM
Want to see the tool in action?
Check out this quick demo or try it out in the Colab Notebook (linked in the comments)
Check out this quick demo or try it out in the Colab Notebook (linked in the comments)
Just published 🐦⬛ langchain-tensorlake 💚
A new @langchain.bsky.social tool to parse real-world documents (PDFs, scans, forms) with Tensorlake & feed structured data right into your agents.
Built for devs wrangling docs in legal, finance, healthcare & more.
Learn more: tlake.link/langchain-tool
A new @langchain.bsky.social tool to parse real-world documents (PDFs, scans, forms) with Tensorlake & feed structured data right into your agents.
Built for devs wrangling docs in legal, finance, healthcare & more.
Learn more: tlake.link/langchain-tool
Tensorlake
Transform Data Into Knowledge
www.tensorlake.ai
June 11, 2025 at 9:22 PM
Just published 🐦⬛ langchain-tensorlake 💚
A new @langchain.bsky.social tool to parse real-world documents (PDFs, scans, forms) with Tensorlake & feed structured data right into your agents.
Built for devs wrangling docs in legal, finance, healthcare & more.
Learn more: tlake.link/langchain-tool
A new @langchain.bsky.social tool to parse real-world documents (PDFs, scans, forms) with Tensorlake & feed structured data right into your agents.
Built for devs wrangling docs in legal, finance, healthcare & more.
Learn more: tlake.link/langchain-tool
Build a smart real estate agent (no license required).
🧠 LangGraph (by @langchain.bsky.social)
+ 📝 Tensorlake Contextual Signature Detection =
✅ Knows who signed
✅ When they signed
✅ If it’s ready to close
Full tutorial + code linked below 👇
🧠 LangGraph (by @langchain.bsky.social)
+ 📝 Tensorlake Contextual Signature Detection =
✅ Knows who signed
✅ When they signed
✅ If it’s ready to close
Full tutorial + code linked below 👇
June 5, 2025 at 9:03 PM
Build a smart real estate agent (no license required).
🧠 LangGraph (by @langchain.bsky.social)
+ 📝 Tensorlake Contextual Signature Detection =
✅ Knows who signed
✅ When they signed
✅ If it’s ready to close
Full tutorial + code linked below 👇
🧠 LangGraph (by @langchain.bsky.social)
+ 📝 Tensorlake Contextual Signature Detection =
✅ Knows who signed
✅ When they signed
✅ If it’s ready to close
Full tutorial + code linked below 👇
That one missing signature?
It might delay a claim or void a contract
Now in Tensorlake: Contextual Signature Detection
→ Detect handwritten, typed, or image-based
→ Trigger routing, alerts, or human review
→ API + SDK + Playground
Read the full blog post
tlake.link/signature-de...
It might delay a claim or void a contract
Now in Tensorlake: Contextual Signature Detection
→ Detect handwritten, typed, or image-based
→ Trigger routing, alerts, or human review
→ API + SDK + Playground
Read the full blog post
tlake.link/signature-de...
Tensorlake
Transform Data Into Knowledege
tlake.link
May 28, 2025 at 8:17 PM
That one missing signature?
It might delay a claim or void a contract
Now in Tensorlake: Contextual Signature Detection
→ Detect handwritten, typed, or image-based
→ Trigger routing, alerts, or human review
→ API + SDK + Playground
Read the full blog post
tlake.link/signature-de...
It might delay a claim or void a contract
Now in Tensorlake: Contextual Signature Detection
→ Detect handwritten, typed, or image-based
→ Trigger routing, alerts, or human review
→ API + SDK + Playground
Read the full blog post
tlake.link/signature-de...
21 hours later and we’re in the top 5 on Product Hunt! 🚀
Huge thanks to everyone who supported, upvoted, and shared 💚
Tensorlake is just getting started. Stay tuned - there’s so much more to come.
P.S. There's still time to upvote our launch and let us know your thoughts 👇
#AI #RAG #LLM #devtools
Huge thanks to everyone who supported, upvoted, and shared 💚
Tensorlake is just getting started. Stay tuned - there’s so much more to come.
P.S. There's still time to upvote our launch and let us know your thoughts 👇
#AI #RAG #LLM #devtools
Tensorlake - Parse documents like a human & build Python-based workflows | Product Hunt
Tensorlake Cloud is a platform for document ingestion and data orchestration. Parse real-world documents with human-like layout understanding and build Python-based workflows at scale and ready for pr...
www.producthunt.com
May 17, 2025 at 3:53 AM
🚀 We’re in the top 3 on Product Hunt today just 6.5 hours after launch!
Huge thanks to everyone supporting Tensorlake 🎉
From devs wrangling PDFs to teams automating high-stakes workflows.
If you haven’t yet, check us out 👇
Huge thanks to everyone supporting Tensorlake 🎉
From devs wrangling PDFs to teams automating high-stakes workflows.
If you haven’t yet, check us out 👇

May 16, 2025 at 1:27 PM
🚀 We’re in the top 3 on Product Hunt today just 6.5 hours after launch!
Huge thanks to everyone supporting Tensorlake 🎉
From devs wrangling PDFs to teams automating high-stakes workflows.
If you haven’t yet, check us out 👇
Huge thanks to everyone supporting Tensorlake 🎉
From devs wrangling PDFs to teams automating high-stakes workflows.
If you haven’t yet, check us out 👇
We just launched Tensorlake Cloud on Product Hunt 🎉
If you’ve dealt with messy document workflows and trying to parse complex documents (insurance claims, financial docs, multi-page forms), this is for you.
Would love your support 💚
www.producthunt.com/products/te...
If you’ve dealt with messy document workflows and trying to parse complex documents (insurance claims, financial docs, multi-page forms), this is for you.
Would love your support 💚
www.producthunt.com/products/te...

May 16, 2025 at 7:04 AM
We just launched Tensorlake Cloud on Product Hunt 🎉
If you’ve dealt with messy document workflows and trying to parse complex documents (insurance claims, financial docs, multi-page forms), this is for you.
Would love your support 💚
www.producthunt.com/products/te...
If you’ve dealt with messy document workflows and trying to parse complex documents (insurance claims, financial docs, multi-page forms), this is for you.
Would love your support 💚
www.producthunt.com/products/te...
Reposted by Tensorlake

🔥 @diptanu.bsky.social has launched the cloud hosted version of Tensorlake. This looks pretty magical. The Pydantic support is so cool. Reminds me of @prefect.io's Marvin API. But Tensorlake purpose-built parsing for structured PDF (and other) documents.


May 15, 2025 at 5:33 PM
🔥 @diptanu.bsky.social has launched the cloud hosted version of Tensorlake. This looks pretty magical. The Pydantic support is so cool. Reminds me of @prefect.io's Marvin API. But Tensorlake purpose-built parsing for structured PDF (and other) documents.