



Ryota Takatsuki
@rtakatsky.bsky.social
PhD student at Sussex Centre for Consciousness Science. Research fellow at AI Alignment Network. Dreaming of reverse-engineering consciousness someday.
We also validated DSL’s reliability through two interventional studies (head importance correlation & overlay removal). Check out our paper for details!
(6/7)
(6/7)


April 25, 2025 at 9:37 AM
We also validated DSL’s reliability through two interventional studies (head importance correlation & overlay removal). Check out our paper for details!
(6/7)
(6/7)
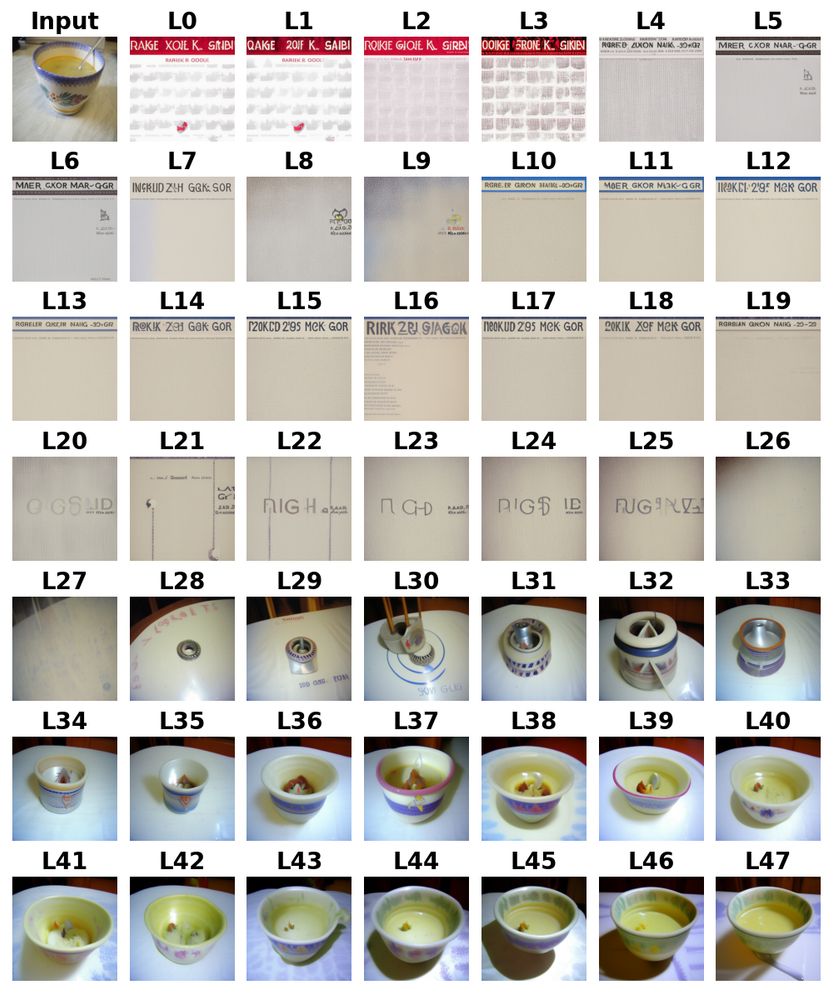
Below are the top-10 head DSL visualizations by similarity to the input, consistent with residual-stream visualizations from Diffusion Lens.
(5/7)
(5/7)

April 25, 2025 at 9:37 AM
Below are the top-10 head DSL visualizations by similarity to the input, consistent with residual-stream visualizations from Diffusion Lens.
(5/7)
(5/7)
To fix this, we propose Diffusion Steering Lens (DSL), a training-free method that steers a specific submodule’s output, patches its subsequent indirect contributions, and then decodes it with the diffusion model.
(4/7)
(4/7)

April 25, 2025 at 9:37 AM
To fix this, we propose Diffusion Steering Lens (DSL), a training-free method that steers a specific submodule’s output, patches its subsequent indirect contributions, and then decodes it with the diffusion model.
(4/7)
(4/7)
We first adapted Diffusion Lens (Toker et al., 2024) to decode residual streams in the Kandinsky 2.2 image encoder (CLIP ViT-bigG/14) via the diffusion model.
We can visualize how the predictions evolve through layers, but individual head contributions stay largely hidden.
(3/7)
We can visualize how the predictions evolve through layers, but individual head contributions stay largely hidden.
(3/7)

April 25, 2025 at 9:37 AM
We first adapted Diffusion Lens (Toker et al., 2024) to decode residual streams in the Kandinsky 2.2 image encoder (CLIP ViT-bigG/14) via the diffusion model.
We can visualize how the predictions evolve through layers, but individual head contributions stay largely hidden.
(3/7)
We can visualize how the predictions evolve through layers, but individual head contributions stay largely hidden.
(3/7)