




Mingxuan (Aldous) Li
@itea1001.bsky.social
https://itea1001.github.io/
Rising third-year undergrad at the University of Chicago, working on LLM tool use, evaluation, and hypothesis generation.
Rising third-year undergrad at the University of Chicago, working on LLM tool use, evaluation, and hypothesis generation.
12/n Acknowledgments:
Great thanks to my wonderful collaborators Hanchen Li and my advisor @chenhaotan.bsky.social!
Check out full paper here at (arxiv.org/abs/2504.07174)
Great thanks to my wonderful collaborators Hanchen Li and my advisor @chenhaotan.bsky.social!
Check out full paper here at (arxiv.org/abs/2504.07174)

HypoEval: Hypothesis-Guided Evaluation for Natural Language Generation
Large language models (LLMs) have demonstrated great potential for automating the evaluation of natural language generation. Previous frameworks of LLM-as-a-judge fall short in two ways: they either u...
arxiv.org
May 12, 2025 at 7:29 PM
12/n Acknowledgments:
Great thanks to my wonderful collaborators Hanchen Li and my advisor @chenhaotan.bsky.social!
Check out full paper here at (arxiv.org/abs/2504.07174)
Great thanks to my wonderful collaborators Hanchen Li and my advisor @chenhaotan.bsky.social!
Check out full paper here at (arxiv.org/abs/2504.07174)
11/n Closing thoughts:
This is a sample-efficient method for LLM-as-a-judge, grounded upon human judgments — paving the way for personalized evaluators and alignment!
This is a sample-efficient method for LLM-as-a-judge, grounded upon human judgments — paving the way for personalized evaluators and alignment!
May 12, 2025 at 7:27 PM
11/n Closing thoughts:
This is a sample-efficient method for LLM-as-a-judge, grounded upon human judgments — paving the way for personalized evaluators and alignment!
This is a sample-efficient method for LLM-as-a-judge, grounded upon human judgments — paving the way for personalized evaluators and alignment!
10/n Code:
We have released to repositories for HypoEval:
For replicating results/building upon: github.com/ChicagoHAI/H...
For off-the-shelf 0-shot evaluators for summaries and stories🚀: github.com/ChicagoHAI/H...
We have released to repositories for HypoEval:
For replicating results/building upon: github.com/ChicagoHAI/H...
For off-the-shelf 0-shot evaluators for summaries and stories🚀: github.com/ChicagoHAI/H...

GitHub - ChicagoHAI/HypoEval-Gen: Repository for HypoEval paper (Hypothesis-Guided Evaluation for Natural Language Generation)
Repository for HypoEval paper (Hypothesis-Guided Evaluation for Natural Language Generation) - ChicagoHAI/HypoEval-Gen
github.com
May 12, 2025 at 7:26 PM
10/n Code:
We have released to repositories for HypoEval:
For replicating results/building upon: github.com/ChicagoHAI/H...
For off-the-shelf 0-shot evaluators for summaries and stories🚀: github.com/ChicagoHAI/H...
We have released to repositories for HypoEval:
For replicating results/building upon: github.com/ChicagoHAI/H...
For off-the-shelf 0-shot evaluators for summaries and stories🚀: github.com/ChicagoHAI/H...
9/n Why HypoEval matters:
We push forward LLM-as-a-judge research by showing you can get:
Sample efficiency
Interpretable automated evaluation
Strong human alignment
…without massive fine-tuning.
We push forward LLM-as-a-judge research by showing you can get:
Sample efficiency
Interpretable automated evaluation
Strong human alignment
…without massive fine-tuning.
May 12, 2025 at 7:26 PM
9/n Why HypoEval matters:
We push forward LLM-as-a-judge research by showing you can get:
Sample efficiency
Interpretable automated evaluation
Strong human alignment
…without massive fine-tuning.
We push forward LLM-as-a-judge research by showing you can get:
Sample efficiency
Interpretable automated evaluation
Strong human alignment
…without massive fine-tuning.
8/n 🔬 Ablation insights:
Dropping hypothesis generation → performance drops ~7%
Combining all hypotheses into one criterion → performance drops ~8% (Better to let LLMs rate one sub-dimension at a time!)
Dropping hypothesis generation → performance drops ~7%
Combining all hypotheses into one criterion → performance drops ~8% (Better to let LLMs rate one sub-dimension at a time!)
May 12, 2025 at 7:26 PM
8/n 🔬 Ablation insights:
Dropping hypothesis generation → performance drops ~7%
Combining all hypotheses into one criterion → performance drops ~8% (Better to let LLMs rate one sub-dimension at a time!)
Dropping hypothesis generation → performance drops ~7%
Combining all hypotheses into one criterion → performance drops ~8% (Better to let LLMs rate one sub-dimension at a time!)
7/n 💪 What’s robust?
✅ Works across out-of-distribution (OOD) tasks
✅ Generated hypothesis can be transferred to different LLMs (e.g., GPT-4o-mini ↔ LLAMA-3.3-70B)
✅ Reduces sensitivity to prompt variations compared to direct scoring
✅ Works across out-of-distribution (OOD) tasks
✅ Generated hypothesis can be transferred to different LLMs (e.g., GPT-4o-mini ↔ LLAMA-3.3-70B)
✅ Reduces sensitivity to prompt variations compared to direct scoring
May 12, 2025 at 7:25 PM
7/n 💪 What’s robust?
✅ Works across out-of-distribution (OOD) tasks
✅ Generated hypothesis can be transferred to different LLMs (e.g., GPT-4o-mini ↔ LLAMA-3.3-70B)
✅ Reduces sensitivity to prompt variations compared to direct scoring
✅ Works across out-of-distribution (OOD) tasks
✅ Generated hypothesis can be transferred to different LLMs (e.g., GPT-4o-mini ↔ LLAMA-3.3-70B)
✅ Reduces sensitivity to prompt variations compared to direct scoring
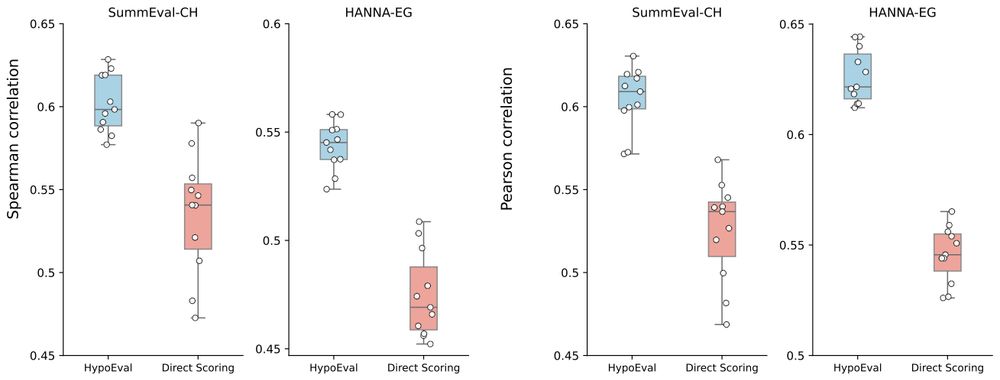
6/n 🏆 Where did we test it?
Across summarization (SummEval, NewsRoom) and story generation (HANNA, WritingPrompt)
We show state-of-the-art correlations with human judgments, for both rankings (Spearman correlation) and scores (Pearson correlation)! 📈
Across summarization (SummEval, NewsRoom) and story generation (HANNA, WritingPrompt)
We show state-of-the-art correlations with human judgments, for both rankings (Spearman correlation) and scores (Pearson correlation)! 📈
May 12, 2025 at 7:25 PM
6/n 🏆 Where did we test it?
Across summarization (SummEval, NewsRoom) and story generation (HANNA, WritingPrompt)
We show state-of-the-art correlations with human judgments, for both rankings (Spearman correlation) and scores (Pearson correlation)! 📈
Across summarization (SummEval, NewsRoom) and story generation (HANNA, WritingPrompt)
We show state-of-the-art correlations with human judgments, for both rankings (Spearman correlation) and scores (Pearson correlation)! 📈
5/n Why is this better?
By combining small-scale human data + literature + non-binary checklists, HypoEval:
🔹 Outperforms G-Eval by ~12%
🔹 Beats fine-tuned models using 3x more human labels
🔹 Adds interpretable evaluation
By combining small-scale human data + literature + non-binary checklists, HypoEval:
🔹 Outperforms G-Eval by ~12%
🔹 Beats fine-tuned models using 3x more human labels
🔹 Adds interpretable evaluation
May 12, 2025 at 7:24 PM
5/n Why is this better?
By combining small-scale human data + literature + non-binary checklists, HypoEval:
🔹 Outperforms G-Eval by ~12%
🔹 Beats fine-tuned models using 3x more human labels
🔹 Adds interpretable evaluation
By combining small-scale human data + literature + non-binary checklists, HypoEval:
🔹 Outperforms G-Eval by ~12%
🔹 Beats fine-tuned models using 3x more human labels
🔹 Adds interpretable evaluation
4/n These hypotheses break down complex evaluation rubric (ex. “Is this summary comprehensive?”) into sub-dimensions an LLM can score clearly. ✅✅✅

May 12, 2025 at 7:24 PM
4/n These hypotheses break down complex evaluation rubric (ex. “Is this summary comprehensive?”) into sub-dimensions an LLM can score clearly. ✅✅✅
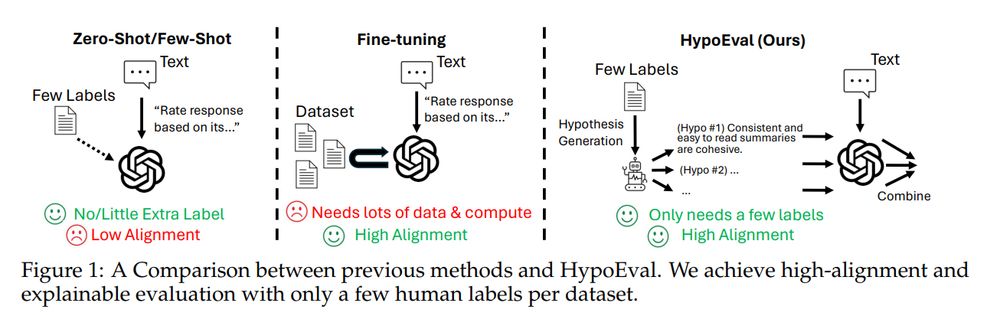
3/n 🌟 Our solution: HypoEval
Building upon SOTA hypothesis generation methods, we generate hypotheses — decomposed rubrics (similar to checklists, but more systematic and explainable) — from existing literature and just 30 human annotations (scores) of texts.
Building upon SOTA hypothesis generation methods, we generate hypotheses — decomposed rubrics (similar to checklists, but more systematic and explainable) — from existing literature and just 30 human annotations (scores) of texts.
May 12, 2025 at 7:24 PM
3/n 🌟 Our solution: HypoEval
Building upon SOTA hypothesis generation methods, we generate hypotheses — decomposed rubrics (similar to checklists, but more systematic and explainable) — from existing literature and just 30 human annotations (scores) of texts.
Building upon SOTA hypothesis generation methods, we generate hypotheses — decomposed rubrics (similar to checklists, but more systematic and explainable) — from existing literature and just 30 human annotations (scores) of texts.
2/n What’s the problem?
Most LLM-as-a-judge studies either:
❌ Achieve lower alignment with humans
⚙️ Requires extensive fine-tuning -> expensive data and compute.
❓ Lack of interpretability
Most LLM-as-a-judge studies either:
❌ Achieve lower alignment with humans
⚙️ Requires extensive fine-tuning -> expensive data and compute.
❓ Lack of interpretability
May 12, 2025 at 7:23 PM
2/n What’s the problem?
Most LLM-as-a-judge studies either:
❌ Achieve lower alignment with humans
⚙️ Requires extensive fine-tuning -> expensive data and compute.
❓ Lack of interpretability
Most LLM-as-a-judge studies either:
❌ Achieve lower alignment with humans
⚙️ Requires extensive fine-tuning -> expensive data and compute.
❓ Lack of interpretability