




Ryan P. Badman
@ryanpaulbadman1.bsky.social
Postdoc in Kanaka Rajan laboratory at Harvard Medical Neurobiology & Kempner Institute - Theoretical/Comp Neuro. Background includes comp neuro, social neuro, cultural psychology, biophysics.
Reposted by Ryan P. Badman

We wrote a little #NeuroAI piece about in-context learning & neural dynamics vs. continual learning & plasticity, both mechanisms to flexibly adapt to changing environments:
arxiv.org/abs/2507.02103
We relate this to non-stationary rule learning tasks with rapid performance jumps.
Feedback welcome!
arxiv.org/abs/2507.02103
We relate this to non-stationary rule learning tasks with rapid performance jumps.
Feedback welcome!

What Neuroscience Can Teach AI About Learning in Continuously Changing Environments
Modern AI models, such as large language models, are usually trained once on a huge corpus of data, potentially fine-tuned for a specific task, and then deployed with fixed parameters. Their training ...
arxiv.org
July 6, 2025 at 10:18 AM
We wrote a little #NeuroAI piece about in-context learning & neural dynamics vs. continual learning & plasticity, both mechanisms to flexibly adapt to changing environments:
arxiv.org/abs/2507.02103
We relate this to non-stationary rule learning tasks with rapid performance jumps.
Feedback welcome!
arxiv.org/abs/2507.02103
We relate this to non-stationary rule learning tasks with rapid performance jumps.
Feedback welcome!
Reposted by Ryan P. Badman

(1/7) New preprint from Rajan lab! 🧠🤖
@ryanpaulbadman1.bsky.social & Riley Simmons-Edler show–through cog sci, neuro & ethology–how an AI agent with fewer ‘neurons’ than an insect can forage, find safety & dodge predators in a virtual world. Here's what we built
Preprint: arxiv.org/pdf/2506.06981
@ryanpaulbadman1.bsky.social & Riley Simmons-Edler show–through cog sci, neuro & ethology–how an AI agent with fewer ‘neurons’ than an insect can forage, find safety & dodge predators in a virtual world. Here's what we built
Preprint: arxiv.org/pdf/2506.06981

July 2, 2025 at 6:34 PM
(1/7) New preprint from Rajan lab! 🧠🤖
@ryanpaulbadman1.bsky.social & Riley Simmons-Edler show–through cog sci, neuro & ethology–how an AI agent with fewer ‘neurons’ than an insect can forage, find safety & dodge predators in a virtual world. Here's what we built
Preprint: arxiv.org/pdf/2506.06981
@ryanpaulbadman1.bsky.social & Riley Simmons-Edler show–through cog sci, neuro & ethology–how an AI agent with fewer ‘neurons’ than an insect can forage, find safety & dodge predators in a virtual world. Here's what we built
Preprint: arxiv.org/pdf/2506.06981
Reposted by Ryan P. Badman

Humans and animals can rapidly learn in new environments. What computations support this? We study the mechanisms of in-context reinforcement learning in transformers, and propose how episodic memory can support rapid learning. Work w/ @kanakarajanphd.bsky.social : arxiv.org/abs/2506.19686

From memories to maps: Mechanisms of in context reinforcement learning in transformers
Humans and animals show remarkable learning efficiency, adapting to new environments with minimal experience. This capability is not well captured by standard reinforcement learning algorithms that re...
arxiv.org
June 26, 2025 at 7:01 PM
Humans and animals can rapidly learn in new environments. What computations support this? We study the mechanisms of in-context reinforcement learning in transformers, and propose how episodic memory can support rapid learning. Work w/ @kanakarajanphd.bsky.social : arxiv.org/abs/2506.19686
Reposted by Ryan P. Badman

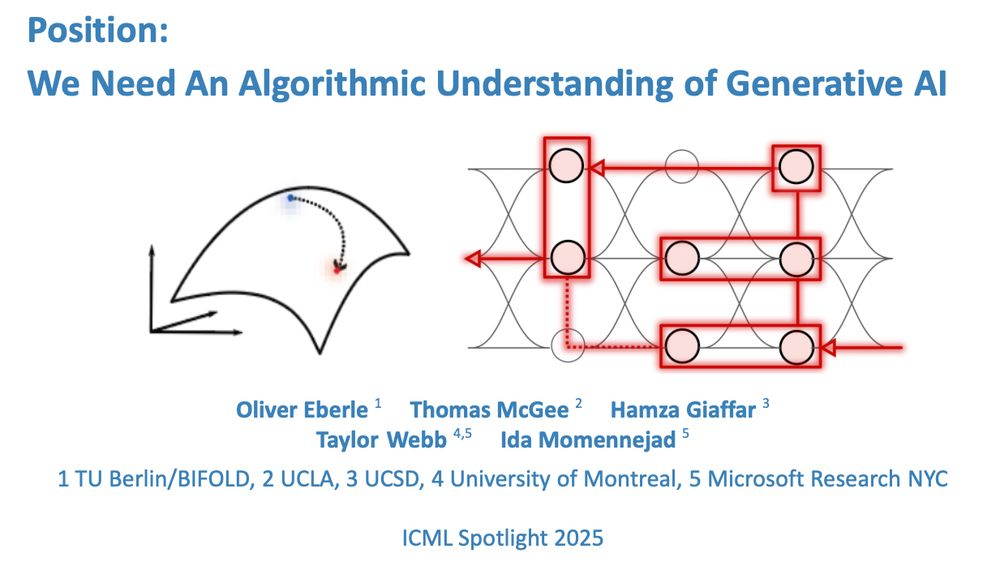
Pleased to share our ICML Spotlight with @eberleoliver.bsky.social, Thomas McGee, Hamza Giaffar, @taylorwwebb.bsky.social.
Position: We Need An Algorithmic Understanding of Generative AI
What algorithms do LLMs actually learn and use to solve problems?🧵1/n
openreview.net/forum?id=eax...
Position: We Need An Algorithmic Understanding of Generative AI
What algorithms do LLMs actually learn and use to solve problems?🧵1/n
openreview.net/forum?id=eax...
June 20, 2025 at 3:48 PM
Pleased to share our ICML Spotlight with @eberleoliver.bsky.social, Thomas McGee, Hamza Giaffar, @taylorwwebb.bsky.social.
Position: We Need An Algorithmic Understanding of Generative AI
What algorithms do LLMs actually learn and use to solve problems?🧵1/n
openreview.net/forum?id=eax...
Position: We Need An Algorithmic Understanding of Generative AI
What algorithms do LLMs actually learn and use to solve problems?🧵1/n
openreview.net/forum?id=eax...
Reposted by Ryan P. Badman
Very proud of @rtpramod.bsky.social and the rest of our team for this lovely work showing that the brain's Physics Network represents object-to-object contact and predicted future events:

Thrilled to announce our new publication titled 'Decoding predicted future states from the brain's physics engine' with @emiecz.bsky.social, Cyn X. Fang, @nancykanwisher.bsky.social, @joshtenenbaum.bsky.social
www.science.org/doi/full/10....
(1/n)
www.science.org/doi/full/10....
(1/n)
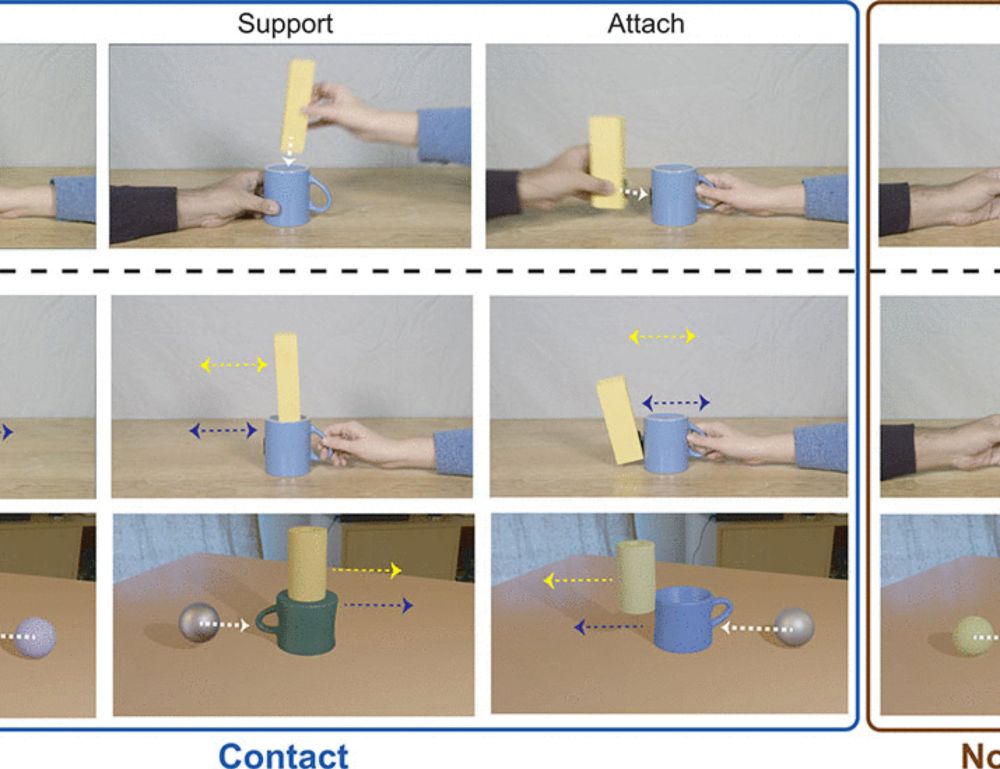
Decoding predicted future states from the brain’s “physics engine”
Using fMRI in humans, this study provides evidence for future state prediction in brain regions involved in physical reasoning.
www.science.org
June 19, 2025 at 12:14 PM
Very proud of @rtpramod.bsky.social and the rest of our team for this lovely work showing that the brain's Physics Network represents object-to-object contact and predicted future events:
Reposted by Ryan P. Badman

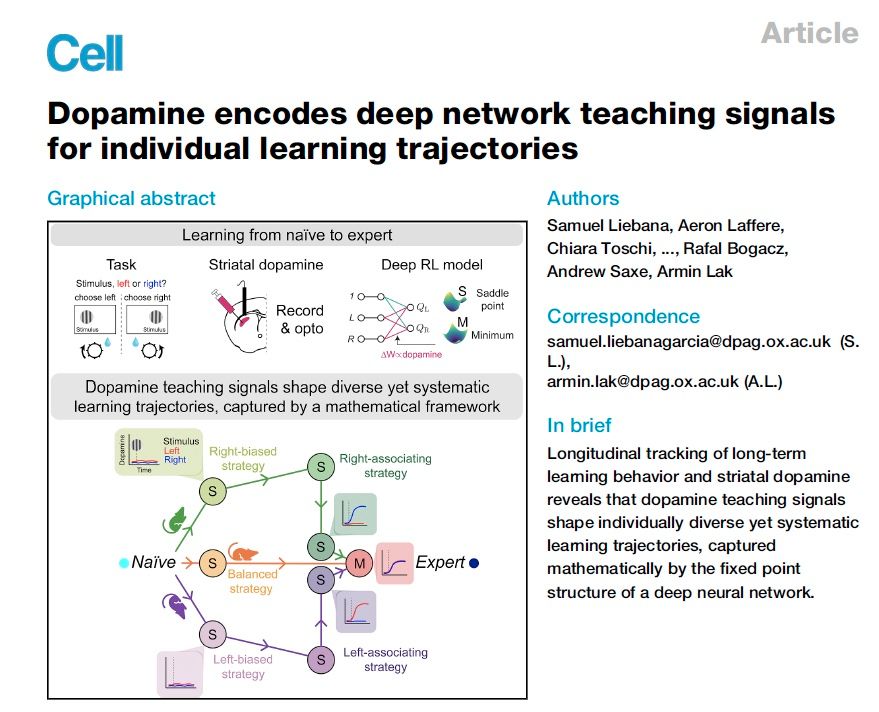
Our work, out at Cell, shows that the brain’s dopamine signals teach each individual a unique learning trajectory. Collaborative experiment-theory effort, led by Sam Liebana in the lab. The first experiment my lab started just shy of 6y ago & v excited to see it out: www.cell.com/cell/fulltex...
June 11, 2025 at 3:18 PM
Our work, out at Cell, shows that the brain’s dopamine signals teach each individual a unique learning trajectory. Collaborative experiment-theory effort, led by Sam Liebana in the lab. The first experiment my lab started just shy of 6y ago & v excited to see it out: www.cell.com/cell/fulltex...
Reposted by Ryan P. Badman

For almost a decade, there's been a lot of (justified) hand-wringing and paper-writing about fairness issues in AI. This case gets to the heart of a very important question - how much of that work has materially improved the lives of real people?
Grateful for this careful & honest investigation.
Grateful for this careful & honest investigation.

New from me @gabrielgeiger.bsky.social + Justin-Casimir Braun:
Amsterdam believed that it could build a #predictiveAI for welfare fraud that would ALSO be fair, unbiased, & a positive case study for #ResponsibleAI. It didn't work.
Our deep dive why: www.technologyreview.com/2025/06/11/1...
Amsterdam believed that it could build a #predictiveAI for welfare fraud that would ALSO be fair, unbiased, & a positive case study for #ResponsibleAI. It didn't work.
Our deep dive why: www.technologyreview.com/2025/06/11/1...

Inside Amsterdam’s high-stakes experiment to create fair welfare AI
The Dutch city thought it could break a decade-long trend of implementing discriminatory algorithms. Its failure raises the question: can these programs ever be fair?
www.technologyreview.com
June 11, 2025 at 10:58 PM
For almost a decade, there's been a lot of (justified) hand-wringing and paper-writing about fairness issues in AI. This case gets to the heart of a very important question - how much of that work has materially improved the lives of real people?
Grateful for this careful & honest investigation.
Grateful for this careful & honest investigation.
Our new preprint from Rajan lab (Harvard):
"Deep RL Needs Deep Behavior Analysis: Exploring Implicit Planning by Model-Free Agents in Open-Ended Environments"
Sophisticated & sometimes insect-like planning, exploration, predator evasion, and foraging strategies by DRL.
arxiv.org/abs/2506.06981
"Deep RL Needs Deep Behavior Analysis: Exploring Implicit Planning by Model-Free Agents in Open-Ended Environments"
Sophisticated & sometimes insect-like planning, exploration, predator evasion, and foraging strategies by DRL.
arxiv.org/abs/2506.06981

Deep RL Needs Deep Behavior Analysis: Exploring Implicit Planning by Model-Free Agents in Open-Ended Environments
Understanding the behavior of deep reinforcement learning (DRL) agents -- particularly as task and agent sophistication increase -- requires more than simple comparison of reward curves, yet standard ...
arxiv.org
June 10, 2025 at 2:46 PM
Our new preprint from Rajan lab (Harvard):
"Deep RL Needs Deep Behavior Analysis: Exploring Implicit Planning by Model-Free Agents in Open-Ended Environments"
Sophisticated & sometimes insect-like planning, exploration, predator evasion, and foraging strategies by DRL.
arxiv.org/abs/2506.06981
"Deep RL Needs Deep Behavior Analysis: Exploring Implicit Planning by Model-Free Agents in Open-Ended Environments"
Sophisticated & sometimes insect-like planning, exploration, predator evasion, and foraging strategies by DRL.
arxiv.org/abs/2506.06981
A big challenge for comp social neuro is to go to more naturalistic small groups while still doing controlled, goal-oriented experiment & analysis. We present a strong effort in that direction (from RIKEN) showing how humans balance memory, reciprocity, value. w/ fMRI www.biorxiv.org/content/10.1...
January 23, 2024 at 5:18 AM
A big challenge for comp social neuro is to go to more naturalistic small groups while still doing controlled, goal-oriented experiment & analysis. We present a strong effort in that direction (from RIKEN) showing how humans balance memory, reciprocity, value. w/ fMRI www.biorxiv.org/content/10.1...
"We find that all five studied off-the-shelf [military-related] LLMs show forms of escalation and difficult-to-predict escalation patterns.. models tend to develop arms-race dynamics, leading to greater conflict, and in rare cases, even to the deployment of nuclear weapons." arxiv.org/abs/2401.03408
January 13, 2024 at 5:40 PM
"We find that all five studied off-the-shelf [military-related] LLMs show forms of escalation and difficult-to-predict escalation patterns.. models tend to develop arms-race dynamics, leading to greater conflict, and in rare cases, even to the deployment of nuclear weapons." arxiv.org/abs/2401.03408
"In contrast to past systematic replication efforts.. replication attempts here produced the expected effects with significance testing (P < 0.05) in 86% of attempts... justifies confidence in rigour-enhancing methods to increase the replicability of new discoveries"
www.nature.com/articles/s41...
www.nature.com/articles/s41...
November 19, 2023 at 5:29 AM
"In contrast to past systematic replication efforts.. replication attempts here produced the expected effects with significance testing (P < 0.05) in 86% of attempts... justifies confidence in rigour-enhancing methods to increase the replicability of new discoveries"
www.nature.com/articles/s41...
www.nature.com/articles/s41...
"We show that even in a simple, idealised network model, many mechanistically different plasticity rules are equally compatible with empirical data... Our results suggest the need for a shift in the study of plasticity rules"
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...
November 5, 2023 at 11:11 PM
"We show that even in a simple, idealised network model, many mechanistically different plasticity rules are equally compatible with empirical data... Our results suggest the need for a shift in the study of plasticity rules"
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...
Reposted by Ryan P. Badman

Next we created a nonlinear latent variable model of OFC activity in our task using CEBRA, the awesome new method from @trackingactions.bsky.social' lab, to understand how the task is encoded in the neural circuit at the level of aggregate neural dynamics
October 14, 2023 at 4:06 PM
Next we created a nonlinear latent variable model of OFC activity in our task using CEBRA, the awesome new method from @trackingactions.bsky.social' lab, to understand how the task is encoded in the neural circuit at the level of aggregate neural dynamics
Reposted by Ryan P. Badman
Absolutely thrilled to share my postdoc work in the Axel lab. We found odor-evoked representations of the intrinsic value of information in mouse orbitofrontal cortex and showed that mice desire knowledge as its own reward. Now on bioRxiv! www.biorxiv.org/content/10.1...

Representations of information value in mouse orbitofrontal cortex during information seeking
bioRxiv - the preprint server for biology, operated by Cold Spring Harbor Laboratory, a research and educational institution
www.biorxiv.org
October 14, 2023 at 3:58 PM
Absolutely thrilled to share my postdoc work in the Axel lab. We found odor-evoked representations of the intrinsic value of information in mouse orbitofrontal cortex and showed that mice desire knowledge as its own reward. Now on bioRxiv! www.biorxiv.org/content/10.1...