



Nic Crane
@niccrane.bsky.social
Independent R consultant. Apache Arrow PMC Member & #rstats 📦 maintainer.
Arrow course launching early 2026: https://big-data-r.thinkific.com/
More of my stuff at https://niccrane.com/
Arrow course launching early 2026: https://big-data-r.thinkific.com/
More of my stuff at https://niccrane.com/
Thanks, I think I'll skip emailing and go for the automated checking 🤣
November 27, 2025 at 5:10 PM
Thanks, I think I'll skip emailing and go for the automated checking 🤣
Making conferences easier for my social anxiety as random people I don't know sometimes come up to me to say hi and I don't have to do as much of the work of starting the conversation 😅
November 24, 2025 at 5:09 PM
Making conferences easier for my social anxiety as random people I don't know sometimes come up to me to say hi and I don't have to do as much of the work of starting the conversation 😅
Ooh, this looks cool AF, I was looking for inspiration for more posting and so buying a copy!
November 24, 2025 at 5:06 PM
Ooh, this looks cool AF, I was looking for inspiration for more posting and so buying a copy!
Episode 1 is like that but you get a lot more info in episode 2, and now we're slowly getting more as it progresses. I didn't love the first episode but glad I stuck with it!
November 23, 2025 at 11:26 AM
Episode 1 is like that but you get a lot more info in episode 2, and now we're slowly getting more as it progresses. I didn't love the first episode but glad I stuck with it!
Oh, I saw, this is very cool!
November 22, 2025 at 12:04 AM
Oh, I saw, this is very cool!
Omg, this, now I'm self employed I weirdly love working Saturday mornings as I'd rather have more time for myself in the week. Also love collaborating with US folks so I can have productive mornings in silence before they wake up!
November 19, 2025 at 8:54 AM
Omg, this, now I'm self employed I weirdly love working Saturday mornings as I'd rather have more time for myself in the week. Also love collaborating with US folks so I can have productive mornings in silence before they wake up!
Key ideas:
- Creating complex R packages from scratch: LLMs most useful when task appropriately scoped
- Learning: LLMs can help independent learning new concepts by scaffolding learning
- Coding tasks - LLMs can help with the basics but don't use them to replace human interaction and collaboration
- Creating complex R packages from scratch: LLMs most useful when task appropriately scoped
- Learning: LLMs can help independent learning new concepts by scaffolding learning
- Coding tasks - LLMs can help with the basics but don't use them to replace human interaction and collaboration
November 19, 2025 at 8:32 AM
Key ideas:
- Creating complex R packages from scratch: LLMs most useful when task appropriately scoped
- Learning: LLMs can help independent learning new concepts by scaffolding learning
- Coding tasks - LLMs can help with the basics but don't use them to replace human interaction and collaboration
- Creating complex R packages from scratch: LLMs most useful when task appropriately scoped
- Learning: LLMs can help independent learning new concepts by scaffolding learning
- Coding tasks - LLMs can help with the basics but don't use them to replace human interaction and collaboration
Thanks for highlighting the error - I wouldn't have noticed it, and I feel like "close enough to accurate but missing the mark subtly" is one of the biggest inaccuracy risks with LLMs.
November 18, 2025 at 1:14 PM
Thanks for highlighting the error - I wouldn't have noticed it, and I feel like "close enough to accurate but missing the mark subtly" is one of the biggest inaccuracy risks with LLMs.
Give the LLM more freedom when using it to explore the data, but much less when using it to extract information.
Code: gist.github.com/thisisnic/22...
(3/3)
Code: gist.github.com/thisisnic/22...
(3/3)

Structured output and enums
Structured output and enums. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
November 18, 2025 at 10:08 AM
Give the LLM more freedom when using it to explore the data, but much less when using it to extract information.
Code: gist.github.com/thisisnic/22...
(3/3)
Code: gist.github.com/thisisnic/22...
(3/3)
This was just a toy example, but in a real data extraction pipeline, I'd be better off using pre-defined categories. Here, if I use `type_enum()` in my structured output, the LLM must choose from a specific list. (2/3)



November 18, 2025 at 10:08 AM
This was just a toy example, but in a real data extraction pipeline, I'd be better off using pre-defined categories. Here, if I use `type_enum()` in my structured output, the LLM must choose from a specific list. (2/3)
I really like the "Silent Misalignment" one - I find huge differences in results when I ask the agent to push back against my suggestions as necessary, and it helps me stay engaged instead of letting it do all the work. Any stand out for anyone else?
November 13, 2025 at 4:42 PM
I really like the "Silent Misalignment" one - I find huge differences in results when I ask the agent to push back against my suggestions as necessary, and it helps me stay engaged instead of letting it do all the work. Any stand out for anyone else?
IMO, the best bit is that they're all interlinked so when you read about an obstacle there's a link to the anti-pattern it contributes to, and when you read about an anti-pattern it there's a link to the pattern you can follow to avoid it!
November 13, 2025 at 4:42 PM
IMO, the best bit is that they're all interlinked so when you read about an obstacle there's a link to the anti-pattern it contributes to, and when you read about an anti-pattern it there's a link to the pattern you can follow to avoid it!
This release saw 39 contributors to the codebase! 31 worked on the C++ library, 4 on the R 📦, & 4 on both. 15 people made their first contribution! 🎉 Thanks to everyone who was involved!
November 6, 2025 at 10:02 AM
This release saw 39 contributors to the codebase! 31 worked on the C++ library, 4 on the R 📦, & 4 on both. 15 people made their first contribution! 🎉 Thanks to everyone who was involved!
Most updates were to docs and internals, but one feature to note is that we’ve added support for stringr::str_replace_na()
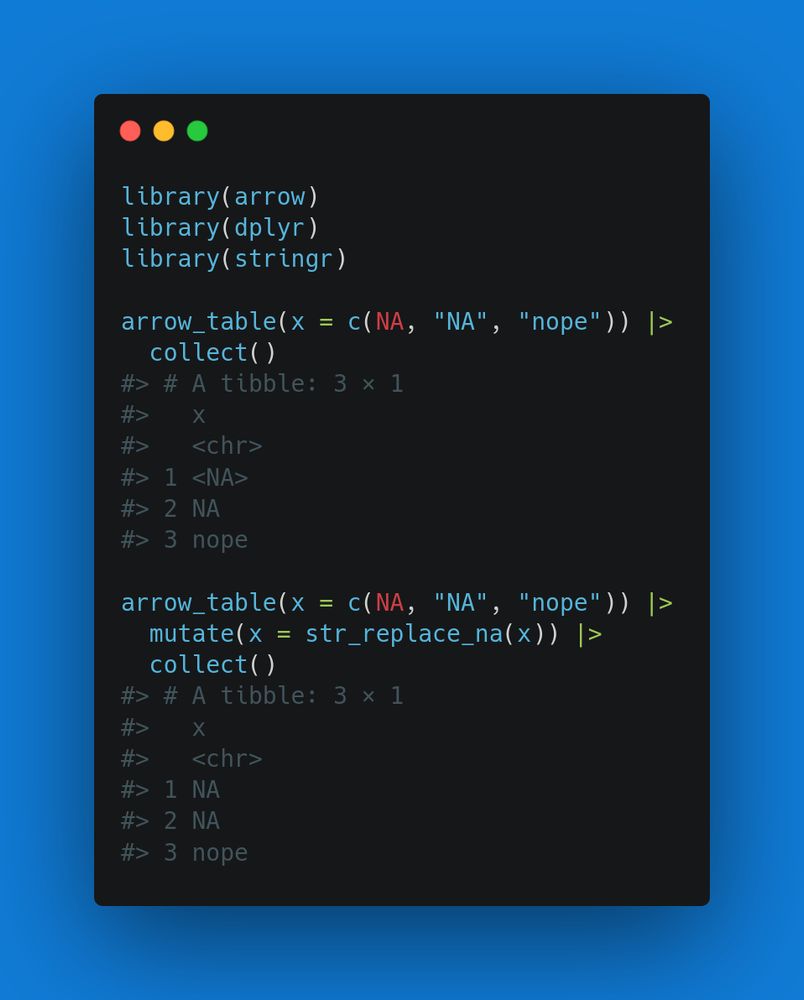
November 6, 2025 at 10:02 AM
Most updates were to docs and internals, but one feature to note is that we’ve added support for stringr::str_replace_na()