



Mourad Heddaya
@mheddaya.bsky.social
nlp phd student at uchicago cs
Reposted by Mourad Heddaya

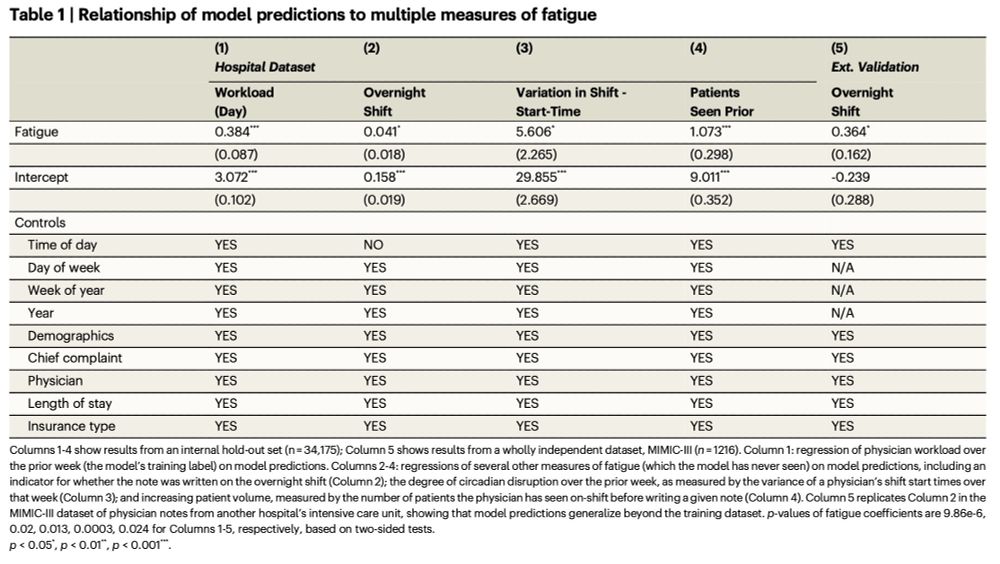
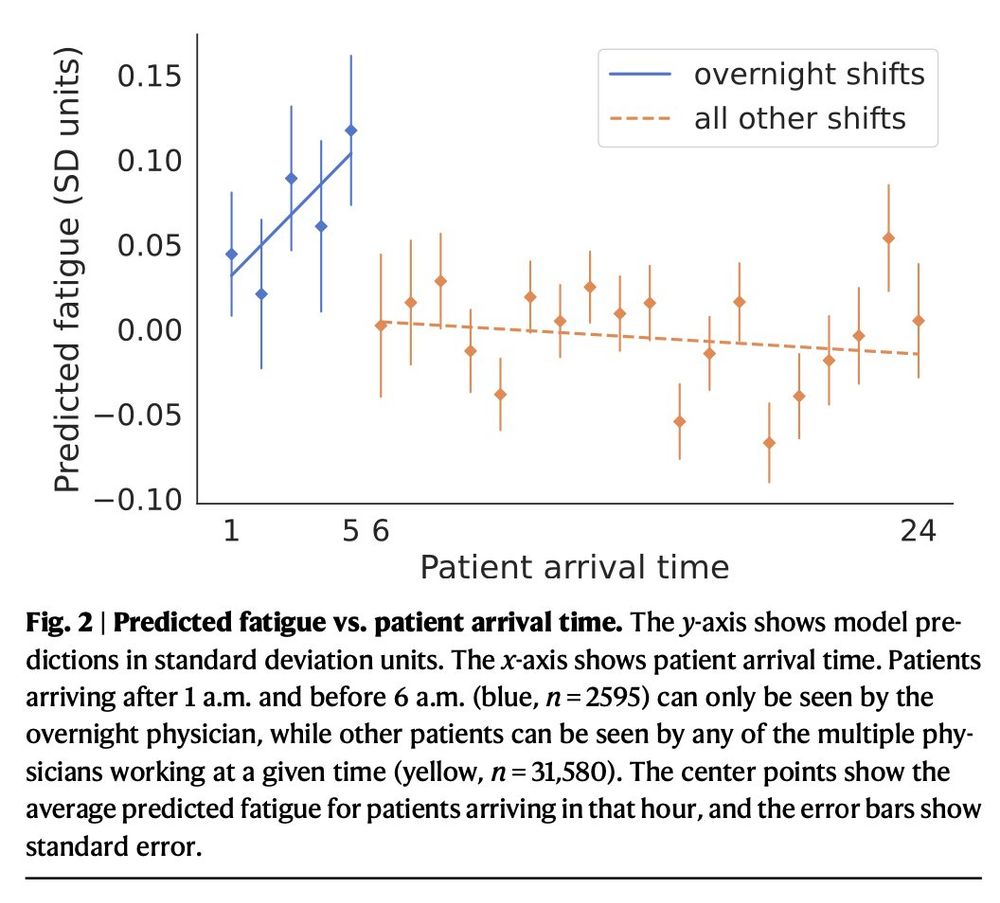
It predicts pretty well—not just shifts in the last week, but also:
1. Who’s working an overnight shift (in our data + external validation in MIMIC)
2. Who’s working on a disruptive circadian schedule
3. How many patients has the doc seen *on the current shift*
1. Who’s working an overnight shift (in our data + external validation in MIMIC)
2. Who’s working on a disruptive circadian schedule
3. How many patients has the doc seen *on the current shift*
July 2, 2025 at 7:24 PM
It predicts pretty well—not just shifts in the last week, but also:
1. Who’s working an overnight shift (in our data + external validation in MIMIC)
2. Who’s working on a disruptive circadian schedule
3. How many patients has the doc seen *on the current shift*
1. Who’s working an overnight shift (in our data + external validation in MIMIC)
2. Who’s working on a disruptive circadian schedule
3. How many patients has the doc seen *on the current shift*
I'll be presenting this work at 2pm and will be around until Sunday. Please reach out if you're interested in this line of work - would love to connect in person or virtually!
Thank you to my great collaborators @kyle-macmillan.bsky.social , Anup Malani, Hongyuan Mei, and @chenhaotan.bsky.social
Thank you to my great collaborators @kyle-macmillan.bsky.social , Anup Malani, Hongyuan Mei, and @chenhaotan.bsky.social
May 1, 2025 at 7:25 PM
I'll be presenting this work at 2pm and will be around until Sunday. Please reach out if you're interested in this line of work - would love to connect in person or virtually!
Thank you to my great collaborators @kyle-macmillan.bsky.social , Anup Malani, Hongyuan Mei, and @chenhaotan.bsky.social
Thank you to my great collaborators @kyle-macmillan.bsky.social , Anup Malani, Hongyuan Mei, and @chenhaotan.bsky.social
CaseSumm is publicly available on HuggingFace! We hope this dataset enables:
- Better evaluation of long-context summarization
- Research on legal language understanding
- Development of more accurate & reliable legal AI tools
Dataset: huggingface.co/datasets/Chi...
- Better evaluation of long-context summarization
- Research on legal language understanding
- Development of more accurate & reliable legal AI tools
Dataset: huggingface.co/datasets/Chi...

ChicagoHAI/CaseSumm · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
May 1, 2025 at 7:25 PM
CaseSumm is publicly available on HuggingFace! We hope this dataset enables:
- Better evaluation of long-context summarization
- Research on legal language understanding
- Development of more accurate & reliable legal AI tools
Dataset: huggingface.co/datasets/Chi...
- Better evaluation of long-context summarization
- Research on legal language understanding
- Development of more accurate & reliable legal AI tools
Dataset: huggingface.co/datasets/Chi...
Analysis reveals different types of hallucinations:
- Simple factual errors
- Incorrect legal citations
- Misrepresentation of procedural history
- Mischaracterization of Court's reasoning
Fine-tuned smaller models tend to make more egregious errors than GPT-4.
- Simple factual errors
- Incorrect legal citations
- Misrepresentation of procedural history
- Mischaracterization of Court's reasoning
Fine-tuned smaller models tend to make more egregious errors than GPT-4.

May 1, 2025 at 7:25 PM
Analysis reveals different types of hallucinations:
- Simple factual errors
- Incorrect legal citations
- Misrepresentation of procedural history
- Mischaracterization of Court's reasoning
Fine-tuned smaller models tend to make more egregious errors than GPT-4.
- Simple factual errors
- Incorrect legal citations
- Misrepresentation of procedural history
- Mischaracterization of Court's reasoning
Fine-tuned smaller models tend to make more egregious errors than GPT-4.
CaseSumm is a useful resource for long-context reasoning and legal research:
- Largest legal case summarization dataset
- 200+ years of Supreme Court cases
- "Ground truth" summaries written by Court attorneys and approved by Justices
- Variation in summary styles and compression rates over time
- Largest legal case summarization dataset
- 200+ years of Supreme Court cases
- "Ground truth" summaries written by Court attorneys and approved by Justices
- Variation in summary styles and compression rates over time

May 1, 2025 at 7:25 PM
CaseSumm is a useful resource for long-context reasoning and legal research:
- Largest legal case summarization dataset
- 200+ years of Supreme Court cases
- "Ground truth" summaries written by Court attorneys and approved by Justices
- Variation in summary styles and compression rates over time
- Largest legal case summarization dataset
- 200+ years of Supreme Court cases
- "Ground truth" summaries written by Court attorneys and approved by Justices
- Variation in summary styles and compression rates over time
Key findings:
1. A smaller fine-tuned LLM scores well on metrics but has more factual errors.
2. Experts prefer GPT-4 summaries—even over the “ground-truth” syllabuses.
3. ROUGE and similar metrics poorly reflect human preferences.
4. Even LLM-based evaluations still misalign with human judgment.
1. A smaller fine-tuned LLM scores well on metrics but has more factual errors.
2. Experts prefer GPT-4 summaries—even over the “ground-truth” syllabuses.
3. ROUGE and similar metrics poorly reflect human preferences.
4. Even LLM-based evaluations still misalign with human judgment.

May 1, 2025 at 7:25 PM
Key findings:
1. A smaller fine-tuned LLM scores well on metrics but has more factual errors.
2. Experts prefer GPT-4 summaries—even over the “ground-truth” syllabuses.
3. ROUGE and similar metrics poorly reflect human preferences.
4. Even LLM-based evaluations still misalign with human judgment.
1. A smaller fine-tuned LLM scores well on metrics but has more factual errors.
2. Experts prefer GPT-4 summaries—even over the “ground-truth” syllabuses.
3. ROUGE and similar metrics poorly reflect human preferences.
4. Even LLM-based evaluations still misalign with human judgment.
Dataset: huggingface.co/datasets/Chi...
Paper: arxiv.org/abs/2501.00097
When evaluating LLM-generated and human-written summaries, we find interesting discrepancies between automatic metrics, LLM-based evaluation, and human expert judgements.
Paper: arxiv.org/abs/2501.00097
When evaluating LLM-generated and human-written summaries, we find interesting discrepancies between automatic metrics, LLM-based evaluation, and human expert judgements.
ChicagoHAI/CaseSumm · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
May 1, 2025 at 7:25 PM
Dataset: huggingface.co/datasets/Chi...
Paper: arxiv.org/abs/2501.00097
When evaluating LLM-generated and human-written summaries, we find interesting discrepancies between automatic metrics, LLM-based evaluation, and human expert judgements.
Paper: arxiv.org/abs/2501.00097
When evaluating LLM-generated and human-written summaries, we find interesting discrepancies between automatic metrics, LLM-based evaluation, and human expert judgements.
We develop CaseSumm, a comprehensive dataset comprising 25K U.S. Supreme Court opinions and their official syllabuses spanning over 200 years, and conduct a rigorous evaluation of long-document summarization using CaseSumm.
May 1, 2025 at 7:25 PM
We develop CaseSumm, a comprehensive dataset comprising 25K U.S. Supreme Court opinions and their official syllabuses spanning over 200 years, and conduct a rigorous evaluation of long-document summarization using CaseSumm.
Thank you to my excellent collaborators
Qingcheng Zeng, @chenhaotan.bsky.social, @robvoigt.bsky.social, and Alexander Zentefis!
Qingcheng Zeng, @chenhaotan.bsky.social, @robvoigt.bsky.social, and Alexander Zentefis!
November 15, 2024 at 6:56 PM
Thank you to my excellent collaborators
Qingcheng Zeng, @chenhaotan.bsky.social, @robvoigt.bsky.social, and Alexander Zentefis!
Qingcheng Zeng, @chenhaotan.bsky.social, @robvoigt.bsky.social, and Alexander Zentefis!
I’ll be presenting this work at the
EMNLP 2024 Workshop on Narrative Understanding. If you are in Miami, the presentation will be at 3:30pm!
Paper: aclanthology.org/2024.wnu-1.12/
Dataset (soon): mheddaya.com/research/nar...
EMNLP 2024 Workshop on Narrative Understanding. If you are in Miami, the presentation will be at 3:30pm!
Paper: aclanthology.org/2024.wnu-1.12/
Dataset (soon): mheddaya.com/research/nar...

Causal Micro-Narratives
Mourad Heddaya, Qingcheng Zeng, Alexander Zentefis, Rob Voigt, Chenhao Tan. Proceedings of the The 6th Workshop on Narrative Understanding. 2024.
aclanthology.org
November 15, 2024 at 6:56 PM
I’ll be presenting this work at the
EMNLP 2024 Workshop on Narrative Understanding. If you are in Miami, the presentation will be at 3:30pm!
Paper: aclanthology.org/2024.wnu-1.12/
Dataset (soon): mheddaya.com/research/nar...
EMNLP 2024 Workshop on Narrative Understanding. If you are in Miami, the presentation will be at 3:30pm!
Paper: aclanthology.org/2024.wnu-1.12/
Dataset (soon): mheddaya.com/research/nar...
Please reach you if you are interested in this line of work, I’d love to connect in-person or virtually!
November 15, 2024 at 6:56 PM
Please reach you if you are interested in this line of work, I’d love to connect in-person or virtually!
Our ongoing work aims to discover narratives automatically, investigate their geographic and temporal trends, understand their potential spread, and assess their influence on economic indicators.
November 15, 2024 at 6:56 PM
Our ongoing work aims to discover narratives automatically, investigate their geographic and temporal trends, understand their potential spread, and assess their influence on economic indicators.
We're scaling up! Using our fine-tuned models, we're identifying narratives in millions of news articles. Techniques like Design-Based Supervised Learning ensure validity in downstream analyses.
November 15, 2024 at 6:56 PM
We're scaling up! Using our fine-tuned models, we're identifying narratives in millions of news articles. Techniques like Design-Based Supervised Learning ensure validity in downstream analyses.
Even human annotators sometimes disagree on narrative presence, but fine-tuned LLMs mirror these natural disagreements more closely than larger models.
Our error analysis shows some mistakes arise from genuine interpretative ambiguity. Check out the last three examples here:
Our error analysis shows some mistakes arise from genuine interpretative ambiguity. Check out the last three examples here:

November 15, 2024 at 6:56 PM
Even human annotators sometimes disagree on narrative presence, but fine-tuned LLMs mirror these natural disagreements more closely than larger models.
Our error analysis shows some mistakes arise from genuine interpretative ambiguity. Check out the last three examples here:
Our error analysis shows some mistakes arise from genuine interpretative ambiguity. Check out the last three examples here:
Fine-tuning shines in teaching models to spot narratives, unlike in-context learning. GPT-4o struggles, often misclassifying non-narratives as narratives.

November 15, 2024 at 6:56 PM
Fine-tuning shines in teaching models to spot narratives, unlike in-context learning. GPT-4o struggles, often misclassifying non-narratives as narratives.
This is a difficult hierarchical classification task, with many, somestimes semantically similar, classes.
We find that smaller fine-tuned LLMs outperform larger models like GPT-4o, while also offering better scalability and cost efficiency. But they also err differently.
We find that smaller fine-tuned LLMs outperform larger models like GPT-4o, while also offering better scalability and cost efficiency. But they also err differently.

November 15, 2024 at 6:56 PM
This is a difficult hierarchical classification task, with many, somestimes semantically similar, classes.
We find that smaller fine-tuned LLMs outperform larger models like GPT-4o, while also offering better scalability and cost efficiency. But they also err differently.
We find that smaller fine-tuned LLMs outperform larger models like GPT-4o, while also offering better scalability and cost efficiency. But they also err differently.
We define a causal micro-narrative as a sentence-level explanation of a target subject's cause(s) and/or effect(s).
As an application, we propose an ontology for inflation's causes/effects and create a large-scale dataset classifying sentences from U.S. news articles.
As an application, we propose an ontology for inflation's causes/effects and create a large-scale dataset classifying sentences from U.S. news articles.

November 15, 2024 at 6:56 PM
We define a causal micro-narrative as a sentence-level explanation of a target subject's cause(s) and/or effect(s).
As an application, we propose an ontology for inflation's causes/effects and create a large-scale dataset classifying sentences from U.S. news articles.
As an application, we propose an ontology for inflation's causes/effects and create a large-scale dataset classifying sentences from U.S. news articles.
While the importance of narratives has become well recognized, formulating an operational definition remains challenging. Particularly one that is flexible to informal and ambiguous language.
In our work, we address both the conceptual and technical challenges.
In our work, we address both the conceptual and technical challenges.
November 15, 2024 at 6:56 PM
While the importance of narratives has become well recognized, formulating an operational definition remains challenging. Particularly one that is flexible to informal and ambiguous language.
In our work, we address both the conceptual and technical challenges.
In our work, we address both the conceptual and technical challenges.
We focus on sentences but do not make any further assumptions about the syntax or structure of language used to convey a narrative.
📄 aclanthology.org/2024.wnu-1.12/
📄 aclanthology.org/2024.wnu-1.12/
Causal Micro-Narratives
Mourad Heddaya, Qingcheng Zeng, Alexander Zentefis, Rob Voigt, Chenhao Tan. Proceedings of the The 6th Workshop on Narrative Understanding. 2024.
aclanthology.org
November 15, 2024 at 6:56 PM
We focus on sentences but do not make any further assumptions about the syntax or structure of language used to convey a narrative.
📄 aclanthology.org/2024.wnu-1.12/
📄 aclanthology.org/2024.wnu-1.12/