




Interactive Data Lab
@idl.uw.edu
Visualization & data analysis research at the University of Washington. In a prior life was the Stanford Vis Group. https://idl.uw.edu
DracoGPT was led by Will Wang, in collaboration with Mitchell Gordon, Leilani Battle, and @jheer.org. For more, see the VIS'24 paper "DracoGPT: Extracting Visualization Design Preferences from Large Language Models" idl.uw.edu/papers/draco...
November 26, 2024 at 7:12 PM
DracoGPT was led by Will Wang, in collaboration with Mitchell Gordon, Leilani Battle, and @jheer.org. For more, see the VIS'24 paper "DracoGPT: Extracting Visualization Design Preferences from Large Language Models" idl.uw.edu/papers/draco...
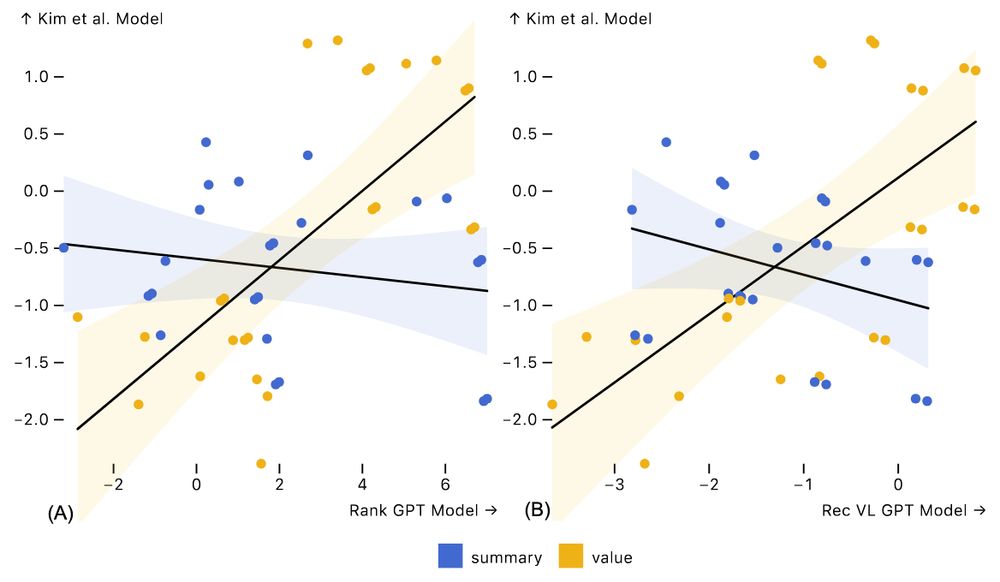
For value comparison tasks, GPT-4 Turbo mostly aligns with human performance data. But for summary tasks, the GPT responses are uncorrelated and likely unhelpful! This may be due to much research and punditry on value comparison, but less attention to aggregate perception, biasing LLM training data.
November 26, 2024 at 7:12 PM
For value comparison tasks, GPT-4 Turbo mostly aligns with human performance data. But for summary tasks, the GPT responses are uncorrelated and likely unhelpful! This may be due to much research and punditry on value comparison, but less attention to aggregate perception, biasing LLM training data.
We applied DracoGPT using experimental data from Younghoon Kim et al. (EuroVis'18) that spans a variety of plots, data distributions, and tasks (comparing individual values vs. aggregate properties). The plots show chart "scores" from two GPT-4 Turbo prompting methods vs. human performance data.
November 26, 2024 at 7:12 PM
We applied DracoGPT using experimental data from Younghoon Kim et al. (EuroVis'18) that spans a variety of plots, data distributions, and tasks (comparing individual values vs. aggregate properties). The plots show chart "scores" from two GPT-4 Turbo prompting methods vs. human performance data.
DracoGPT prompts an LLM to rank or recommend charts, and uses the results to create new training pairs. It then learns constraint weights to model the design preferences expressed by the LLM. We can compare different fitted knowledge bases to see how their design choices align or diverge.
November 26, 2024 at 7:12 PM
DracoGPT prompts an LLM to rank or recommend charts, and uses the results to create new training pairs. It then learns constraint weights to model the design preferences expressed by the LLM. We can compare different fitted knowledge bases to see how their design choices align or diverge.
Draco represents visualizations as a set of facts (about data & encodings) and constraints (preferences about encodings, scales, etc - such as if a bar chart has a zero baseline). From labeled chart pairs, we learn constraint weights ("costs") that balance competing constraints to "score" a chart.
November 26, 2024 at 7:12 PM
Draco represents visualizations as a set of facts (about data & encodings) and constraints (preferences about encodings, scales, etc - such as if a bar chart has a zero baseline). From labeled chart pairs, we learn constraint weights ("costs") that balance competing constraints to "score" a chart.