



Machine Learning in Science
@mackelab.bsky.social
We build probabilistic #MachineLearning and #AI Tools for scientific discovery, especially in Neuroscience. Probably not posted by @jakhmack.bsky.social.
📍 @ml4science.bsky.social, Tübingen, Germany
📍 @ml4science.bsky.social, Tübingen, Germany
It goes without saying, but all posters obviously with @jakhmack.bsky.social as well!👨🔬 9/9
September 30, 2025 at 2:06 PM
It goes without saying, but all posters obviously with @jakhmack.bsky.social as well!👨🔬 9/9
IV-21. @byoungsookim.bsky.social will present: Seeing in 3D: Compound eye integration in connectome-constrained models of the fruit fly (joint work with @srinituraga.bsky.social) 8/9
September 30, 2025 at 2:06 PM
IV-21. @byoungsookim.bsky.social will present: Seeing in 3D: Compound eye integration in connectome-constrained models of the fruit fly (joint work with @srinituraga.bsky.social) 8/9
IV-14. Zinovia Stefanidi will present: Progress on building connectome-constrained models of the whole fly optic lobe (joint work with @srinituraga.bsky.social) 7/9
September 30, 2025 at 2:06 PM
IV-14. Zinovia Stefanidi will present: Progress on building connectome-constrained models of the whole fly optic lobe (joint work with @srinituraga.bsky.social) 7/9
Session 4 (Wednesday 14:00):
IV-9: @stewah.bsky.social presents joint work with @danielged.bsky.social: A new perspective on LLM-based model discovery with applications in neuroscience 6/9
IV-9: @stewah.bsky.social presents joint work with @danielged.bsky.social: A new perspective on LLM-based model discovery with applications in neuroscience 6/9
September 30, 2025 at 2:06 PM
Session 4 (Wednesday 14:00):
IV-9: @stewah.bsky.social presents joint work with @danielged.bsky.social: A new perspective on LLM-based model discovery with applications in neuroscience 6/9
IV-9: @stewah.bsky.social presents joint work with @danielged.bsky.social: A new perspective on LLM-based model discovery with applications in neuroscience 6/9
III-9. @raeesmk.bsky.social will present: Modeling Spatial Hearing with Cochlear Implants Using Deep Neural Networks (joint work with @stefanieliebe.bsky.social) 5/9
September 30, 2025 at 2:06 PM
III-9. @raeesmk.bsky.social will present: Modeling Spatial Hearing with Cochlear Implants Using Deep Neural Networks (joint work with @stefanieliebe.bsky.social) 5/9
Session 3 (Wednesday 12:30):
III-6. @matthijspals.bsky.social will present: Sequence memory in distinct subspaces in data-constrained RNNs of human working memory (joint work with @stefanieliebe.bsky.social) 4/9
III-6. @matthijspals.bsky.social will present: Sequence memory in distinct subspaces in data-constrained RNNs of human working memory (joint work with @stefanieliebe.bsky.social) 4/9
September 30, 2025 at 2:06 PM
Session 3 (Wednesday 12:30):
III-6. @matthijspals.bsky.social will present: Sequence memory in distinct subspaces in data-constrained RNNs of human working memory (joint work with @stefanieliebe.bsky.social) 4/9
III-6. @matthijspals.bsky.social will present: Sequence memory in distinct subspaces in data-constrained RNNs of human working memory (joint work with @stefanieliebe.bsky.social) 4/9
II-9. @lulmer.bsky.social will present: Integrating neural activity measurements into connectome-constrained models (joint work with @srinituraga.bsky.social) 3/9
September 30, 2025 at 2:06 PM
II-9. @lulmer.bsky.social will present: Integrating neural activity measurements into connectome-constrained models (joint work with @srinituraga.bsky.social) 3/9
Session 2 (Tuesday 18:00):
II-4. Isaac Omolayo will present: Contrastive Learning for Predicting Neural Activity in Connectome Constrained Deep Mechanistic Networks 2/9
II-4. Isaac Omolayo will present: Contrastive Learning for Predicting Neural Activity in Connectome Constrained Deep Mechanistic Networks 2/9
September 30, 2025 at 2:06 PM
Session 2 (Tuesday 18:00):
II-4. Isaac Omolayo will present: Contrastive Learning for Predicting Neural Activity in Connectome Constrained Deep Mechanistic Networks 2/9
II-4. Isaac Omolayo will present: Contrastive Learning for Predicting Neural Activity in Connectome Constrained Deep Mechanistic Networks 2/9
Joint work of @vetterj.bsky.social, Manuel Gloeckler, @danielged.bsky.social, and @jakhmack.bsky.social
@ml4science.bsky.social, @tuebingen-ai.bsky.social, @unituebingen.bsky.social
@ml4science.bsky.social, @tuebingen-ai.bsky.social, @unituebingen.bsky.social
July 23, 2025 at 2:28 PM
Joint work of @vetterj.bsky.social, Manuel Gloeckler, @danielged.bsky.social, and @jakhmack.bsky.social
@ml4science.bsky.social, @tuebingen-ai.bsky.social, @unituebingen.bsky.social
@ml4science.bsky.social, @tuebingen-ai.bsky.social, @unituebingen.bsky.social
📄 Check out the full paper for methods, experiments and more cool stuff: arxiv.org/abs/2504.17660
💻 Code is available: github.com/mackelab/npe...
💻 Code is available: github.com/mackelab/npe...

Effortless, Simulation-Efficient Bayesian Inference using Tabular Foundation Models
Simulation-based inference (SBI) offers a flexible and general approach to performing Bayesian inference: In SBI, a neural network is trained on synthetic data simulated from a model and used to rapid...
arxiv.org
July 23, 2025 at 2:28 PM
📄 Check out the full paper for methods, experiments and more cool stuff: arxiv.org/abs/2504.17660
💻 Code is available: github.com/mackelab/npe...
💻 Code is available: github.com/mackelab/npe...
💡 Takeaway:
By leveraging foundation models like TabPFN, we can make SBI training-free, simulation-efficient, and easy to use.
This work is another step toward user-friendly Bayesian inference for a broader science and engineering community.
By leveraging foundation models like TabPFN, we can make SBI training-free, simulation-efficient, and easy to use.
This work is another step toward user-friendly Bayesian inference for a broader science and engineering community.
July 23, 2025 at 2:28 PM
💡 Takeaway:
By leveraging foundation models like TabPFN, we can make SBI training-free, simulation-efficient, and easy to use.
This work is another step toward user-friendly Bayesian inference for a broader science and engineering community.
By leveraging foundation models like TabPFN, we can make SBI training-free, simulation-efficient, and easy to use.
This work is another step toward user-friendly Bayesian inference for a broader science and engineering community.
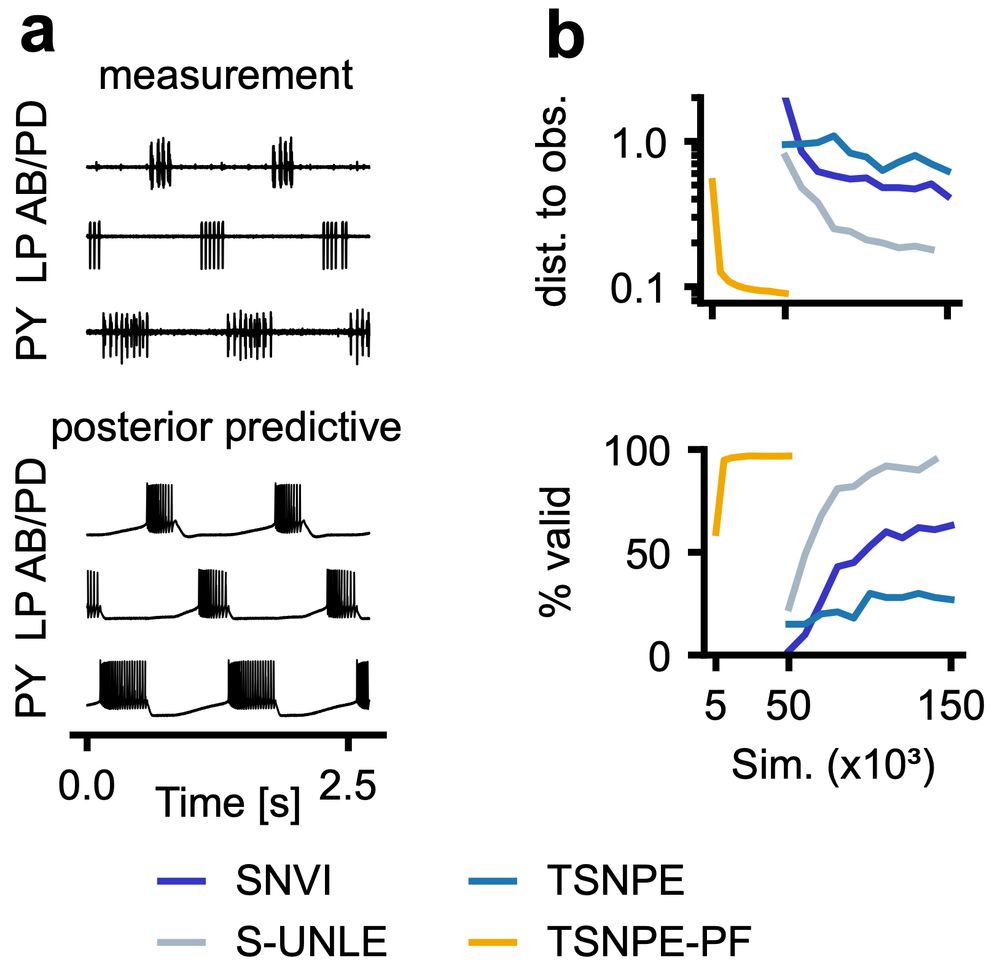
But does it scale to complex real-world problems? We tested it on two challenging Hodgkin-Huxley-type models:
🧠 single-compartment neuron
🦀 31-parameter crab pyloric network
NPE-PF delivers tight posteriors & accurate predictions with far fewer simulations than previous methods.
🧠 single-compartment neuron
🦀 31-parameter crab pyloric network
NPE-PF delivers tight posteriors & accurate predictions with far fewer simulations than previous methods.
July 23, 2025 at 2:28 PM
But does it scale to complex real-world problems? We tested it on two challenging Hodgkin-Huxley-type models:
🧠 single-compartment neuron
🦀 31-parameter crab pyloric network
NPE-PF delivers tight posteriors & accurate predictions with far fewer simulations than previous methods.
🧠 single-compartment neuron
🦀 31-parameter crab pyloric network
NPE-PF delivers tight posteriors & accurate predictions with far fewer simulations than previous methods.
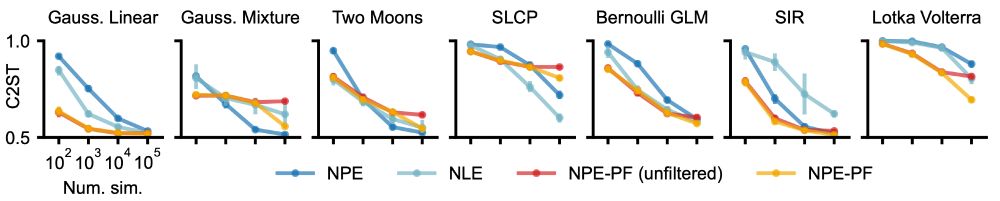
What you get with NPE-PF:
🚫 No need to train inference nets or tune hyperparameters.
🌟 Competitive or superior performance vs. standard SBI methods.
🚀 Especially strong performance for smaller simulation budgets.
🔄 Filtering to handle large datasets + support for sequential inference.
🚫 No need to train inference nets or tune hyperparameters.
🌟 Competitive or superior performance vs. standard SBI methods.
🚀 Especially strong performance for smaller simulation budgets.
🔄 Filtering to handle large datasets + support for sequential inference.
July 23, 2025 at 2:28 PM
What you get with NPE-PF:
🚫 No need to train inference nets or tune hyperparameters.
🌟 Competitive or superior performance vs. standard SBI methods.
🚀 Especially strong performance for smaller simulation budgets.
🔄 Filtering to handle large datasets + support for sequential inference.
🚫 No need to train inference nets or tune hyperparameters.
🌟 Competitive or superior performance vs. standard SBI methods.
🚀 Especially strong performance for smaller simulation budgets.
🔄 Filtering to handle large datasets + support for sequential inference.
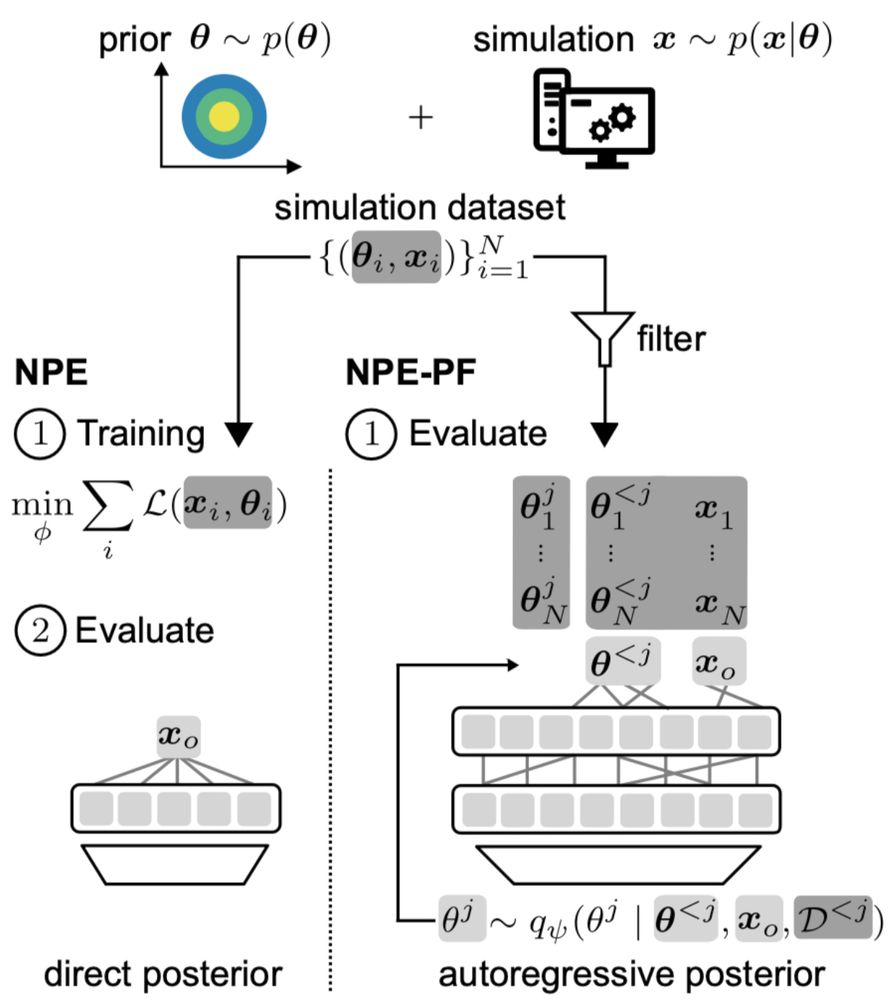
The key idea:
TabPFN, originally trained for tabular regression and classification, can estimate posteriors by autoregressively modeling one parameter dimension after the other.
It’s remarkably effective, even though TabPFN was not designed for SBI.
TabPFN, originally trained for tabular regression and classification, can estimate posteriors by autoregressively modeling one parameter dimension after the other.
It’s remarkably effective, even though TabPFN was not designed for SBI.
July 23, 2025 at 2:28 PM
The key idea:
TabPFN, originally trained for tabular regression and classification, can estimate posteriors by autoregressively modeling one parameter dimension after the other.
It’s remarkably effective, even though TabPFN was not designed for SBI.
TabPFN, originally trained for tabular regression and classification, can estimate posteriors by autoregressively modeling one parameter dimension after the other.
It’s remarkably effective, even though TabPFN was not designed for SBI.
SBI usually relies on training neural nets on simulated data to approximate posteriors. But:
⚠️ Simulators can be expensive
⚠️ Training & tuning neural nets can be tedious
Our method NPE-PF repurposes TabPFN as an in-context density estimator for training-free, simulation-efficient Bayesian inference.
⚠️ Simulators can be expensive
⚠️ Training & tuning neural nets can be tedious
Our method NPE-PF repurposes TabPFN as an in-context density estimator for training-free, simulation-efficient Bayesian inference.
July 23, 2025 at 2:28 PM
SBI usually relies on training neural nets on simulated data to approximate posteriors. But:
⚠️ Simulators can be expensive
⚠️ Training & tuning neural nets can be tedious
Our method NPE-PF repurposes TabPFN as an in-context density estimator for training-free, simulation-efficient Bayesian inference.
⚠️ Simulators can be expensive
⚠️ Training & tuning neural nets can be tedious
Our method NPE-PF repurposes TabPFN as an in-context density estimator for training-free, simulation-efficient Bayesian inference.
This work was enabled and funded by an innovation project of @ml4science.bsky.social
June 11, 2025 at 6:17 PM
This work was enabled and funded by an innovation project of @ml4science.bsky.social
Congrats to @gmoss13.bsky.social, @coschroeder.bsky.social, @jakhmack.bsky.social , together with our great collaborators Vjeran Višnjević, Olaf Eisen, @oraschewski.bsky.social, Reinhard Drews. Thank you to @tuebingen-ai.bsky.social and @awi.de for marking this work possible.
June 11, 2025 at 11:47 AM
Congrats to @gmoss13.bsky.social, @coschroeder.bsky.social, @jakhmack.bsky.social , together with our great collaborators Vjeran Višnjević, Olaf Eisen, @oraschewski.bsky.social, Reinhard Drews. Thank you to @tuebingen-ai.bsky.social and @awi.de for marking this work possible.
If you’re interested to learn more, check out the paper and code, or get in touch with @gmoss13.bsky.social
Code: github.com/mackelab/sbi...
Paper: www.cambridge.org/core/journal...
Code: github.com/mackelab/sbi...
Paper: www.cambridge.org/core/journal...
June 11, 2025 at 11:47 AM
If you’re interested to learn more, check out the paper and code, or get in touch with @gmoss13.bsky.social
Code: github.com/mackelab/sbi...
Paper: www.cambridge.org/core/journal...
Code: github.com/mackelab/sbi...
Paper: www.cambridge.org/core/journal...
We obtain posterior distributions over ice accumulation and melting rates for Ekström Ice Shelf over the past hundreds of years. This allows us to make quantitative statements about the history of the atmospheric and oceanic conditions.
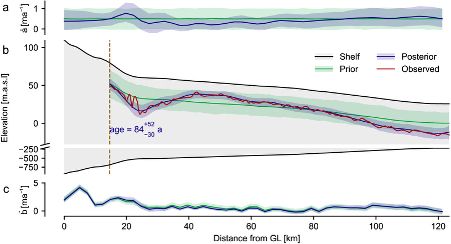
June 11, 2025 at 11:47 AM
We obtain posterior distributions over ice accumulation and melting rates for Ekström Ice Shelf over the past hundreds of years. This allows us to make quantitative statements about the history of the atmospheric and oceanic conditions.