



Leqi Liu
@leqiliu.bsky.social
AI/ML Researcher | Assistant Professor at UT Austin | Postdoc at Princeton PLI | PhD, Machine Learning Department, CMU. Research goal: Building controllable machine intelligence that serves humanity safely. leqiliu.github.io
Final message: LLMs can improve from failure — if you ask the right question.
“Explain the answer” > “Try again”
Paper: arxiv.org/abs/2507.02834
Joint work with @ruiyang-zhou.bsky.social and Shuozhe Li.
“Explain the answer” > “Try again”
Paper: arxiv.org/abs/2507.02834
Joint work with @ruiyang-zhou.bsky.social and Shuozhe Li.

ExPO: Unlocking Hard Reasoning with Self-Explanation-Guided Reinforcement Learning
Recent advances in large language models have been driven by reinforcement learning (RL)-style post-training, which improves reasoning by optimizing model outputs based on reward or preference signals...
arxiv.org
July 22, 2025 at 5:09 PM
Final message: LLMs can improve from failure — if you ask the right question.
“Explain the answer” > “Try again”
Paper: arxiv.org/abs/2507.02834
Joint work with @ruiyang-zhou.bsky.social and Shuozhe Li.
“Explain the answer” > “Try again”
Paper: arxiv.org/abs/2507.02834
Joint work with @ruiyang-zhou.bsky.social and Shuozhe Li.
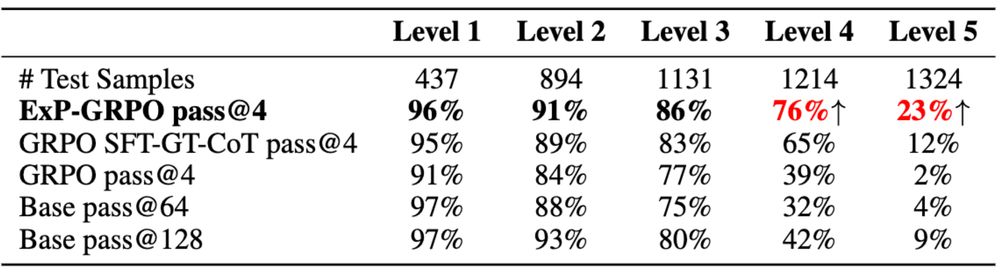
We plug ExPO into:
• DPO (preference-based)
• GRPO (verifier-based RL)
→ No architecture changes
→ No expert supervision
→ Big gains on hard tasks
Results (Qwen2.5-3B-Instruct, MATH level-5):
• DPO (preference-based)
• GRPO (verifier-based RL)
→ No architecture changes
→ No expert supervision
→ Big gains on hard tasks
Results (Qwen2.5-3B-Instruct, MATH level-5):
July 22, 2025 at 5:09 PM
We plug ExPO into:
• DPO (preference-based)
• GRPO (verifier-based RL)
→ No architecture changes
→ No expert supervision
→ Big gains on hard tasks
Results (Qwen2.5-3B-Instruct, MATH level-5):
• DPO (preference-based)
• GRPO (verifier-based RL)
→ No architecture changes
→ No expert supervision
→ Big gains on hard tasks
Results (Qwen2.5-3B-Instruct, MATH level-5):
Our solution:
Ask the model to explain the correct answer — even when it couldn’t solve the problem.
These self-explanations are:
✅ in-distribution
✅ richer than failed CoTs
✅ Offer better guidance than expert-written CoTs
We train on them. We call it ExPO.
Ask the model to explain the correct answer — even when it couldn’t solve the problem.
These self-explanations are:
✅ in-distribution
✅ richer than failed CoTs
✅ Offer better guidance than expert-written CoTs
We train on them. We call it ExPO.
July 22, 2025 at 5:09 PM
Our solution:
Ask the model to explain the correct answer — even when it couldn’t solve the problem.
These self-explanations are:
✅ in-distribution
✅ richer than failed CoTs
✅ Offer better guidance than expert-written CoTs
We train on them. We call it ExPO.
Ask the model to explain the correct answer — even when it couldn’t solve the problem.
These self-explanations are:
✅ in-distribution
✅ richer than failed CoTs
✅ Offer better guidance than expert-written CoTs
We train on them. We call it ExPO.
Most RL post-training methods only work when the model has some chance to get answers right. But what if it mostly gets everything wrong?
NO correct trajectory sampled -> NO learning signal -> Model stays the same and unlearns due to KL constraint
This happens often in hard reasoning tasks.
NO correct trajectory sampled -> NO learning signal -> Model stays the same and unlearns due to KL constraint
This happens often in hard reasoning tasks.
July 22, 2025 at 5:09 PM
Most RL post-training methods only work when the model has some chance to get answers right. But what if it mostly gets everything wrong?
NO correct trajectory sampled -> NO learning signal -> Model stays the same and unlearns due to KL constraint
This happens often in hard reasoning tasks.
NO correct trajectory sampled -> NO learning signal -> Model stays the same and unlearns due to KL constraint
This happens often in hard reasoning tasks.
This has huge practical implications! It opens the door to using small, efficient models as sandboxes to probe, understand, and even steer their much larger counterparts.
Paper: arxiv.org/abs/2506.00653
Joint work with Femi Bello, @anubrata.bsky.social, Fanzhi Zeng, @fcyin.bsky.social
Paper: arxiv.org/abs/2506.00653
Joint work with Femi Bello, @anubrata.bsky.social, Fanzhi Zeng, @fcyin.bsky.social
Linear Representation Transferability Hypothesis: Leveraging Small Models to Steer Large Models
It has been hypothesized that neural networks with similar architectures trained on similar data learn shared representations relevant to the learning task. We build on this idea by extending the conc...
arxiv.org
July 10, 2025 at 5:26 PM
This has huge practical implications! It opens the door to using small, efficient models as sandboxes to probe, understand, and even steer their much larger counterparts.
Paper: arxiv.org/abs/2506.00653
Joint work with Femi Bello, @anubrata.bsky.social, Fanzhi Zeng, @fcyin.bsky.social
Paper: arxiv.org/abs/2506.00653
Joint work with Femi Bello, @anubrata.bsky.social, Fanzhi Zeng, @fcyin.bsky.social
We tested this by learning an affine map between Gemma-2B and Gemma-9B.
The result? Steering vectors(directions for specific behaviors) from the 2B model successfully guided 9B's outputs.
For example, a "dog-saying" steering vector from 2B made 9B talk more about dogs!
The result? Steering vectors(directions for specific behaviors) from the 2B model successfully guided 9B's outputs.
For example, a "dog-saying" steering vector from 2B made 9B talk more about dogs!
July 10, 2025 at 5:26 PM
We tested this by learning an affine map between Gemma-2B and Gemma-9B.
The result? Steering vectors(directions for specific behaviors) from the 2B model successfully guided 9B's outputs.
For example, a "dog-saying" steering vector from 2B made 9B talk more about dogs!
The result? Steering vectors(directions for specific behaviors) from the 2B model successfully guided 9B's outputs.
For example, a "dog-saying" steering vector from 2B made 9B talk more about dogs!
Here's the core idea: We hypothesize that models trained on similar data learn a **universal set of basis features**. Each model's internal representation space is just a unique, model-specific projection of this shared space.
This means representations learned across models are transferable!
This means representations learned across models are transferable!
July 10, 2025 at 5:26 PM
Here's the core idea: We hypothesize that models trained on similar data learn a **universal set of basis features**. Each model's internal representation space is just a unique, model-specific projection of this shared space.
This means representations learned across models are transferable!
This means representations learned across models are transferable!
4/4 Joint work with Hui Yuan, Yifan Zeng, Yue Wu, Huazheng Wang, Mengdi Wang
Paper: arxiv.org/abs/2410.13828
Check out our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
Paper: arxiv.org/abs/2410.13828
Check out our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
December 14, 2024 at 5:38 PM
4/4 Joint work with Hui Yuan, Yifan Zeng, Yue Wu, Huazheng Wang, Mengdi Wang
Paper: arxiv.org/abs/2410.13828
Check out our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
Paper: arxiv.org/abs/2410.13828
Check out our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
3/4 Wonder how to **resolve** problems coming with gradient entanglement? Our theoretical framework highlights new algorithmic ideas:
- Normalized preference optimization: normalize the chosen and rejected gradient
- Sparse token masking: impose sparsity on the tokens for calculating the margins.
- Normalized preference optimization: normalize the chosen and rejected gradient
- Sparse token masking: impose sparsity on the tokens for calculating the margins.
December 14, 2024 at 5:38 PM
3/4 Wonder how to **resolve** problems coming with gradient entanglement? Our theoretical framework highlights new algorithmic ideas:
- Normalized preference optimization: normalize the chosen and rejected gradient
- Sparse token masking: impose sparsity on the tokens for calculating the margins.
- Normalized preference optimization: normalize the chosen and rejected gradient
- Sparse token masking: impose sparsity on the tokens for calculating the margins.
2/4 The Gradient Entanglement effect becomes particularly concerning when the chosen and rejected gradient inner product is large, which often happens when the two responses are similar!
December 14, 2024 at 5:38 PM
2/4 The Gradient Entanglement effect becomes particularly concerning when the chosen and rejected gradient inner product is large, which often happens when the two responses are similar!
1/4 We demystify the reason behind the synchronized change in chosen and rejected logps: the **Gradient Entanglement** effect! For any margin-based losses (esp. these *PO objectives), the chosen probability will depend on the rejected gradient, and vice versa.
December 14, 2024 at 5:38 PM
1/4 We demystify the reason behind the synchronized change in chosen and rejected logps: the **Gradient Entanglement** effect! For any margin-based losses (esp. these *PO objectives), the chosen probability will depend on the rejected gradient, and vice versa.
4/4 Joint work with Xinyu Li, @ruiyang-zhou.bsky.social,
@zacharylipton.bsky.social
Paper: arxiv.org/abs/2402.05133, Code: github.com/HumainLab/Personalized_RLHF
Check out our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
@zacharylipton.bsky.social
Paper: arxiv.org/abs/2402.05133, Code: github.com/HumainLab/Personalized_RLHF
Check out our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
December 14, 2024 at 5:02 PM
4/4 Joint work with Xinyu Li, @ruiyang-zhou.bsky.social,
@zacharylipton.bsky.social
Paper: arxiv.org/abs/2402.05133, Code: github.com/HumainLab/Personalized_RLHF
Check out our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
@zacharylipton.bsky.social
Paper: arxiv.org/abs/2402.05133, Code: github.com/HumainLab/Personalized_RLHF
Check out our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
3/4 Beyond user preferences indicated in explicit textual format, P-RLHF can learn the nuanced implicit preferences encoded in user preference data. On the largest publicly available preference dataset based on multi-turn dialog (PRISM), P-RLHF outperforms all strong baselines in winrate by 10-20%.
December 14, 2024 at 5:02 PM
3/4 Beyond user preferences indicated in explicit textual format, P-RLHF can learn the nuanced implicit preferences encoded in user preference data. On the largest publicly available preference dataset based on multi-turn dialog (PRISM), P-RLHF outperforms all strong baselines in winrate by 10-20%.
2/4 For any base preference optimization (*PO) algorithm, P-RLHF can create its corresponding personalized version P-*PO, allowing for **flexible** choice of alignment algorithms.
December 14, 2024 at 5:02 PM
2/4 For any base preference optimization (*PO) algorithm, P-RLHF can create its corresponding personalized version P-*PO, allowing for **flexible** choice of alignment algorithms.
1/4 Personalized-RLHF (P-RLHF) uses a **light-weight** user model to learn user embeddings, which serve as a soft prompt for generating personalized responses. The user model is much smaller (10-100x smaller) compared to the LORA adapters used for fine-tuning the language model.
December 14, 2024 at 5:02 PM
1/4 Personalized-RLHF (P-RLHF) uses a **light-weight** user model to learn user embeddings, which serve as a soft prompt for generating personalized responses. The user model is much smaller (10-100x smaller) compared to the LORA adapters used for fine-tuning the language model.
4/4 Joint work with: Xinyu Li, Ruiyang Zhou, @zacharylipton.bsky.social
Paper: arxiv.org/abs/2402.05133, Code: github.com/HumainLab/Pe...
Check our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
Paper: arxiv.org/abs/2402.05133, Code: github.com/HumainLab/Pe...
Check our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
December 14, 2024 at 4:39 PM
4/4 Joint work with: Xinyu Li, Ruiyang Zhou, @zacharylipton.bsky.social
Paper: arxiv.org/abs/2402.05133, Code: github.com/HumainLab/Pe...
Check our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
Paper: arxiv.org/abs/2402.05133, Code: github.com/HumainLab/Pe...
Check our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
3/4 Beyond user preferences indicated in explicit textual format, P-RLHF can learn the nuanced implicit preferences encoded in their preference data. On the largest publicly available preference dataset based on multi-turn dialog (PRISM), P-RLHF outperforms all strong baselines in winrate by 10-20%.
December 14, 2024 at 4:39 PM
3/4 Beyond user preferences indicated in explicit textual format, P-RLHF can learn the nuanced implicit preferences encoded in their preference data. On the largest publicly available preference dataset based on multi-turn dialog (PRISM), P-RLHF outperforms all strong baselines in winrate by 10-20%.
2/4 For any base preference optimization (*PO) algorithm, P-RLHF can create its corresponding personalized version P-*PO, allowing for **flexible** choice of alignment algorithms.
December 14, 2024 at 4:39 PM
2/4 For any base preference optimization (*PO) algorithm, P-RLHF can create its corresponding personalized version P-*PO, allowing for **flexible** choice of alignment algorithms.
1/4 Personalized-RLHF (P-RLHF) uses a **light-weight** user model that maps user information to their embeddings, which serve as a soft prompt for generating personalized response. The user model is much smaller (10-100x smaller) compared to the LORA adapters used for fine-tuning the LM.
December 14, 2024 at 4:39 PM
1/4 Personalized-RLHF (P-RLHF) uses a **light-weight** user model that maps user information to their embeddings, which serve as a soft prompt for generating personalized response. The user model is much smaller (10-100x smaller) compared to the LORA adapters used for fine-tuning the LM.