



Hannah Waight
@hwaight.bsky.social
Assistant Professor University of Oregon Sociology | Former Postdoc NYU CSMaP | Ph.D. Princeton Sociology | Research on media, information, politics, China, computational social science | Opinions are my own | https://hwaight.github.io/
Thank you for fighting for our public land @wyden.senate.gov !
June 24, 2025 at 5:31 PM
Thank you for fighting for our public land @wyden.senate.gov !
our sources included Russian, English, and Ukrainian
June 18, 2025 at 9:28 PM
our sources included Russian, English, and Ukrainian
and by you!! @jasong.bsky.social really enjoyed working with you on this paper
June 18, 2025 at 6:24 PM
and by you!! @jasong.bsky.social really enjoyed working with you on this paper
Our replication package is available at this link: doi.org/10.7910/DVN/...
doi.org
June 18, 2025 at 3:56 PM
Our replication package is available at this link: doi.org/10.7910/DVN/...
This article will appear in print in the August SMR special issue on generative AI. Special thanks to Daniel Karell and @thomasdavidson.bsky.social for organizing this special issue! All the articles in the issue are fantastic, please read them all.
June 18, 2025 at 3:56 PM
This article will appear in print in the August SMR special issue on generative AI. Special thanks to Daniel Karell and @thomasdavidson.bsky.social for organizing this special issue! All the articles in the issue are fantastic, please read them all.
Our paper shows that large language models can be used for complex labeling tasks unattainable by previous measures. We furthermore find fine tuning to hold particular promise for these types of tasks. We also provide a framework for out-of-sample validation of our rare event estimand.
June 18, 2025 at 3:56 PM
Our paper shows that large language models can be used for complex labeling tasks unattainable by previous measures. We furthermore find fine tuning to hold particular promise for these types of tasks. We also provide a framework for out-of-sample validation of our rare event estimand.
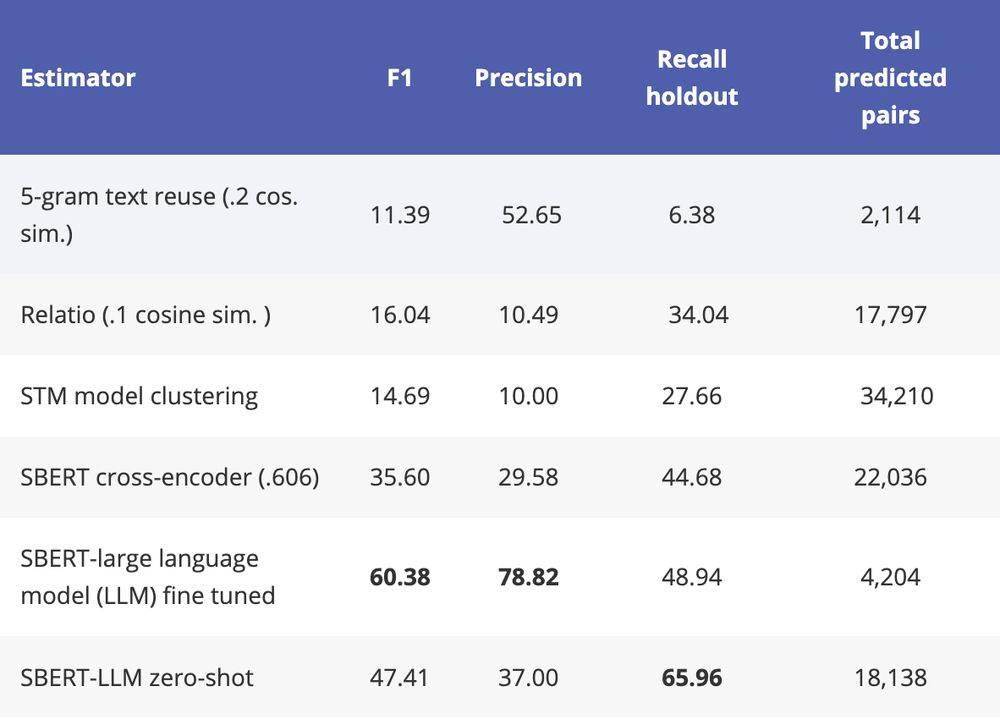
We benchmarked the performance of our approach against a range of existing measures of related estimands. Our measure outperformed these relevant alternatives. We show the performance of our large language model estimators (“SBERT-LLM”) versus considered alternatives in the table below.
June 18, 2025 at 3:56 PM
We benchmarked the performance of our approach against a range of existing measures of related estimands. Our measure outperformed these relevant alternatives. We show the performance of our large language model estimators (“SBERT-LLM”) versus considered alternatives in the table below.
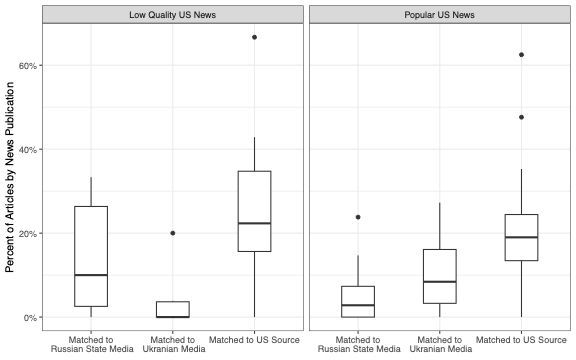
We use this method in a case study of U.S. news website coverage of the war in Ukraine. We show that low quality U.S. news sites were more likely than mainstream U.S. news sites to have overlapping claims (narrative similarity) with Russian newspapers.
June 18, 2025 at 3:56 PM
We use this method in a case study of U.S. news website coverage of the war in Ukraine. We show that low quality U.S. news sites were more likely than mainstream U.S. news sites to have overlapping claims (narrative similarity) with Russian newspapers.
We leverage recent advances in NLP to measure whether two newspaper articles are making the same claims about the same underlying subjects. We use document embeddings to reduce the number of comparisons to a tractable number and large language models for pair annotation.
June 18, 2025 at 3:56 PM
We leverage recent advances in NLP to measure whether two newspaper articles are making the same claims about the same underlying subjects. We use document embeddings to reduce the number of comparisons to a tractable number and large language models for pair annotation.
Researchers are often interested in tracking the flow of ideas and claims across texts. This is a very challenging target to estimate, however, as due to copyright and journalistic norms authors will often reuse information and ideas without using the same words, phrases or even language.
June 18, 2025 at 3:56 PM
Researchers are often interested in tracking the flow of ideas and claims across texts. This is a very challenging target to estimate, however, as due to copyright and journalistic norms authors will often reuse information and ideas without using the same words, phrases or even language.