



Nicolas Espinosa Dice
@nico-espinosa-dice.bsky.social
cs phd student @cornelluniversity.bsky.social. previously @harveymuddcollege.bsky.social. working on reinforcement learning & generative models. https://nico-espinosadice.github.io/
check out our paper for more details! in summary:
✅ efficient training
✅ expressive modeling
✅ inference-time scaling
paper: arxiv.org/abs/2505.22866
code: github.com/nico-espinosadice/SORL
w/ Yiyi Zhang, Yiding Chen, Bradley Guo, Owen Oertell, @gokul.dev, @xkianteb.bsky.social, Wen Sun
✅ efficient training
✅ expressive modeling
✅ inference-time scaling
paper: arxiv.org/abs/2505.22866
code: github.com/nico-espinosadice/SORL
w/ Yiyi Zhang, Yiding Chen, Bradley Guo, Owen Oertell, @gokul.dev, @xkianteb.bsky.social, Wen Sun

Scaling Offline RL via Efficient and Expressive Shortcut Models
Diffusion and flow models have emerged as powerful generative approaches capable of modeling diverse and multimodal behavior. However, applying these models to offline reinforcement learning (RL) rema...
arxiv.org
June 12, 2025 at 7:39 PM
check out our paper for more details! in summary:
✅ efficient training
✅ expressive modeling
✅ inference-time scaling
paper: arxiv.org/abs/2505.22866
code: github.com/nico-espinosadice/SORL
w/ Yiyi Zhang, Yiding Chen, Bradley Guo, Owen Oertell, @gokul.dev, @xkianteb.bsky.social, Wen Sun
✅ efficient training
✅ expressive modeling
✅ inference-time scaling
paper: arxiv.org/abs/2505.22866
code: github.com/nico-espinosadice/SORL
w/ Yiyi Zhang, Yiding Chen, Bradley Guo, Owen Oertell, @gokul.dev, @xkianteb.bsky.social, Wen Sun
all together, 𝚂𝙾𝚁𝙻 consistently outperforms 10 offline RL baselines on 40 tasks!

June 12, 2025 at 7:39 PM
all together, 𝚂𝙾𝚁𝙻 consistently outperforms 10 offline RL baselines on 40 tasks!
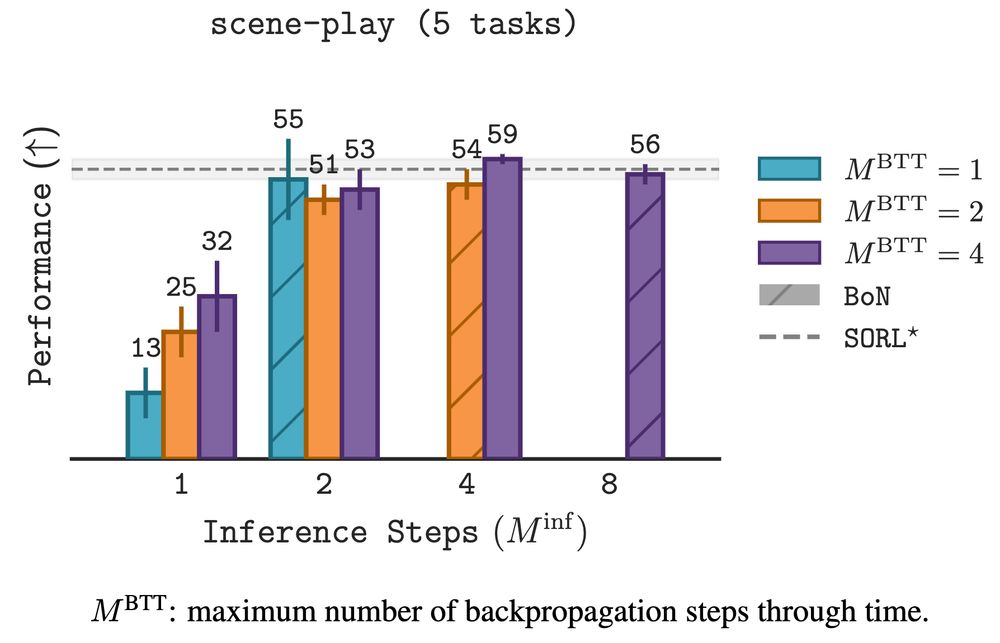
a common issue w/ CoT in LLMs is extrapolating beyond what was optimized during training. 𝚂𝙾𝚁𝙻’s sequential and best-of-N scaling enables *sequential extrapolation*
June 12, 2025 at 7:38 PM
a common issue w/ CoT in LLMs is extrapolating beyond what was optimized during training. 𝚂𝙾𝚁𝙻’s sequential and best-of-N scaling enables *sequential extrapolation*
𝚂𝙾𝚁𝙻 does *parallel scaling* by performing best-of-N with the Q function as a verifier. this is an embarrassingly simple way to help address issues with policy extraction (a major problem in offline RL, see arxiv.org/abs/2406.09329)
Is Value Learning Really the Main Bottleneck in Offline RL?
While imitation learning requires access to high-quality data, offline reinforcement learning (RL) should, in principle, perform similarly or better with substantially lower data quality by using a va...
arxiv.org
June 12, 2025 at 7:38 PM
𝚂𝙾𝚁𝙻 does *parallel scaling* by performing best-of-N with the Q function as a verifier. this is an embarrassingly simple way to help address issues with policy extraction (a major problem in offline RL, see arxiv.org/abs/2406.09329)
motivated by CoT in LLMs, 𝚂𝙾𝚁𝙻 scales inference *sequentially* by increasing the number of inference steps

June 12, 2025 at 7:38 PM
motivated by CoT in LLMs, 𝚂𝙾𝚁𝙻 scales inference *sequentially* by increasing the number of inference steps
with self-consistency, 𝚂𝙾𝚁𝙻 can:
1. *scale expressivity* by fitting complex, multi-modal distributions
2. *scale training* by limiting the amount of backprop through time
3. *scale inference* through sequential and parallel scaling
1. *scale expressivity* by fitting complex, multi-modal distributions
2. *scale training* by limiting the amount of backprop through time
3. *scale inference* through sequential and parallel scaling
June 12, 2025 at 7:37 PM
with self-consistency, 𝚂𝙾𝚁𝙻 can:
1. *scale expressivity* by fitting complex, multi-modal distributions
2. *scale training* by limiting the amount of backprop through time
3. *scale inference* through sequential and parallel scaling
1. *scale expressivity* by fitting complex, multi-modal distributions
2. *scale training* by limiting the amount of backprop through time
3. *scale inference* through sequential and parallel scaling
𝚂𝙾𝚁𝙻 leverages @Kevin Frans's shortcut models to incorporate self-consistency into training, allowing the policy to learn “large jumps” that match more-precise “small jumps”
pc: @Kevin Frans
pc: @Kevin Frans

June 12, 2025 at 7:37 PM
𝚂𝙾𝚁𝙻 leverages @Kevin Frans's shortcut models to incorporate self-consistency into training, allowing the policy to learn “large jumps” that match more-precise “small jumps”
pc: @Kevin Frans
pc: @Kevin Frans
Scalable Offline RL (𝚂𝙾𝚁𝙻): a training procedure for *expressive policies* that can do inference under *any* compute budget
paper: arxiv.org/abs/2505.22866
code: github.com/nico-espinosadice/SORL
w/ Yiyi Zhang, Yiding Chen, Bradley Guo, Owen Oertell, @gokul.dev , @xkianteb.bsky.social, Wen Sun
paper: arxiv.org/abs/2505.22866
code: github.com/nico-espinosadice/SORL
w/ Yiyi Zhang, Yiding Chen, Bradley Guo, Owen Oertell, @gokul.dev , @xkianteb.bsky.social, Wen Sun
Scaling Offline RL via Efficient and Expressive Shortcut Models
Diffusion and flow models have emerged as powerful generative approaches capable of modeling diverse and multimodal behavior. However, applying these models to offline reinforcement learning (RL) rema...
arxiv.org
June 12, 2025 at 7:35 PM
Scalable Offline RL (𝚂𝙾𝚁𝙻): a training procedure for *expressive policies* that can do inference under *any* compute budget
paper: arxiv.org/abs/2505.22866
code: github.com/nico-espinosadice/SORL
w/ Yiyi Zhang, Yiding Chen, Bradley Guo, Owen Oertell, @gokul.dev , @xkianteb.bsky.social, Wen Sun
paper: arxiv.org/abs/2505.22866
code: github.com/nico-espinosadice/SORL
w/ Yiyi Zhang, Yiding Chen, Bradley Guo, Owen Oertell, @gokul.dev , @xkianteb.bsky.social, Wen Sun