



@stanislavkozlovski.bsky.social
Thanks, it's mine. It comes off this post topicpartition.io/blog/postgre... where I focus on how PG solves so many problems at smaller scale

November 2, 2025 at 9:47 AM
Thanks, it's mine. It comes off this post topicpartition.io/blog/postgre... where I focus on how PG solves so many problems at smaller scale
What has changed since?
October 26, 2025 at 6:57 PM
What has changed since?
This was posted 15 years ago
(part 1/2)
(part 1/2)
October 26, 2025 at 6:57 PM
This was posted 15 years ago
(part 1/2)
(part 1/2)
**taps the sign**

September 29, 2025 at 9:07 PM
**taps the sign**

July 14, 2025 at 2:51 PM
a new 2 minute streaming post is sitting patiently in your inbox...
open it to learn when:
• Kafka decides what messages are visible to Consumers
• acks=all Producers receive responses
open it to learn when:
• Kafka decides what messages are visible to Consumers
• acks=all Producers receive responses
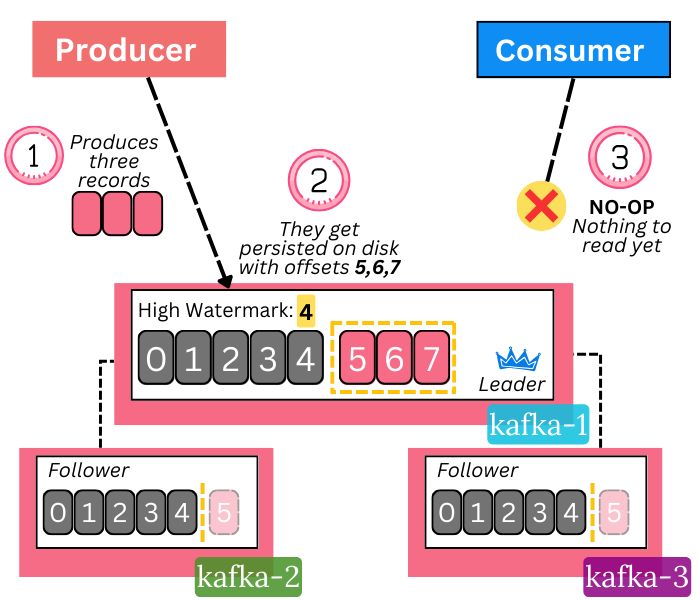
July 14, 2025 at 2:51 PM
a new 2 minute streaming post is sitting patiently in your inbox...
open it to learn when:
• Kafka decides what messages are visible to Consumers
• acks=all Producers receive responses
open it to learn when:
• Kafka decides what messages are visible to Consumers
• acks=all Producers receive responses
Similar on the topic, it's funny to see the progression of Confluent:
1. 2016: KStreams targets microservices and core apps
2. ~2020: CFLT's Microservice EDA rhetoric dies down
3. 2023: CFLT goes all in on Flink
4. 2024: CFLT markets the hell out of Flink for AI & Agents (similar to microservices)
1. 2016: KStreams targets microservices and core apps
2. ~2020: CFLT's Microservice EDA rhetoric dies down
3. 2023: CFLT goes all in on Flink
4. 2024: CFLT markets the hell out of Flink for AI & Agents (similar to microservices)

June 1, 2025 at 9:44 PM
Similar on the topic, it's funny to see the progression of Confluent:
1. 2016: KStreams targets microservices and core apps
2. ~2020: CFLT's Microservice EDA rhetoric dies down
3. 2023: CFLT goes all in on Flink
4. 2024: CFLT markets the hell out of Flink for AI & Agents (similar to microservices)
1. 2016: KStreams targets microservices and core apps
2. ~2020: CFLT's Microservice EDA rhetoric dies down
3. 2023: CFLT goes all in on Flink
4. 2024: CFLT markets the hell out of Flink for AI & Agents (similar to microservices)
I find this quote about the stream processing winner fascinating when comparing to the original motivation behind Kafka Streams.
The truth is clients WERE the real winner. Majority of apps are using those APIs and not much more.
The truth is clients WERE the real winner. Majority of apps are using those APIs and not much more.


June 1, 2025 at 9:44 PM
I find this quote about the stream processing winner fascinating when comparing to the original motivation behind Kafka Streams.
The truth is clients WERE the real winner. Majority of apps are using those APIs and not much more.
The truth is clients WERE the real winner. Majority of apps are using those APIs and not much more.
I just published a 2 hour and 30 minutes long technical deep dive podcast with two of the Diskless proposal authors.
The podcast is a treasure trove chock full of deep technical insights.
There is no better resource online about KIP-1150 🔥
👉 www.youtube.com/watch?v=hrM...
The podcast is a treasure trove chock full of deep technical insights.
There is no better resource online about KIP-1150 🔥
👉 www.youtube.com/watch?v=hrM...

May 18, 2025 at 2:21 PM
I just published a 2 hour and 30 minutes long technical deep dive podcast with two of the Diskless proposal authors.
The podcast is a treasure trove chock full of deep technical insights.
There is no better resource online about KIP-1150 🔥
👉 www.youtube.com/watch?v=hrM...
The podcast is a treasure trove chock full of deep technical insights.
There is no better resource online about KIP-1150 🔥
👉 www.youtube.com/watch?v=hrM...
Apache Kafka has been on a Diskless craze in the last two years:
• 2023: WarpStream launched
• 2024: Confluent bought them for $220M+
• 2025: Aiven published a KIP to the open source project to introduce the same type of leaderless, direct-to-S3 topics
• 2023: WarpStream launched
• 2024: Confluent bought them for $220M+
• 2025: Aiven published a KIP to the open source project to introduce the same type of leaderless, direct-to-S3 topics

May 18, 2025 at 2:21 PM
Apache Kafka has been on a Diskless craze in the last two years:
• 2023: WarpStream launched
• 2024: Confluent bought them for $220M+
• 2025: Aiven published a KIP to the open source project to introduce the same type of leaderless, direct-to-S3 topics
• 2023: WarpStream launched
• 2024: Confluent bought them for $220M+
• 2025: Aiven published a KIP to the open source project to introduce the same type of leaderless, direct-to-S3 topics
Fin 🎬
If you enjoyed it and would like to see more, please support it by doing two simple things:
1. like
2. repost
It takes 6 seconds to do, writing this takes me 6+ hours. 🙏
If you enjoyed it and would like to see more, please support it by doing two simple things:
1. like
2. repost
It takes 6 seconds to do, writing this takes me 6+ hours. 🙏

April 11, 2025 at 1:44 PM
Fin 🎬
If you enjoyed it and would like to see more, please support it by doing two simple things:
1. like
2. repost
It takes 6 seconds to do, writing this takes me 6+ hours. 🙏
If you enjoyed it and would like to see more, please support it by doing two simple things:
1. like
2. repost
It takes 6 seconds to do, writing this takes me 6+ hours. 🙏
AWS will charge you $72/TB to read data out of S3 from another cloud.
It's "open", yes.
You could query it from any engine. You could query it from another cloud.
But you practically never will. It would bankrupt you.
It's "open", yes.
You could query it from any engine. You could query it from another cloud.
But you practically never will. It would bankrupt you.

April 11, 2025 at 1:44 PM
AWS will charge you $72/TB to read data out of S3 from another cloud.
It's "open", yes.
You could query it from any engine. You could query it from another cloud.
But you practically never will. It would bankrupt you.
It's "open", yes.
You could query it from any engine. You could query it from another cloud.
But you practically never will. It would bankrupt you.
Zero Egress pricing enables the zero copy data stack that the open lakehouse vision promises.
It means that you do NOT have to spend millions in networking costs to use your data with the right engine.
You can store your data (once) in R2 and query it from anywhere, for free.
It means that you do NOT have to spend millions in networking costs to use your data with the right engine.
You can store your data (once) in R2 and query it from anywhere, for free.

April 11, 2025 at 1:44 PM
Zero Egress pricing enables the zero copy data stack that the open lakehouse vision promises.
It means that you do NOT have to spend millions in networking costs to use your data with the right engine.
You can store your data (once) in R2 and query it from anywhere, for free.
It means that you do NOT have to spend millions in networking costs to use your data with the right engine.
You can store your data (once) in R2 and query it from anywhere, for free.
The Killer Feature is the free egress.
Every major cloud famously charges you obscene amounts on data transfer - it's the item they make the fattest margin on.
Worse off - it's how they lock you in within their ecosystem.
CloudFlare doesn’t. 💪
Every major cloud famously charges you obscene amounts on data transfer - it's the item they make the fattest margin on.
Worse off - it's how they lock you in within their ecosystem.
CloudFlare doesn’t. 💪


April 11, 2025 at 1:44 PM
The Killer Feature is the free egress.
Every major cloud famously charges you obscene amounts on data transfer - it's the item they make the fattest margin on.
Worse off - it's how they lock you in within their ecosystem.
CloudFlare doesn’t. 💪
Every major cloud famously charges you obscene amounts on data transfer - it's the item they make the fattest margin on.
Worse off - it's how they lock you in within their ecosystem.
CloudFlare doesn’t. 💪
It's priced somewhat competitively.
But this cost isn't what matters.
The thing that makes R2 stand out is what architectures it unlocks.
But this cost isn't what matters.
The thing that makes R2 stand out is what architectures it unlocks.

April 11, 2025 at 1:44 PM
It's priced somewhat competitively.
But this cost isn't what matters.
The thing that makes R2 stand out is what architectures it unlocks.
But this cost isn't what matters.
The thing that makes R2 stand out is what architectures it unlocks.
Do we really need Yet Another Catalog? 🙄
Every vendor is competing at that level, because it's one of the only places where you can lock-in and extract permanent value from Iceberg users.
But I believe CloudFlare offers something that others do not (and cannot).
Every vendor is competing at that level, because it's one of the only places where you can lock-in and extract permanent value from Iceberg users.
But I believe CloudFlare offers something that others do not (and cannot).

April 11, 2025 at 1:44 PM
Do we really need Yet Another Catalog? 🙄
Every vendor is competing at that level, because it's one of the only places where you can lock-in and extract permanent value from Iceberg users.
But I believe CloudFlare offers something that others do not (and cannot).
Every vendor is competing at that level, because it's one of the only places where you can lock-in and extract permanent value from Iceberg users.
But I believe CloudFlare offers something that others do not (and cannot).
An Iceberg catalog simply gatekeeps access to your underlying Iceberg storage files.
All access goes through it, ensuring:
• thread-safe access from multiple query engines at once 👌
• single source of truth and enforcement for ACLs 🔐
• where to store data, versioning, etc.
All access goes through it, ensuring:
• thread-safe access from multiple query engines at once 👌
• single source of truth and enforcement for ACLs 🔐
• where to store data, versioning, etc.

April 11, 2025 at 1:44 PM
An Iceberg catalog simply gatekeeps access to your underlying Iceberg storage files.
All access goes through it, ensuring:
• thread-safe access from multiple query engines at once 👌
• single source of truth and enforcement for ACLs 🔐
• where to store data, versioning, etc.
All access goes through it, ensuring:
• thread-safe access from multiple query engines at once 👌
• single source of truth and enforcement for ACLs 🔐
• where to store data, versioning, etc.
In case you don't know, CloudFlare released an S3-compatible object store called R2 in 2022.
Yesterday, they announced a managed Iceberg product: R2 Data Catalog.
It's an Iceberg REST catalog, which means it integrates natively with Iceberg-supported query engines. 🧊
Yesterday, they announced a managed Iceberg product: R2 Data Catalog.
It's an Iceberg REST catalog, which means it integrates natively with Iceberg-supported query engines. 🧊

April 11, 2025 at 1:44 PM
In case you don't know, CloudFlare released an S3-compatible object store called R2 in 2022.
Yesterday, they announced a managed Iceberg product: R2 Data Catalog.
It's an Iceberg REST catalog, which means it integrates natively with Iceberg-supported query engines. 🧊
Yesterday, they announced a managed Iceberg product: R2 Data Catalog.
It's an Iceberg REST catalog, which means it integrates natively with Iceberg-supported query engines. 🧊
When Iceberg's largest competitor (Databrick’s Delta Lake table format) spends $1-2 billion to acquire a $1-4M revenue startup by the creators of Iceberg...
That's when you know it won. 👑
Today - Iceberg is the standard. The only question now is how are you going to use it?
That's when you know it won. 👑
Today - Iceberg is the standard. The only question now is how are you going to use it?

April 11, 2025 at 1:44 PM
When Iceberg's largest competitor (Databrick’s Delta Lake table format) spends $1-2 billion to acquire a $1-4M revenue startup by the creators of Iceberg...
That's when you know it won. 👑
Today - Iceberg is the standard. The only question now is how are you going to use it?
That's when you know it won. 👑
Today - Iceberg is the standard. The only question now is how are you going to use it?
What's Iceberg? 🧊
An open table format. It enhances file formats like Parquet by adding extra layers of metadata that enable ACID transactions and more.
It decouples the storage layer (data) from the query layers (engines) that use it - called the headless data architecture.
An open table format. It enhances file formats like Parquet by adding extra layers of metadata that enable ACID transactions and more.
It decouples the storage layer (data) from the query layers (engines) that use it - called the headless data architecture.

April 11, 2025 at 1:44 PM
What's Iceberg? 🧊
An open table format. It enhances file formats like Parquet by adding extra layers of metadata that enable ACID transactions and more.
It decouples the storage layer (data) from the query layers (engines) that use it - called the headless data architecture.
An open table format. It enhances file formats like Parquet by adding extra layers of metadata that enable ACID transactions and more.
It decouples the storage layer (data) from the query layers (engines) that use it - called the headless data architecture.
Yesterday, CloudFlare dropped a bomb that I believe may change the future of Lakehouse storage.
R2 + Iceberg should become the de-facto choice for hybrid and multi-cloud data lakehouse architectures.
Here's why it may break the cloud monopoly 🧵
R2 + Iceberg should become the de-facto choice for hybrid and multi-cloud data lakehouse architectures.
Here's why it may break the cloud monopoly 🧵
April 11, 2025 at 1:44 PM
Yesterday, CloudFlare dropped a bomb that I believe may change the future of Lakehouse storage.
R2 + Iceberg should become the de-facto choice for hybrid and multi-cloud data lakehouse architectures.
Here's why it may break the cloud monopoly 🧵
R2 + Iceberg should become the de-facto choice for hybrid and multi-cloud data lakehouse architectures.
Here's why it may break the cloud monopoly 🧵
If you'd like to see the Kafka community keep growing like this, you can help it out in a simple way:
• boost this thread by reposting to your network! 💥
I'll leave you with a Taiwan Barbet, a special endemic species you can only find in that country. 🦜🇹🇼
• boost this thread by reposting to your network! 💥
I'll leave you with a Taiwan Barbet, a special endemic species you can only find in that country. 🦜🇹🇼


February 21, 2025 at 4:56 PM
If you'd like to see the Kafka community keep growing like this, you can help it out in a simple way:
• boost this thread by reposting to your network! 💥
I'll leave you with a Taiwan Barbet, a special endemic species you can only find in that country. 🦜🇹🇼
• boost this thread by reposting to your network! 💥
I'll leave you with a Taiwan Barbet, a special endemic species you can only find in that country. 🦜🇹🇼
Chia-Ping's next task?
Help his closest community members become Apache Kafka committers and build their careers. 👍
A 5000+ community mixing established and up-and-coming committers goes to show - one person can create splash waves in open source software. 🔥
Help his closest community members become Apache Kafka committers and build their careers. 👍
A 5000+ community mixing established and up-and-coming committers goes to show - one person can create splash waves in open source software. 🔥

February 21, 2025 at 4:56 PM
Chia-Ping's next task?
Help his closest community members become Apache Kafka committers and build their careers. 👍
A 5000+ community mixing established and up-and-coming committers goes to show - one person can create splash waves in open source software. 🔥
Help his closest community members become Apache Kafka committers and build their careers. 👍
A 5000+ community mixing established and up-and-coming committers goes to show - one person can create splash waves in open source software. 🔥
Together, this community has merged more than 591 PRs in Apache Kafka! 🫶
Chia-Ping did all of this this while being a committer and PMC member in Apache Kafka, Apache HBase and Apache Yunikorn 🤯
Just in Kafka he’s created 600+ issues and reviewed 1,600+ commits 👀
Chia-Ping did all of this this while being a committer and PMC member in Apache Kafka, Apache HBase and Apache Yunikorn 🤯
Just in Kafka he’s created 600+ issues and reviewed 1,600+ commits 👀
February 21, 2025 at 4:56 PM
Together, this community has merged more than 591 PRs in Apache Kafka! 🫶
Chia-Ping did all of this this while being a committer and PMC member in Apache Kafka, Apache HBase and Apache Yunikorn 🤯
Just in Kafka he’s created 600+ issues and reviewed 1,600+ commits 👀
Chia-Ping did all of this this while being a committer and PMC member in Apache Kafka, Apache HBase and Apache Yunikorn 🤯
Just in Kafka he’s created 600+ issues and reviewed 1,600+ commits 👀
I joined their Slack and was blown away by the activity. It has multiple channels for different open-source projects.
The Kafka channel was super active - every day you would see discussions on 5+ different JIRAs.
The Kafka channel was super active - every day you would see discussions on 5+ different JIRAs.

February 21, 2025 at 4:56 PM
I joined their Slack and was blown away by the activity. It has multiple channels for different open-source projects.
The Kafka channel was super active - every day you would see discussions on 5+ different JIRAs.
The Kafka channel was super active - every day you would see discussions on 5+ different JIRAs.