



Shobhita Sundaram
@shobsund.bsky.social
PhD student at MIT working on deep learning (representation learning, generative models, synthetic data, alignment).
ssundaram21.github.io
ssundaram21.github.io
What if we had collected more than 3 real images initially?
We compare DINOv2-P performance trained on real only vs real + syn, as the real dataset size scales. Even as real-trained performance saturates, synthetic data still leads to performance improvements!
(9/n)
We compare DINOv2-P performance trained on real only vs real + syn, as the real dataset size scales. Even as real-trained performance saturates, synthetic data still leads to performance improvements!
(9/n)

December 23, 2024 at 5:26 PM
What if we had collected more than 3 real images initially?
We compare DINOv2-P performance trained on real only vs real + syn, as the real dataset size scales. Even as real-trained performance saturates, synthetic data still leads to performance improvements!
(9/n)
We compare DINOv2-P performance trained on real only vs real + syn, as the real dataset size scales. Even as real-trained performance saturates, synthetic data still leads to performance improvements!
(9/n)
Across backbones, datasets and tasks, *personalized reps (-P) consistently outperform general reps* (green = better performance).
Relative improvements (avg across datasets) can be significant: DINOv2 detection +48%, CLIP Retrieval +34%, MAE classification +106%.
(7/n)
Relative improvements (avg across datasets) can be significant: DINOv2 detection +48%, CLIP Retrieval +34%, MAE classification +106%.
(7/n)

December 23, 2024 at 5:26 PM
Across backbones, datasets and tasks, *personalized reps (-P) consistently outperform general reps* (green = better performance).
Relative improvements (avg across datasets) can be significant: DINOv2 detection +48%, CLIP Retrieval +34%, MAE classification +106%.
(7/n)
Relative improvements (avg across datasets) can be significant: DINOv2 detection +48%, CLIP Retrieval +34%, MAE classification +106%.
(7/n)
First, some qualitative results:
Dense prediction maps from personalized reps highlight and localize the target object much more clearly than pretrained reps, even with occlusions or similar nearby objects.
(object highlighted in test images for visualization)
(6/n)
Dense prediction maps from personalized reps highlight and localize the target object much more clearly than pretrained reps, even with occlusions or similar nearby objects.
(object highlighted in test images for visualization)
(6/n)

December 23, 2024 at 5:26 PM
First, some qualitative results:
Dense prediction maps from personalized reps highlight and localize the target object much more clearly than pretrained reps, even with occlusions or similar nearby objects.
(object highlighted in test images for visualization)
(6/n)
Dense prediction maps from personalized reps highlight and localize the target object much more clearly than pretrained reps, even with occlusions or similar nearby objects.
(object highlighted in test images for visualization)
(6/n)
What about datasets?
Introducing *PODS: Personal Object Discrimination Suite* - a dataset for personalized vision with 100 objects and 4 test splits w/ distribution shifts to test generalization!
We also reformulate DogFaceNet and DeepFashion2 for real-world evaluation.
(5/n)
Introducing *PODS: Personal Object Discrimination Suite* - a dataset for personalized vision with 100 objects and 4 test splits w/ distribution shifts to test generalization!
We also reformulate DogFaceNet and DeepFashion2 for real-world evaluation.
(5/n)

December 23, 2024 at 5:26 PM
What about datasets?
Introducing *PODS: Personal Object Discrimination Suite* - a dataset for personalized vision with 100 objects and 4 test splits w/ distribution shifts to test generalization!
We also reformulate DogFaceNet and DeepFashion2 for real-world evaluation.
(5/n)
Introducing *PODS: Personal Object Discrimination Suite* - a dataset for personalized vision with 100 objects and 4 test splits w/ distribution shifts to test generalization!
We also reformulate DogFaceNet and DeepFashion2 for real-world evaluation.
(5/n)
For eval, we apply personalized representations to four tasks (classification, retrieval, detection, segmentation) using classic few-shot setups, and compare them to pretrained models.
(4/n)
(4/n)

December 23, 2024 at 5:26 PM
For eval, we apply personalized representations to four tasks (classification, retrieval, detection, segmentation) using classic few-shot setups, and compare them to pretrained models.
(4/n)
(4/n)
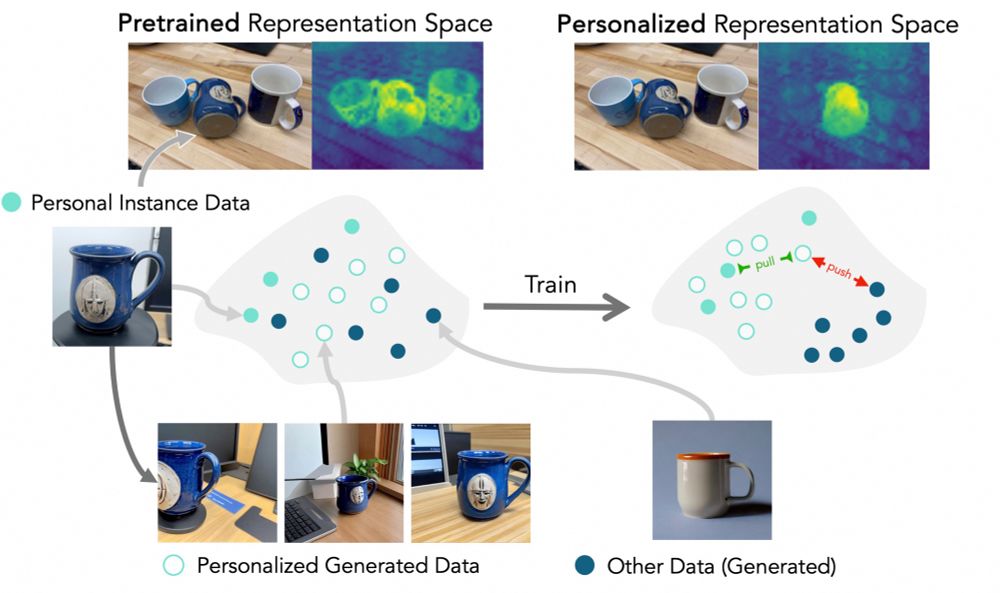
We introduce a 3-step training pipeline:
1. Prepare a personalized generator (e.g. DreamBooth) using the small real-image dataset.
2. Generate positives (target instance) and negatives (images of same object type).
3. Contrastively fine-tune a general-purpose model w/ LoRA
(3/n)
1. Prepare a personalized generator (e.g. DreamBooth) using the small real-image dataset.
2. Generate positives (target instance) and negatives (images of same object type).
3. Contrastively fine-tune a general-purpose model w/ LoRA
(3/n)

December 23, 2024 at 5:26 PM
We introduce a 3-step training pipeline:
1. Prepare a personalized generator (e.g. DreamBooth) using the small real-image dataset.
2. Generate positives (target instance) and negatives (images of same object type).
3. Contrastively fine-tune a general-purpose model w/ LoRA
(3/n)
1. Prepare a personalized generator (e.g. DreamBooth) using the small real-image dataset.
2. Generate positives (target instance) and negatives (images of same object type).
3. Contrastively fine-tune a general-purpose model w/ LoRA
(3/n)
Personal vision tasks–like detecting *your mug*--are hard; they’re data scarce and fine-grained.
In our new paper, we show you can adapt general-purpose vision models to these tasks from just three photos!
📝: arxiv.org/abs/2412.16156
💻: github.com/ssundaram21/...
(1/n)
In our new paper, we show you can adapt general-purpose vision models to these tasks from just three photos!
📝: arxiv.org/abs/2412.16156
💻: github.com/ssundaram21/...
(1/n)
December 23, 2024 at 5:26 PM
Personal vision tasks–like detecting *your mug*--are hard; they’re data scarce and fine-grained.
In our new paper, we show you can adapt general-purpose vision models to these tasks from just three photos!
📝: arxiv.org/abs/2412.16156
💻: github.com/ssundaram21/...
(1/n)
In our new paper, we show you can adapt general-purpose vision models to these tasks from just three photos!
📝: arxiv.org/abs/2412.16156
💻: github.com/ssundaram21/...
(1/n)