



@lucaschubu.bsky.social
Excited to say our paper got accepted to ICML! We added new findings including this: models fine-tuned on a visual counterfactual reasoning task do not generalize to the underlying factual physical reasoning task, even with test images matched to the fine-tuning data set.

June 2, 2025 at 7:45 AM
Excited to say our paper got accepted to ICML! We added new findings including this: models fine-tuned on a visual counterfactual reasoning task do not generalize to the underlying factual physical reasoning task, even with test images matched to the fine-tuning data set.
Finally, we fine-tuning a model on human responses for the synthetic intuitive physics dataset. We find that this model not only shows a higher agreement with human observers, but that it also generalizes better to the real block towers.

February 25, 2025 at 10:45 AM
Finally, we fine-tuning a model on human responses for the synthetic intuitive physics dataset. We find that this model not only shows a higher agreement with human observers, but that it also generalizes better to the real block towers.
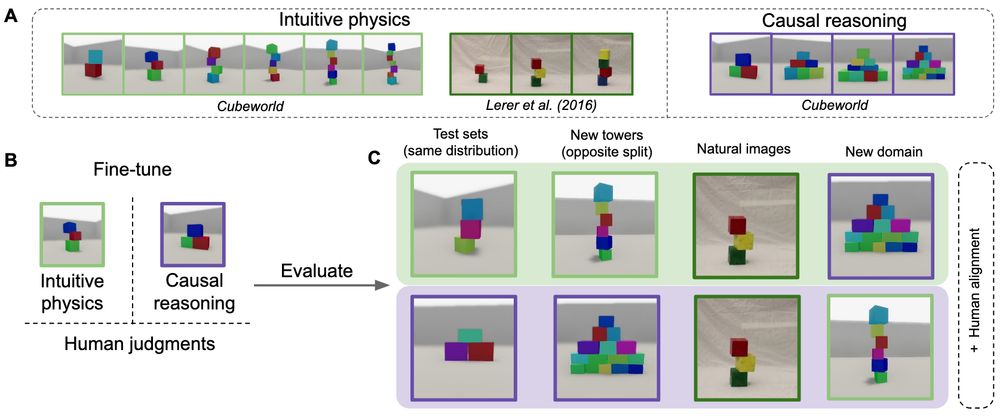
Models fine-tuned on intuitive physics also do not robustly generalize to an almost identical but visually different dataset (Lerer columns below). They are fine-tuned on synthetic block towers, while the dataset by Lerer et al. features pictures of real block towers.

February 25, 2025 at 10:45 AM
Models fine-tuned on intuitive physics also do not robustly generalize to an almost identical but visually different dataset (Lerer columns below). They are fine-tuned on synthetic block towers, while the dataset by Lerer et al. features pictures of real block towers.
We fine-tuned models on tasks from intuitive physics and causal reasoning. Models fine-tuned on intuitive physics (first two rows) do not perform well on causal reasoning and vice versa. Models fine-tuned on both perform well in either domain, showing models can learn both.

February 25, 2025 at 10:45 AM
We fine-tuned models on tasks from intuitive physics and causal reasoning. Models fine-tuned on intuitive physics (first two rows) do not perform well on causal reasoning and vice versa. Models fine-tuned on both perform well in either domain, showing models can learn both.
In previous work we found that VLMs fall short of human visual cognition. To make them better, we fine-tuned them on visual cognition tasks. We find that while this improves performance on the fine-tuning task, it does not lead to models that generalize to other related tasks:
February 25, 2025 at 10:45 AM
In previous work we found that VLMs fall short of human visual cognition. To make them better, we fine-tuned them on visual cognition tasks. We find that while this improves performance on the fine-tuning task, it does not lead to models that generalize to other related tasks: