




Polars
@pola.rs
Dataframes powered by a multithreaded, vectorized query engine, written in Rust.
Are you looking to get started with Polars over the summer?
We've partnered with @datacamp.bsky.social to create an interactive course that covers the fundamentals so you can write your next query with Polars.
The course is free till the end of August: www.datacamp.com/courses/intr...
We've partnered with @datacamp.bsky.social to create an interactive course that covers the fundamentals so you can write your next query with Polars.
The course is free till the end of August: www.datacamp.com/courses/intr...

August 13, 2025 at 3:11 PM
Are you looking to get started with Polars over the summer?
We've partnered with @datacamp.bsky.social to create an interactive course that covers the fundamentals so you can write your next query with Polars.
The course is free till the end of August: www.datacamp.com/courses/intr...
We've partnered with @datacamp.bsky.social to create an interactive course that covers the fundamentals so you can write your next query with Polars.
The course is free till the end of August: www.datacamp.com/courses/intr...
We've partnered with @datacamp.bsky.social to create an interactive Polars course.
Learn the fundamentals and get familiar with our API through hands-on exercises. The course is available for everyone and free until the end of August.
Start the free course here: www.datacamp.com/courses/intr...
Learn the fundamentals and get familiar with our API through hands-on exercises. The course is available for everyone and free until the end of August.
Start the free course here: www.datacamp.com/courses/intr...

May 28, 2025 at 1:24 PM
We've partnered with @datacamp.bsky.social to create an interactive Polars course.
Learn the fundamentals and get familiar with our API through hands-on exercises. The course is available for everyone and free until the end of August.
Start the free course here: www.datacamp.com/courses/intr...
Learn the fundamentals and get familiar with our API through hands-on exercises. The course is available for everyone and free until the end of August.
Start the free course here: www.datacamp.com/courses/intr...
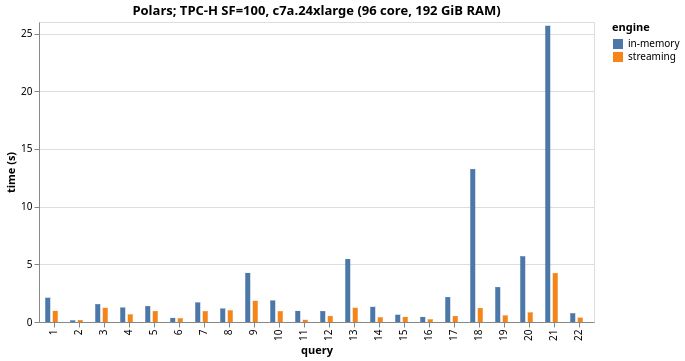
Polars has gotten 4x faster than Polars! 🚀
In the last months, the team has worked incredibly hard on the new-streaming engine and the results pay off. It is incredibly fast, and beats the Polars in-memory engine by a factor of 4 on a 96vCPU machine.
In the last months, the team has worked incredibly hard on the new-streaming engine and the results pay off. It is incredibly fast, and beats the Polars in-memory engine by a factor of 4 on a 96vCPU machine.
May 1, 2025 at 2:05 PM
Polars has gotten 4x faster than Polars! 🚀
In the last months, the team has worked incredibly hard on the new-streaming engine and the results pay off. It is incredibly fast, and beats the Polars in-memory engine by a factor of 4 on a 96vCPU machine.
In the last months, the team has worked incredibly hard on the new-streaming engine and the results pay off. It is incredibly fast, and beats the Polars in-memory engine by a factor of 4 on a 96vCPU machine.
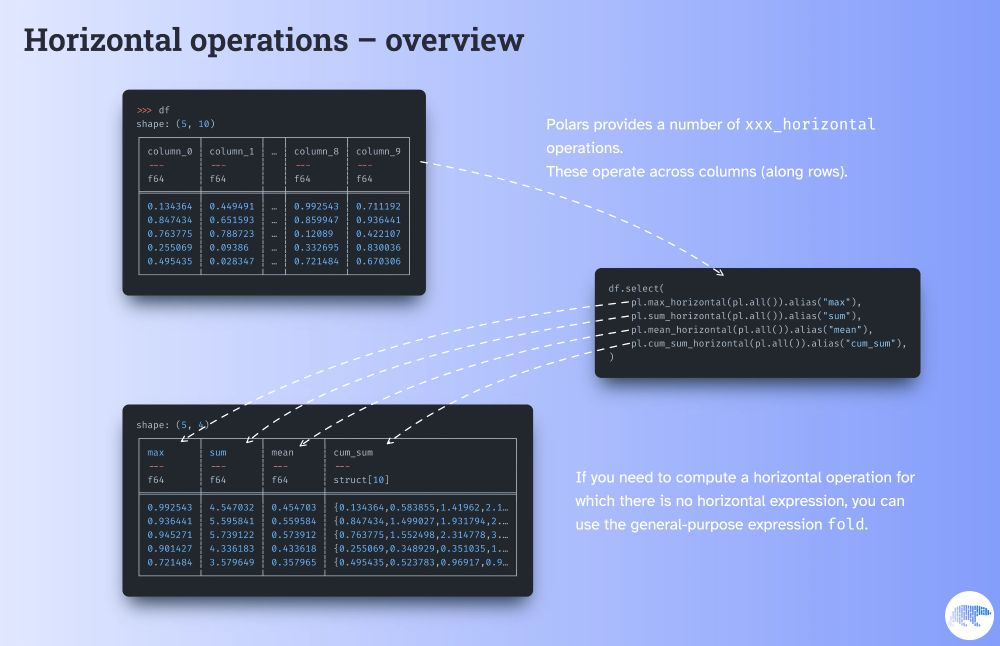
Polars provides a number of xxx_horizontal operations.
These expressions perform computations across columns. (Or along rows, depending on how you look at it.)
If your horizontal operation isn’t implemented, you can use the general-purpose fold.
These expressions perform computations across columns. (Or along rows, depending on how you look at it.)
If your horizontal operation isn’t implemented, you can use the general-purpose fold.
April 30, 2025 at 2:43 PM
Polars provides a number of xxx_horizontal operations.
These expressions perform computations across columns. (Or along rows, depending on how you look at it.)
If your horizontal operation isn’t implemented, you can use the general-purpose fold.
These expressions perform computations across columns. (Or along rows, depending on how you look at it.)
If your horizontal operation isn’t implemented, you can use the general-purpose fold.
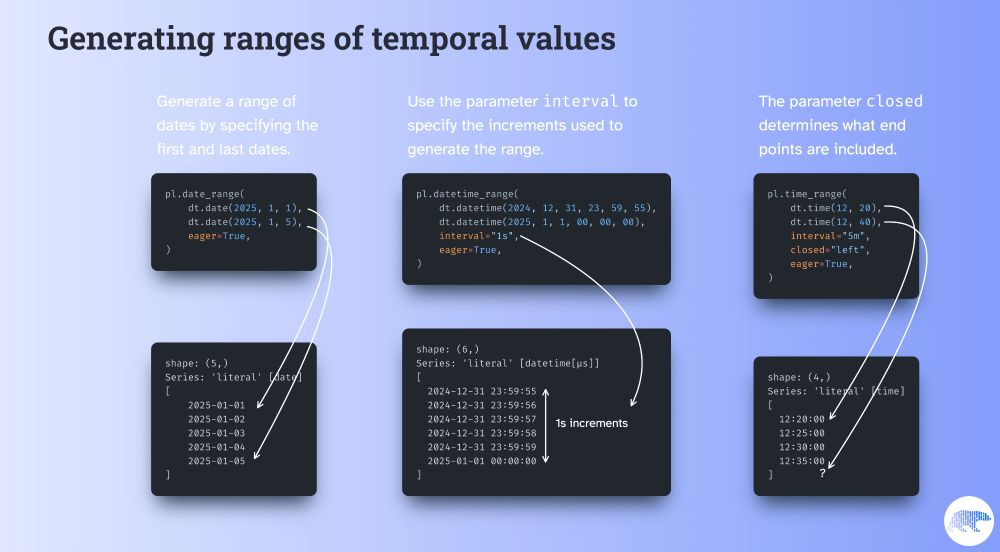
Polars provides 3 functions you can use to generate temporal ranges:
date_range, datetime_range, and time_range.
These can be executed eagerly or lazily.
You can also customize the interval between consecutive values and whether the start/end points are included.
date_range, datetime_range, and time_range.
These can be executed eagerly or lazily.
You can also customize the interval between consecutive values and whether the start/end points are included.
March 19, 2025 at 12:52 PM
Polars provides 3 functions you can use to generate temporal ranges:
date_range, datetime_range, and time_range.
These can be executed eagerly or lazily.
You can also customize the interval between consecutive values and whether the start/end points are included.
date_range, datetime_range, and time_range.
These can be executed eagerly or lazily.
You can also customize the interval between consecutive values and whether the start/end points are included.

The expression over can be used to compute expressions within isolated groups.
This means you can do computations per group without having to group first and then explode after.
In this example, we rank swimmers based on their time, but within their race type.
This means you can do computations per group without having to group first and then explode after.
In this example, we rank swimmers based on their time, but within their race type.

February 27, 2025 at 3:11 PM
The expression over can be used to compute expressions within isolated groups.
This means you can do computations per group without having to group first and then explode after.
In this example, we rank swimmers based on their time, but within their race type.
This means you can do computations per group without having to group first and then explode after.
In this example, we rank swimmers based on their time, but within their race type.
The context filter lets you filter out rows from a dataframe based on some conditions.
Within an aggregation, you can also use filter to filter values from aggregated groups.
In this example we ignore unverified times when computing the current record.
Within an aggregation, you can also use filter to filter values from aggregated groups.
In this example we ignore unverified times when computing the current record.

February 20, 2025 at 5:22 PM
The context filter lets you filter out rows from a dataframe based on some conditions.
Within an aggregation, you can also use filter to filter values from aggregated groups.
In this example we ignore unverified times when computing the current record.
Within an aggregation, you can also use filter to filter values from aggregated groups.
In this example we ignore unverified times when computing the current record.
The expression `clip` is pretty straightforward:
You provide a lower and an upper bound, and Polars makes sure all values fall within those bounds.
If a value is too small/too large, it's replaced by the bound.
Bounds can be literals, other columns, or arbitrary expressions.
You provide a lower and an upper bound, and Polars makes sure all values fall within those bounds.
If a value is too small/too large, it's replaced by the bound.
Bounds can be literals, other columns, or arbitrary expressions.

February 3, 2025 at 3:46 PM
The expression `clip` is pretty straightforward:
You provide a lower and an upper bound, and Polars makes sure all values fall within those bounds.
If a value is too small/too large, it's replaced by the bound.
Bounds can be literals, other columns, or arbitrary expressions.
You provide a lower and an upper bound, and Polars makes sure all values fall within those bounds.
If a value is too small/too large, it's replaced by the bound.
Bounds can be literals, other columns, or arbitrary expressions.
Join our webinar with NVIDIA on January 28 for an in-depth session on how the GPU engine works, from collecting your query to parallel execution on the GPU.
Sign up at info.nvidia.com/nvidia-polar...
See you there?
Sign up at info.nvidia.com/nvidia-polar...
See you there?

January 7, 2025 at 3:18 PM
Join our webinar with NVIDIA on January 28 for an in-depth session on how the GPU engine works, from collecting your query to parallel execution on the GPU.
Sign up at info.nvidia.com/nvidia-polar...
See you there?
Sign up at info.nvidia.com/nvidia-polar...
See you there?
Polars 1.19 comes with support for arbitrary predicates in join_where.
This means that inequality joins are now more flexible than ever!
Here is a small example of something you couldn't do before:
This means that inequality joins are now more flexible than ever!
Here is a small example of something you couldn't do before:

January 6, 2025 at 11:58 AM
Polars 1.19 comes with support for arbitrary predicates in join_where.
This means that inequality joins are now more flexible than ever!
Here is a small example of something you couldn't do before:
This means that inequality joins are now more flexible than ever!
Here is a small example of something you couldn't do before:
Polars supports dynamic aggregations based on time windows via the function `group_by_dynamic`.
To use it, you specify a date(time) column to group by, and then determine the windows over which values are aggregated.
Note how data points can fall within multiple windows 👇
To use it, you specify a date(time) column to group by, and then determine the windows over which values are aggregated.
Note how data points can fall within multiple windows 👇

December 12, 2024 at 7:36 PM
Polars supports dynamic aggregations based on time windows via the function `group_by_dynamic`.
To use it, you specify a date(time) column to group by, and then determine the windows over which values are aggregated.
Note how data points can fall within multiple windows 👇
To use it, you specify a date(time) column to group by, and then determine the windows over which values are aggregated.
Note how data points can fall within multiple windows 👇
Can't remember how many days each month has?
(Me neither!)
Memorise this Polars snippet instead.
Using some calendar-aware functions, we can get the answer in a tidy dataframe, as the diagram below shows.
(Me neither!)
Memorise this Polars snippet instead.
Using some calendar-aware functions, we can get the answer in a tidy dataframe, as the diagram below shows.

December 10, 2024 at 3:32 PM
Can't remember how many days each month has?
(Me neither!)
Memorise this Polars snippet instead.
Using some calendar-aware functions, we can get the answer in a tidy dataframe, as the diagram below shows.
(Me neither!)
Memorise this Polars snippet instead.
Using some calendar-aware functions, we can get the answer in a tidy dataframe, as the diagram below shows.
You want to join two tables on their ID column, but only when the dates in one table fall within the range of the other table.
Polars lets you do that with `join_where`, which supports inequality joins through the use of inequality predicates.
Here's an example 👇
Polars lets you do that with `join_where`, which supports inequality joins through the use of inequality predicates.
Here's an example 👇

November 28, 2024 at 10:52 AM
You want to join two tables on their ID column, but only when the dates in one table fall within the range of the other table.
Polars lets you do that with `join_where`, which supports inequality joins through the use of inequality predicates.
Here's an example 👇
Polars lets you do that with `join_where`, which supports inequality joins through the use of inequality predicates.
Here's an example 👇
Polars has essentially 18 different data types.
If you are unsure what each type is, the conversion table below might help you.
Each Polars data type is presented next to the **most similar** Python type.
If you are unsure what each type is, the conversion table below might help you.
Each Polars data type is presented next to the **most similar** Python type.

November 22, 2024 at 10:47 AM
Polars has essentially 18 different data types.
If you are unsure what each type is, the conversion table below might help you.
Each Polars data type is presented next to the **most similar** Python type.
If you are unsure what each type is, the conversion table below might help you.
Each Polars data type is presented next to the **most similar** Python type.
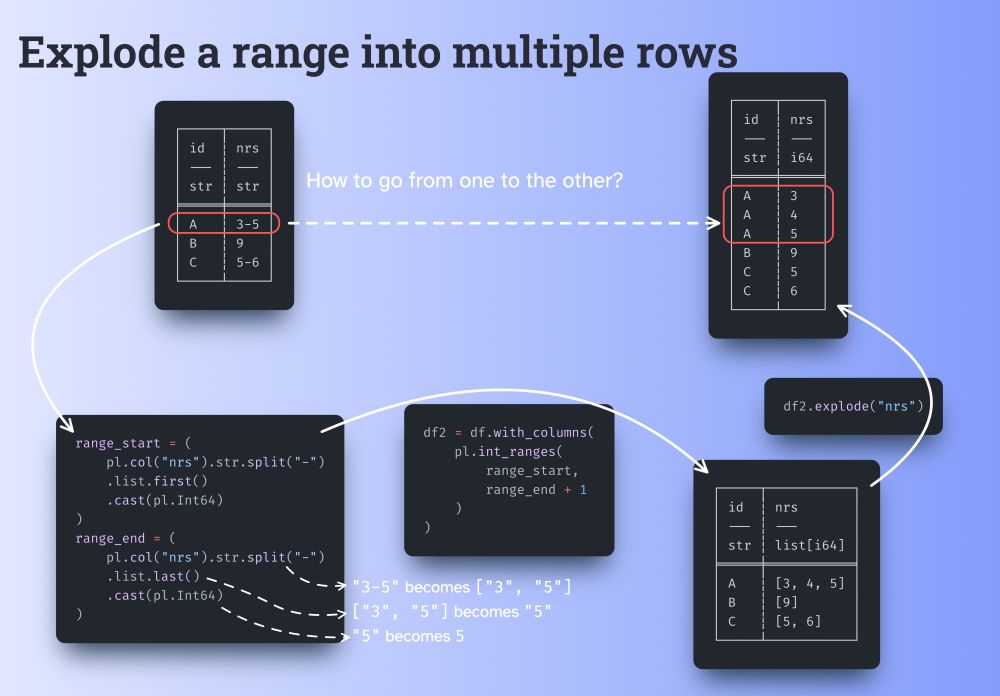
How to “expand” ranges like "3-5" across new rows with the values 3, 4, 5?
This comes straight from our Discord server (discord.com/invite/4UfP5...)
This comes straight from our Discord server (discord.com/invite/4UfP5...)
November 21, 2024 at 2:36 PM
How to “expand” ranges like "3-5" across new rows with the values 3, 4, 5?
This comes straight from our Discord server (discord.com/invite/4UfP5...)
This comes straight from our Discord server (discord.com/invite/4UfP5...)
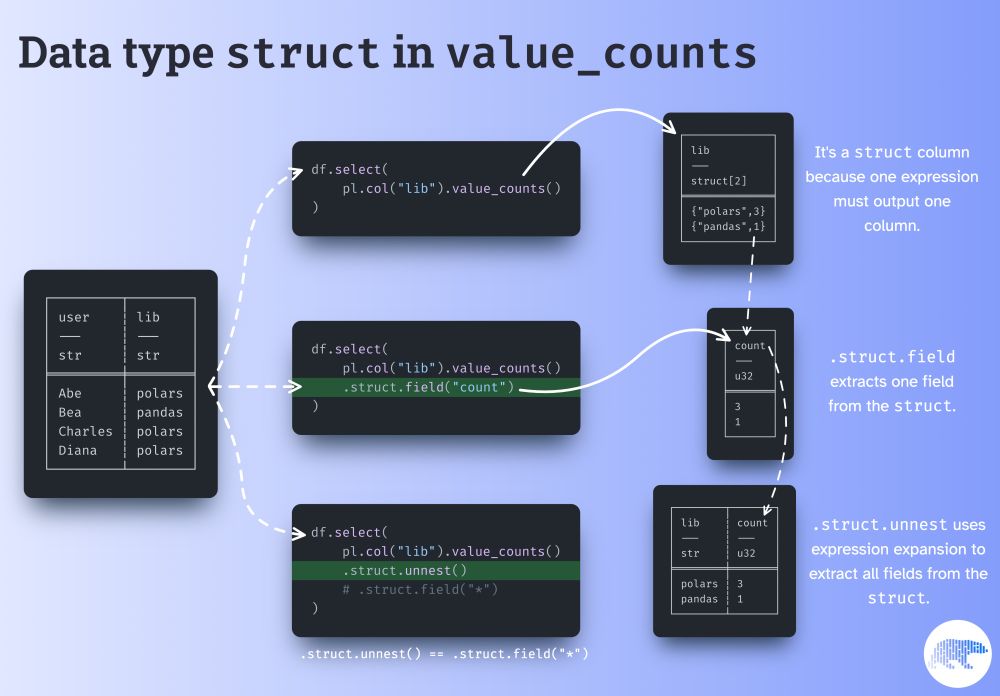
Why is there a `struct` data type?
A single expression produces a single column, so expressions like `value_counts` need to output structs to map the values to their counts.
With that said, do you understand why `.struct.unnest` doesn't break the 1 expr = 1 column principle?
A single expression produces a single column, so expressions like `value_counts` need to output structs to map the values to their counts.
With that said, do you understand why `.struct.unnest` doesn't break the 1 expr = 1 column principle?
November 20, 2024 at 11:14 AM
Why is there a `struct` data type?
A single expression produces a single column, so expressions like `value_counts` need to output structs to map the values to their counts.
With that said, do you understand why `.struct.unnest` doesn't break the 1 expr = 1 column principle?
A single expression produces a single column, so expressions like `value_counts` need to output structs to map the values to their counts.
With that said, do you understand why `.struct.unnest` doesn't break the 1 expr = 1 column principle?