




Gaël Varoquaux
@gaelvaroquaux.bsky.social
Research & code: Research director @inria
►Data, Health, & Computer science
►Python coder, (co)founder of scikit-learn, joblib, & @probabl.bsky.social
►Sometimes does art photography
►Physics PhD
►Data, Health, & Computer science
►Python coder, (co)founder of scikit-learn, joblib, & @probabl.bsky.social
►Sometimes does art photography
►Physics PhD
Yes!!!
This is what prompted me to write the following paper:
dl.acm.org/doi/full/10....
A lot is explained by narratives and social norms driving research.
We need to build our own narratives, as a research community, this is what we do
This is what prompted me to write the following paper:
dl.acm.org/doi/full/10....
A lot is explained by narratives and social norms driving research.
We need to build our own narratives, as a research community, this is what we do

Hype, Sustainability, and the Price of the Bigger-is-Better Paradigm in AI | Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency
dl.acm.org
November 29, 2025 at 7:58 AM
Yes!!!
This is what prompted me to write the following paper:
dl.acm.org/doi/full/10....
A lot is explained by narratives and social norms driving research.
We need to build our own narratives, as a research community, this is what we do
This is what prompted me to write the following paper:
dl.acm.org/doi/full/10....
A lot is explained by narratives and social norms driving research.
We need to build our own narratives, as a research community, this is what we do
The data structure a bit, though the edges are typed.
A good example of knowledge graph is Wikidata
A good example of knowledge graph is Wikidata
November 28, 2025 at 5:31 PM
The data structure a bit, though the edges are typed.
A good example of knowledge graph is Wikidata
A good example of knowledge graph is Wikidata
Read the paper, it comes with so many experiments and learning
arxiv.org/abs/2507.00965
The code is here: github.com/soda-inria/s...
The papier is well reproducible, and we hope it will unleash more progress in knowledge graph embedding.
We'll present at #NeurIPS and #Eurips
10/10
arxiv.org/abs/2507.00965
The code is here: github.com/soda-inria/s...
The papier is well reproducible, and we hope it will unleash more progress in knowledge graph embedding.
We'll present at #NeurIPS and #Eurips
10/10

Scalable Feature Learning on Huge Knowledge Graphs for Downstream Machine Learning
Many machine learning tasks can benefit from external knowledge. Large knowledge graphs store such knowledge, and embedding methods can be used to distill it into ready-to-use vector representations f...
arxiv.org
November 28, 2025 at 3:46 PM
Read the paper, it comes with so many experiments and learning
arxiv.org/abs/2507.00965
The code is here: github.com/soda-inria/s...
The papier is well reproducible, and we hope it will unleash more progress in knowledge graph embedding.
We'll present at #NeurIPS and #Eurips
10/10
arxiv.org/abs/2507.00965
The code is here: github.com/soda-inria/s...
The papier is well reproducible, and we hope it will unleash more progress in knowledge graph embedding.
We'll present at #NeurIPS and #Eurips
10/10
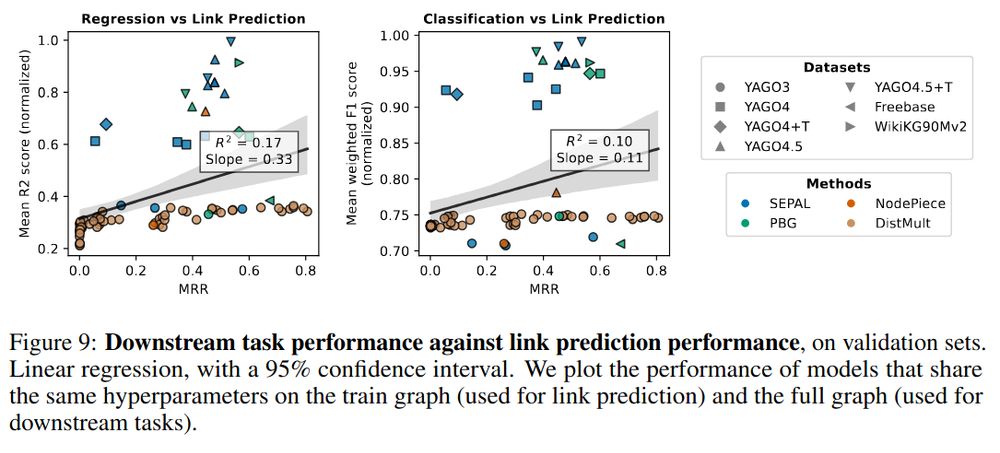
We also learned that performance on link prediction, the canonical task of knowledge-graph embedding, is not a good proxy for downstream utility.
We believe this is because link prediction only needs local structure, unlike downstream tasks
9/10
We believe this is because link prediction only needs local structure, unlike downstream tasks
9/10
November 28, 2025 at 3:46 PM
We also learned that performance on link prediction, the canonical task of knowledge-graph embedding, is not a good proxy for downstream utility.
We believe this is because link prediction only needs local structure, unlike downstream tasks
9/10
We believe this is because link prediction only needs local structure, unlike downstream tasks
9/10
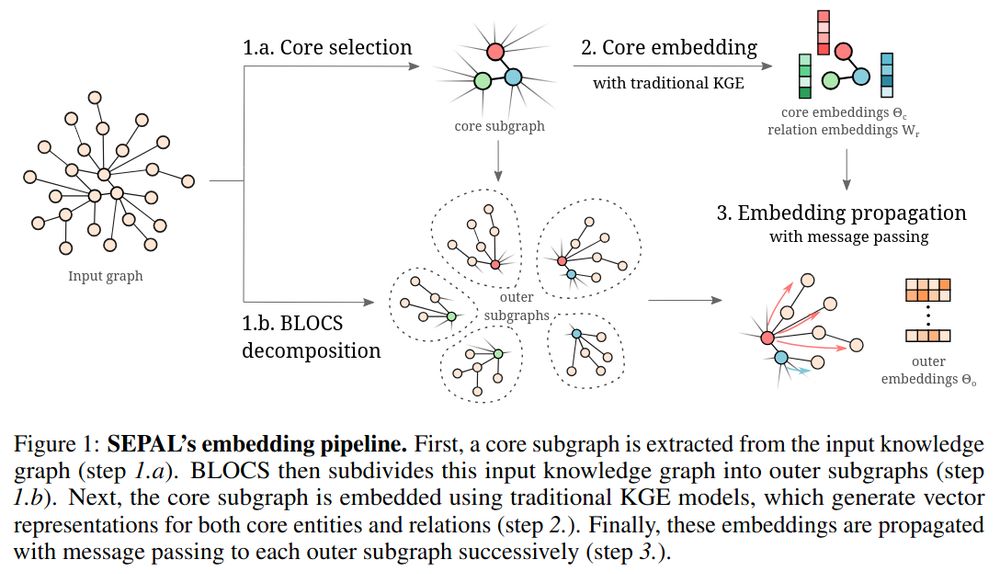
Our approach, SEPAL, combines these elements for feature learning on large knowledge graphs.
It creates feature vectors that lead to better performance on downstream tasks, and it is more scalable.
Larger knowledge graphs give feature vectors that provide downstream value
8/10
It creates feature vectors that lead to better performance on downstream tasks, and it is more scalable.
Larger knowledge graphs give feature vectors that provide downstream value
8/10


November 28, 2025 at 3:46 PM
Our approach, SEPAL, combines these elements for feature learning on large knowledge graphs.
It creates feature vectors that lead to better performance on downstream tasks, and it is more scalable.
Larger knowledge graphs give feature vectors that provide downstream value
8/10
It creates feature vectors that lead to better performance on downstream tasks, and it is more scalable.
Larger knowledge graphs give feature vectors that provide downstream value
8/10
Splitting huge knowledge graphs in sub-parts is actually hard because of the mix of very highly-connected nodes, and a huge long tail hard to reach.
We introduce a procedure that allows for overlap in the blocks, relaxing a lot the difficulty.
7/10
We introduce a procedure that allows for overlap in the blocks, relaxing a lot the difficulty.
7/10

November 28, 2025 at 3:46 PM
Splitting huge knowledge graphs in sub-parts is actually hard because of the mix of very highly-connected nodes, and a huge long tail hard to reach.
We introduce a procedure that allows for overlap in the blocks, relaxing a lot the difficulty.
7/10
We introduce a procedure that allows for overlap in the blocks, relaxing a lot the difficulty.
7/10
To have a very efficient algorithm, we split the graph in overlapping highly-connected blocks that fit in GPU memory.
Propagation is then simple in-memory iterations, and we embed huge graphs on a single GPU.
6/10
Propagation is then simple in-memory iterations, and we embed huge graphs on a single GPU.
6/10
November 28, 2025 at 3:46 PM
To have a very efficient algorithm, we split the graph in overlapping highly-connected blocks that fit in GPU memory.
Propagation is then simple in-memory iterations, and we embed huge graphs on a single GPU.
6/10
Propagation is then simple in-memory iterations, and we embed huge graphs on a single GPU.
6/10
Knowledge graphs have long-tailed entity distributions, with many weakly-connected entities on which contrastive learning is under constrained.
For these, we propagate embeddings via the relation operators, in a diffusion-like step, extrapolating from the central entities.
5/10
For these, we propagate embeddings via the relation operators, in a diffusion-like step, extrapolating from the central entities.
5/10

November 28, 2025 at 3:46 PM
Knowledge graphs have long-tailed entity distributions, with many weakly-connected entities on which contrastive learning is under constrained.
For these, we propagate embeddings via the relation operators, in a diffusion-like step, extrapolating from the central entities.
5/10
For these, we propagate embeddings via the relation operators, in a diffusion-like step, extrapolating from the central entities.
5/10
Our approach uses contrastive learning on a core subset of entities, to capture a large-scale structure.
Consistent with knowledge-graph embedding literature, this step represents relations as operators on the embedding space.
It also anchors the central entities.
4/10
Consistent with knowledge-graph embedding literature, this step represents relations as operators on the embedding space.
It also anchors the central entities.
4/10

November 28, 2025 at 3:46 PM
Our approach uses contrastive learning on a core subset of entities, to capture a large-scale structure.
Consistent with knowledge-graph embedding literature, this step represents relations as operators on the embedding space.
It also anchors the central entities.
4/10
Consistent with knowledge-graph embedding literature, this step represents relations as operators on the embedding space.
It also anchors the central entities.
4/10
Our paper shows that message passing is a great tool to build feature vectors from graphs
As opposed to contrastive learning, message passing helps embeddings represent the large-scale structure of the graph (it gives Arnoldi-type iterations).
3/10
As opposed to contrastive learning, message passing helps embeddings represent the large-scale structure of the graph (it gives Arnoldi-type iterations).
3/10

November 28, 2025 at 3:46 PM
Our paper shows that message passing is a great tool to build feature vectors from graphs
As opposed to contrastive learning, message passing helps embeddings represent the large-scale structure of the graph (it gives Arnoldi-type iterations).
3/10
As opposed to contrastive learning, message passing helps embeddings represent the large-scale structure of the graph (it gives Arnoldi-type iterations).
3/10
Graphs can represent knowledge and have scaled to huge sizes (>115M entities in Wikidata).
How to distill these into good downstream features, eg for machine learning?
The challenge is to create feature vectors, and for this graph embeddings have been invaluable.
2/10
How to distill these into good downstream features, eg for machine learning?
The challenge is to create feature vectors, and for this graph embeddings have been invaluable.
2/10
November 28, 2025 at 3:46 PM
Graphs can represent knowledge and have scaled to huge sizes (>115M entities in Wikidata).
How to distill these into good downstream features, eg for machine learning?
The challenge is to create feature vectors, and for this graph embeddings have been invaluable.
2/10
How to distill these into good downstream features, eg for machine learning?
The challenge is to create feature vectors, and for this graph embeddings have been invaluable.
2/10
Next time I see him, I'll ask him
November 27, 2025 at 10:36 PM
Next time I see him, I'll ask him
Les GPUs, c'est qu'une fraction de la consommation d'un data centre
(CPU, stockage, réseau, refroidissement... tout cela est inefficace)
(CPU, stockage, réseau, refroidissement... tout cela est inefficace)
November 20, 2025 at 12:19 AM
Les GPUs, c'est qu'une fraction de la consommation d'un data centre
(CPU, stockage, réseau, refroidissement... tout cela est inefficace)
(CPU, stockage, réseau, refroidissement... tout cela est inefficace)
It's stored in the context, just like a nearest neighbours' learning is just storing the training set
November 16, 2025 at 7:13 PM
It's stored in the context, just like a nearest neighbours' learning is just storing the training set
J'écris plusieurs rapports par ans, par exemple le rapport annuel de mon équipe qui est public:
radar.inria.fr/report/2024/...
Tout ce temps passé à faire des rapports, c'est du temps que je passe pas à autre chose.
Et qui les lit?
radar.inria.fr/report/2024/...
Tout ce temps passé à faire des rapports, c'est du temps que je passe pas à autre chose.
Et qui les lit?
SODA - 2024 - Rapport annuel d'activité
radar.inria.fr
November 14, 2025 at 6:46 AM
J'écris plusieurs rapports par ans, par exemple le rapport annuel de mon équipe qui est public:
radar.inria.fr/report/2024/...
Tout ce temps passé à faire des rapports, c'est du temps que je passe pas à autre chose.
Et qui les lit?
radar.inria.fr/report/2024/...
Tout ce temps passé à faire des rapports, c'est du temps que je passe pas à autre chose.
Et qui les lit?
Je crois que le Government Accountability Office fait ça;
www.gao.gov/products/gao...
Mais c'est écrit sur les formulaires officiel du gouvernement qu'il ont été evalués
www.gao.gov/products/gao...
Mais c'est écrit sur les formulaires officiel du gouvernement qu'il ont été evalués
www.gao.gov
November 14, 2025 at 6:40 AM
Je crois que le Government Accountability Office fait ça;
www.gao.gov/products/gao...
Mais c'est écrit sur les formulaires officiel du gouvernement qu'il ont été evalués
www.gao.gov/products/gao...
Mais c'est écrit sur les formulaires officiel du gouvernement qu'il ont été evalués
Absolument !!!
Aux US ils ont (avaient ?) plus ou moins une agence qui fait ça, non?
Aux US ils ont (avaient ?) plus ou moins une agence qui fait ça, non?
November 13, 2025 at 9:50 PM
Absolument !!!
Aux US ils ont (avaient ?) plus ou moins une agence qui fait ça, non?
Aux US ils ont (avaient ?) plus ou moins une agence qui fait ça, non?
Soit, et je te garanti que je fais du gemeni pro (utilisant mon compte probabl) à fond, avec l'intégration Google drive, et un drive bien nourri de tous les documents.
Mais 1) il faut repasser derrière 2) de faire plus vite et moins bien une tâche qui sert à rien ne la rend pas utile, au contraire.
Mais 1) il faut repasser derrière 2) de faire plus vite et moins bien une tâche qui sert à rien ne la rend pas utile, au contraire.
November 13, 2025 at 9:48 PM
Soit, et je te garanti que je fais du gemeni pro (utilisant mon compte probabl) à fond, avec l'intégration Google drive, et un drive bien nourri de tous les documents.
Mais 1) il faut repasser derrière 2) de faire plus vite et moins bien une tâche qui sert à rien ne la rend pas utile, au contraire.
Mais 1) il faut repasser derrière 2) de faire plus vite et moins bien une tâche qui sert à rien ne la rend pas utile, au contraire.
I hate to say, but this is one reason why I co-authored:
dl.acm.org/doi/10.1145/...
I genuinely think that we need to collectively act to change the narrative and social norms
dl.acm.org/doi/10.1145/...
I genuinely think that we need to collectively act to change the narrative and social norms




November 13, 2025 at 7:49 PM
I hate to say, but this is one reason why I co-authored:
dl.acm.org/doi/10.1145/...
I genuinely think that we need to collectively act to change the narrative and social norms
dl.acm.org/doi/10.1145/...
I genuinely think that we need to collectively act to change the narrative and social norms
Nice, I see two of my friends interacting and I'm like: I didn't know that they knew each other!
They didn't, it seems 😀
They didn't, it seems 😀
November 13, 2025 at 7:25 PM
Nice, I see two of my friends interacting and I'm like: I didn't know that they knew each other!
They didn't, it seems 😀
They didn't, it seems 😀