




In addition to the 35 new coding ORFs, we also found evidence for 279 alternative isoforms and 99 translated upstream regions. The vast majority of the upstream translations were validated by their peptides. Translation from upstream regions is more common than is currently thought (see paper above)

November 24, 2025 at 4:06 PM
In addition to the 35 new coding ORFs, we also found evidence for 279 alternative isoforms and 99 translated upstream regions. The vast majority of the upstream translations were validated by their peptides. Translation from upstream regions is more common than is currently thought (see paper above)
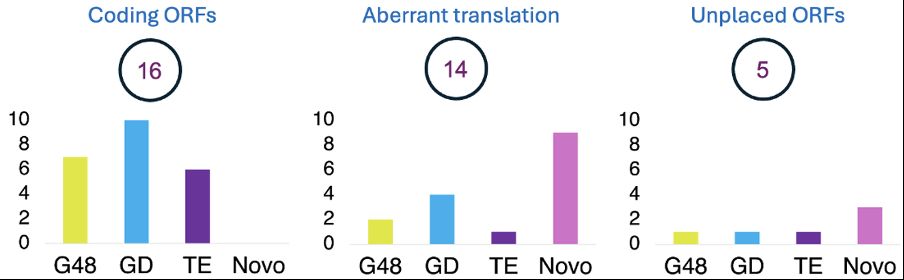
We report our results to GENCODE, so 10 genes were already annotated as coding prior to the paper. However, we believe that only 7 are coding. The annotation of LINC03040 and MYH16 as coding was premature and no POM121L1P repeats should have been annotated because peptides map to at least 8 regions.
November 24, 2025 at 4:03 PM
We report our results to GENCODE, so 10 genes were already annotated as coding prior to the paper. However, we believe that only 7 are coding. The annotation of LINC03040 and MYH16 as coding was premature and no POM121L1P repeats should have been annotated because peptides map to at least 8 regions.
None of these new genes are entirely novel because they all had to have been “discovered” at some point to be included in the PeptideAtlas search database. None of the 16 genes we believe are likely to be coding were annotated in RefSeq either, but 8 were included in the UniProtKB human proteome.

November 24, 2025 at 3:59 PM
None of these new genes are entirely novel because they all had to have been “discovered” at some point to be included in the PeptideAtlas search database. None of the 16 genes we believe are likely to be coding were annotated in RefSeq either, but 8 were included in the UniProtKB human proteome.
Finally peptides for 5 predicted proteins mapped to multiple regions in the genome. We believe that most of these peptides were also produced by aberrant translation. LINE 1 ORF1 would be a good example, present in hundreds of regions and with more than 50 peptides in cancers.

November 24, 2025 at 3:58 PM
Finally peptides for 5 predicted proteins mapped to multiple regions in the genome. We believe that most of these peptides were also produced by aberrant translation. LINE 1 ORF1 would be a good example, present in hundreds of regions and with more than 50 peptides in cancers.
None of the 16 the genes that we found peptide evidence for had evolved ab initio within primates.
November 24, 2025 at 3:53 PM
None of the 16 the genes that we found peptide evidence for had evolved ab initio within primates.
Another 6 coding genes derived from retroviruses, and 3 of these were detected exclusively in placenta. This is remarkable because up to now all well-known co-opted retroviral genes in human placenta were derived from env ORFs. All three PeptideAtlas-supported novel ORFs were ERV gag ORFs.

November 24, 2025 at 3:49 PM
Another 6 coding genes derived from retroviruses, and 3 of these were detected exclusively in placenta. This is remarkable because up to now all well-known co-opted retroviral genes in human placenta were derived from env ORFs. All three PeptideAtlas-supported novel ORFs were ERV gag ORFs.
Like several other gene duplications, Trembl entry Q3ZM62 (now ENSG00000293661) is expressed in testis. It is a eutherian paralogue of ETDA and this pair of genes have three more copies on chromosome X in human. However, there is no evidence to suggest that any of the other six genes are coding.

November 24, 2025 at 3:46 PM
Like several other gene duplications, Trembl entry Q3ZM62 (now ENSG00000293661) is expressed in testis. It is a eutherian paralogue of ETDA and this pair of genes have three more copies on chromosome X in human. However, there is no evidence to suggest that any of the other six genes are coding.
The other 14 genes can be split into two groups. Eight derived from gene duplications. Many of these have undergone considerable changes and may have been pseudogenes prior to gaining novel function. These genes include C5orf60 (now SPATA31J1), CFAP144P1, MSL3P1 (now MSL3B ) and ZNF840P.

November 24, 2025 at 3:43 PM
The other 14 genes can be split into two groups. Eight derived from gene duplications. Many of these have undergone considerable changes and may have been pseudogenes prior to gaining novel function. These genes include C5orf60 (now SPATA31J1), CFAP144P1, MSL3P1 (now MSL3B ) and ZNF840P.
These 35 potential new coding genes were found by examining PeptideAtlas peptides that did not map to GENCODE isoforms. Where those peptides mapped to regions outside of known coding gene loci, we carried out detailed analyses of the PSM, conservation, expression, potential function …
November 24, 2025 at 3:38 PM
These 35 potential new coding genes were found by examining PeptideAtlas peptides that did not map to GENCODE isoforms. Where those peptides mapped to regions outside of known coding gene loci, we carried out detailed analyses of the PSM, conservation, expression, potential function …
I like this one! You are absolutely right that there is more evidence for the 805aa isoform. But there are two NAGNAG splice events in RASAL1 and the extra amino acid exon has way more support in splice events. Which makes the 806aa isoform the principal. APPRIS will change to reflect this.

October 6, 2025 at 11:30 AM
I like this one! You are absolutely right that there is more evidence for the 805aa isoform. But there are two NAGNAG splice events in RASAL1 and the extra amino acid exon has way more support in splice events. Which makes the 806aa isoform the principal. APPRIS will change to reflect this.
Not everyone as it turns out. APPRIS has the 353 aa isoform as principal

October 3, 2025 at 8:29 PM
Not everyone as it turns out. APPRIS has the 353 aa isoform as principal
This one had me stumped for a while. They are both wrong, as is the other 183 aa amino acid isoform annotated by @ensembl - none of the upstream exons or ATGs are conserved across primates.
APPRIS does get it right, but only in RefSeq because RefSeq annotates the downstream ATG (169 aa isoform):
APPRIS does get it right, but only in RefSeq because RefSeq annotates the downstream ATG (169 aa isoform):

October 3, 2025 at 7:54 PM
This one had me stumped for a while. They are both wrong, as is the other 183 aa amino acid isoform annotated by @ensembl - none of the upstream exons or ATGs are conserved across primates.
APPRIS does get it right, but only in RefSeq because RefSeq annotates the downstream ATG (169 aa isoform):
APPRIS does get it right, but only in RefSeq because RefSeq annotates the downstream ATG (169 aa isoform):
Not seeing this case. There are peptides for the extra mini-exon in the APPRIS principal isoform. Besides this last exon codes for a crucial internal strand, which if missing would probably make ADH6 a pseudogene.
ADH6 seems to be an old world monkey duplication of ADH7, which has mutated a LOT.
ADH6 seems to be an old world monkey duplication of ADH7, which has mutated a LOT.

October 3, 2025 at 5:59 PM
Not seeing this case. There are peptides for the extra mini-exon in the APPRIS principal isoform. Besides this last exon codes for a crucial internal strand, which if missing would probably make ADH6 a pseudogene.
ADH6 seems to be an old world monkey duplication of ADH7, which has mutated a LOT.
ADH6 seems to be an old world monkey duplication of ADH7, which has mutated a LOT.
So, still a lot of work to be done to get down a final agreed set of coding genes. One big step would be to eliminate all readthrough genes. Let's see ...
And that winds up our work in @gencodegenes.bsky.social
It has been fun.
Work carried out by Miguel Maquedano and @danielcerdan.bsky.social
And that winds up our work in @gencodegenes.bsky.social
It has been fun.
Work carried out by Miguel Maquedano and @danielcerdan.bsky.social

September 30, 2025 at 3:39 PM
So, still a lot of work to be done to get down a final agreed set of coding genes. One big step would be to eliminate all readthrough genes. Let's see ...
And that winds up our work in @gencodegenes.bsky.social
It has been fun.
Work carried out by Miguel Maquedano and @danielcerdan.bsky.social
And that winds up our work in @gencodegenes.bsky.social
It has been fun.
Work carried out by Miguel Maquedano and @danielcerdan.bsky.social
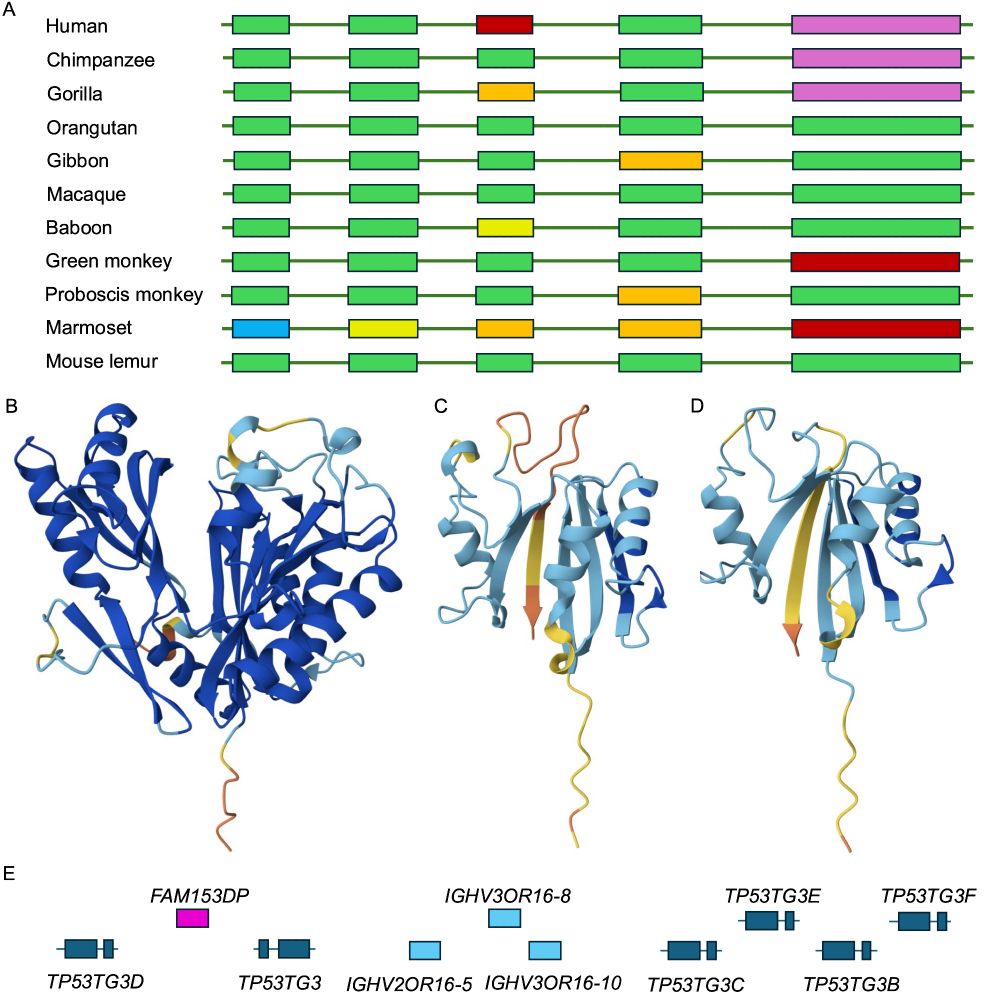
... and there are also many genes in the intersection between the three sets that are "legacy" coding genes and should be scrubbed from all three reference sets, these include HEPN1, BLID, PBOV1, GNG14, GJE1, HIGD2B, FTCDNL1 and the TP53TG3 family as we show in detail in the paper.
September 30, 2025 at 3:26 PM
... and there are also many genes in the intersection between the three sets that are "legacy" coding genes and should be scrubbed from all three reference sets, these include HEPN1, BLID, PBOV1, GNG14, GJE1, HIGD2B, FTCDNL1 and the TP53TG3 family as we show in detail in the paper.
We also generated a set of 9 potential non-coding features for this paper.
With the exception of the agreements between UniProtKB and Ensembl/GENCODE (mostly Ig/TcR fragments), most genes outside of the 3-way intersection were tagged as potential non-coding.
These are probably not coding genes.
With the exception of the agreements between UniProtKB and Ensembl/GENCODE (mostly Ig/TcR fragments), most genes outside of the 3-way intersection were tagged as potential non-coding.
These are probably not coding genes.

September 30, 2025 at 3:12 PM
We also generated a set of 9 potential non-coding features for this paper.
With the exception of the agreements between UniProtKB and Ensembl/GENCODE (mostly Ig/TcR fragments), most genes outside of the 3-way intersection were tagged as potential non-coding.
These are probably not coding genes.
With the exception of the agreements between UniProtKB and Ensembl/GENCODE (mostly Ig/TcR fragments), most genes outside of the 3-way intersection were tagged as potential non-coding.
These are probably not coding genes.
Ensembl/GENCODE is the biggest beneficiary of the changes - 99.5% of all the annotated coding genes in GENCODE v45 were in agreement with both RefSeq and UniProtKB.
With the caveat that the Ensembl/GENCODE set is also the worst reference set for readthrough "coding" genes (see start of thread).
With the caveat that the Ensembl/GENCODE set is also the worst reference set for readthrough "coding" genes (see start of thread).

September 30, 2025 at 2:57 PM
Ensembl/GENCODE is the biggest beneficiary of the changes - 99.5% of all the annotated coding genes in GENCODE v45 were in agreement with both RefSeq and UniProtKB.
With the caveat that the Ensembl/GENCODE set is also the worst reference set for readthrough "coding" genes (see start of thread).
With the caveat that the Ensembl/GENCODE set is also the worst reference set for readthrough "coding" genes (see start of thread).
Without these genes, it is clear that all three reference sets annotate fewer coding genes, yet agree on almost 250 more coding genes than in 2018.

September 30, 2025 at 2:51 PM
Without these genes, it is clear that all three reference sets annotate fewer coding genes, yet agree on almost 250 more coding genes than in 2018.
So, our definitive paper on the human reference gene set is out this week in Database (Oxford).
We merged and compared @ensembl.org / @gencodegenes.bsky.social , RefSeq and UniProtKB coding genes and investigated the agreements and discrepancies.
Details of what we found in the thread ...
We merged and compared @ensembl.org / @gencodegenes.bsky.social , RefSeq and UniProtKB coding genes and investigated the agreements and discrepancies.
Details of what we found in the thread ...

September 30, 2025 at 2:25 PM
So, our definitive paper on the human reference gene set is out this week in Database (Oxford).
We merged and compared @ensembl.org / @gencodegenes.bsky.social , RefSeq and UniProtKB coding genes and investigated the agreements and discrepancies.
Details of what we found in the thread ...
We merged and compared @ensembl.org / @gencodegenes.bsky.social , RefSeq and UniProtKB coding genes and investigated the agreements and discrepancies.
Details of what we found in the thread ...
Hi, if you find any more of these genes, can you tag @appris.bsky.social so that we can look at them? We have a manually annotated section now and we can make changes almost immediately. We agree with UniProt on this one:

September 29, 2025 at 4:52 PM
Hi, if you find any more of these genes, can you tag @appris.bsky.social so that we can look at them? We have a manually annotated section now and we can make changes almost immediately. We agree with UniProt on this one:
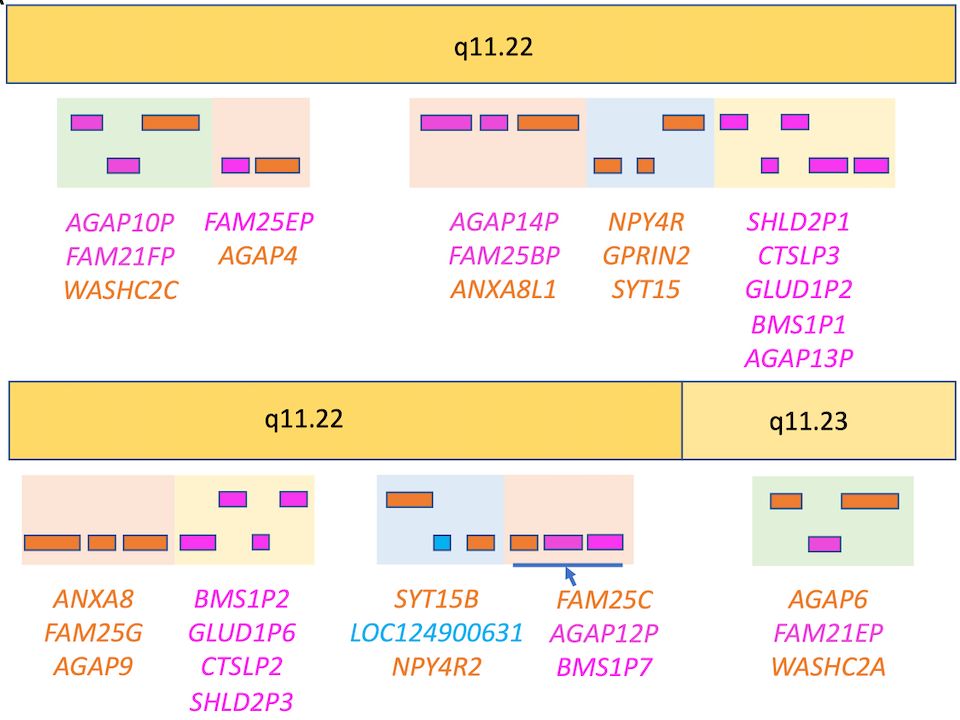
We also find a novel GPRIN2 gene, which has more support than its paralogue. In this case, both genes may be coding.
January 7, 2025 at 11:15 AM
We also find a novel GPRIN2 gene, which has more support than its paralogue. In this case, both genes may be coding.
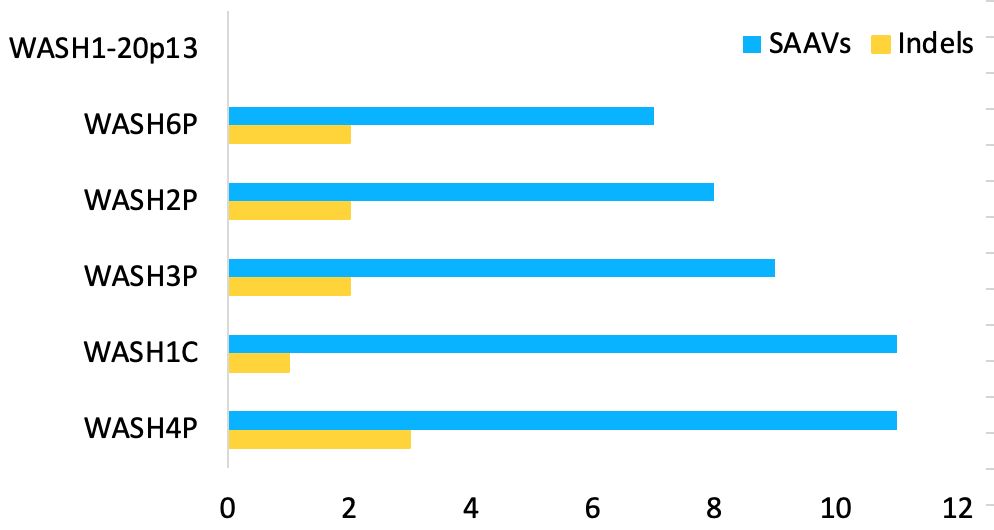
All 12 WASH1C paralogues, the 5 annotated by UniprotKB as coding and 7 more in the T2T regions of distinct chromosomes, were shown to have duplicated in the human lineage and all could be traced back to chr. 8 WASH1C (a pseudogene) and not to WASH1-20p13.
All 12 WASH12C paralogues are pseudogenes.
All 12 WASH12C paralogues are pseudogenes.

January 7, 2025 at 11:09 AM
All 12 WASH1C paralogues, the 5 annotated by UniprotKB as coding and 7 more in the T2T regions of distinct chromosomes, were shown to have duplicated in the human lineage and all could be traced back to chr. 8 WASH1C (a pseudogene) and not to WASH1-20p13.
All 12 WASH12C paralogues are pseudogenes.
All 12 WASH12C paralogues are pseudogenes.
On top of that, we show that all 12 WASH1C paralogues of the chromosome 20 p arm gene (WASH1-20p13) have multiple mutations in conserved regions of WASH1C suggesting that only WASH1-20p13 conserves WASHC1's role in the WASH complex.
January 7, 2025 at 11:01 AM
On top of that, we show that all 12 WASH1C paralogues of the chromosome 20 p arm gene (WASH1-20p13) have multiple mutations in conserved regions of WASH1C suggesting that only WASH1-20p13 conserves WASHC1's role in the WASH complex.
Peptide evidence supports the WASHC1 isoform found in the subtelomeric region of the p arm of chromosome 20, and does not support the translation any of the other 12 WASHC1 paralogues, including the WASHC1 gene on chromosome 9, which was thought to be coding.
@bioinfoadv.bsky.social
@bioinfoadv.bsky.social

January 7, 2025 at 10:52 AM
Peptide evidence supports the WASHC1 isoform found in the subtelomeric region of the p arm of chromosome 20, and does not support the translation any of the other 12 WASHC1 paralogues, including the WASHC1 gene on chromosome 9, which was thought to be coding.
@bioinfoadv.bsky.social
@bioinfoadv.bsky.social
This time we also tagged the RefSeq and UniProtKB singleton coding genes with PNC features. Even though these features were designed to label GENCODE coding genes, we still tagged 63.1% of RefSeq genes not in the intersection and 54.7% of UniProtKB genes as potential non-coding.
![The percentage of the genes in different gene sets that are tagged as potential non-coding genes. The genes in each set are those shown in figure 1B, “GENCODE [G]” are all Ensembl/GENCODE genes, “RefSeq [R]” are all RefSeq genes, and “UniProtKB [U]” are all UniProtKB genes. “G. not intersect” are all Ensembl/GENCODE genes that are not in the intersection between the three sets. “R. not intersect” are all RefSeq genes that are not in the intersection between the three sets. “U. not intersect” are all UniProtKB genes that are not in the intersection between the three sets.](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:ea24pi345ceviookqvbeicoc/bafkreifxbp4dxujsvaanepm3rue4uf7fxjnkb4dbgchc654rplqoiphgyy@jpeg)

December 10, 2024 at 12:58 PM
This time we also tagged the RefSeq and UniProtKB singleton coding genes with PNC features. Even though these features were designed to label GENCODE coding genes, we still tagged 63.1% of RefSeq genes not in the intersection and 54.7% of UniProtKB genes as potential non-coding.