



We have Nvidia B200s ready to go for you in Hugging Face Inference Endpoints 🔥
I tried them out myself and the performance is amazing.
On top of that we just got a fresh batch of H100s as well. At $4.5/hour it's a clear winner in terms of price/perf compared to the A100.
I tried them out myself and the performance is amazing.
On top of that we just got a fresh batch of H100s as well. At $4.5/hour it's a clear winner in terms of price/perf compared to the A100.

October 6, 2025 at 8:44 AM
We have Nvidia B200s ready to go for you in Hugging Face Inference Endpoints 🔥
I tried them out myself and the performance is amazing.
On top of that we just got a fresh batch of H100s as well. At $4.5/hour it's a clear winner in terms of price/perf compared to the A100.
I tried them out myself and the performance is amazing.
On top of that we just got a fresh batch of H100s as well. At $4.5/hour it's a clear winner in terms of price/perf compared to the A100.

Gemma 3 is live 🔥
You can deploy it from endpoints directly with an optimally selected hardware and configurations.
Give it a try 👇
You can deploy it from endpoints directly with an optimally selected hardware and configurations.
Give it a try 👇
March 12, 2025 at 11:28 AM
Gemma 3 is live 🔥
You can deploy it from endpoints directly with an optimally selected hardware and configurations.
Give it a try 👇
You can deploy it from endpoints directly with an optimally selected hardware and configurations.
Give it a try 👇
Apparently, mom is a better engineer than what I am.

December 24, 2024 at 1:03 PM
Apparently, mom is a better engineer than what I am.
today as part of a course, I implemented a program that takes a bit stream like so:
10001001110111101000100111111011
and decodes the intel 8088 assembly from it like:
mov si, bx
mov bx, di
only works on the mov instruction, register to register.
code: github.com/ErikKaum/bit...
10001001110111101000100111111011
and decodes the intel 8088 assembly from it like:
mov si, bx
mov bx, di
only works on the mov instruction, register to register.
code: github.com/ErikKaum/bit...
https://github.com/ErikKaum/bitbubble
t.co
December 21, 2024 at 9:17 PM
today as part of a course, I implemented a program that takes a bit stream like so:
10001001110111101000100111111011
and decodes the intel 8088 assembly from it like:
mov si, bx
mov bx, di
only works on the mov instruction, register to register.
code: github.com/ErikKaum/bit...
10001001110111101000100111111011
and decodes the intel 8088 assembly from it like:
mov si, bx
mov bx, di
only works on the mov instruction, register to register.
code: github.com/ErikKaum/bit...
Ambition is a paradox.
You should always aim higher, but that easily becomes a state where you're never satisfied. Just reached 10k MRR. Now there's the next goal of 20k.
Sharif has a good talk on this: emotional runway.
How do you deal with this paradox?
video: www.youtube.com/watch?v=zUnQ...
You should always aim higher, but that easily becomes a state where you're never satisfied. Just reached 10k MRR. Now there's the next goal of 20k.
Sharif has a good talk on this: emotional runway.
How do you deal with this paradox?
video: www.youtube.com/watch?v=zUnQ...

before you give up, give this video a chance.
YouTube video by Founders, Inc.
www.youtube.com
December 17, 2024 at 10:12 AM
Ambition is a paradox.
You should always aim higher, but that easily becomes a state where you're never satisfied. Just reached 10k MRR. Now there's the next goal of 20k.
Sharif has a good talk on this: emotional runway.
How do you deal with this paradox?
video: www.youtube.com/watch?v=zUnQ...
You should always aim higher, but that easily becomes a state where you're never satisfied. Just reached 10k MRR. Now there's the next goal of 20k.
Sharif has a good talk on this: emotional runway.
How do you deal with this paradox?
video: www.youtube.com/watch?v=zUnQ...
Qui Gon Jinn sharing some insightful prompting wisdom 👌🏼

December 8, 2024 at 9:04 AM
Qui Gon Jinn sharing some insightful prompting wisdom 👌🏼
it's this time of the year 😍
December 1, 2024 at 10:12 AM
it's this time of the year 😍
Reposted by Erik

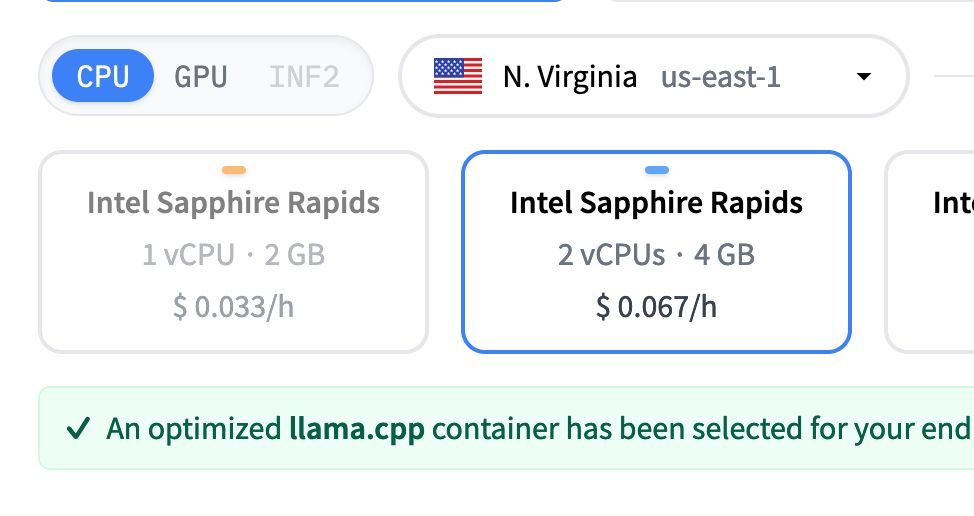
Hugging Face inference endpoints now support CPU deployment for llama.cpp 🚀 🚀
Why this is a huge deal? Llama.cpp is well-known for running very well on CPU. If you're running small models like Llama 1B or embedding models, this will definitely save tons of money 💰 💰
Why this is a huge deal? Llama.cpp is well-known for running very well on CPU. If you're running small models like Llama 1B or embedding models, this will definitely save tons of money 💰 💰
November 27, 2024 at 11:01 AM
Hugging Face inference endpoints now support CPU deployment for llama.cpp 🚀 🚀
Why this is a huge deal? Llama.cpp is well-known for running very well on CPU. If you're running small models like Llama 1B or embedding models, this will definitely save tons of money 💰 💰
Why this is a huge deal? Llama.cpp is well-known for running very well on CPU. If you're running small models like Llama 1B or embedding models, this will definitely save tons of money 💰 💰
Reposted by Erik

Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!

November 26, 2024 at 3:57 PM
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
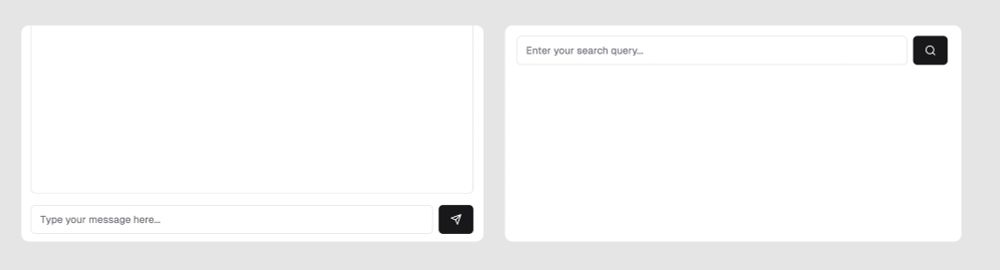
Is it just me or does it intuitively align that chat bars are at the bottom of the page and search bars at the top?
I've noticed that perplexity positions the question on the top and generates the text below.
Is it because they want to position more as a search engine?
I've noticed that perplexity positions the question on the top and generates the text below.
Is it because they want to position more as a search engine?
November 26, 2024 at 1:54 PM
Is it just me or does it intuitively align that chat bars are at the bottom of the page and search bars at the top?
I've noticed that perplexity positions the question on the top and generates the text below.
Is it because they want to position more as a search engine?
I've noticed that perplexity positions the question on the top and generates the text below.
Is it because they want to position more as a search engine?
code boxes with syntax highlighting 😍

Are there plans to add syntax highlighting to code blocks and inline code to Bluesky? It is one of the top features devs appreciated in Elk. Being able to share a11y code snippets instead of images makes a huge diff. I think it could help a lot to promote tinkering with the protocol among devs
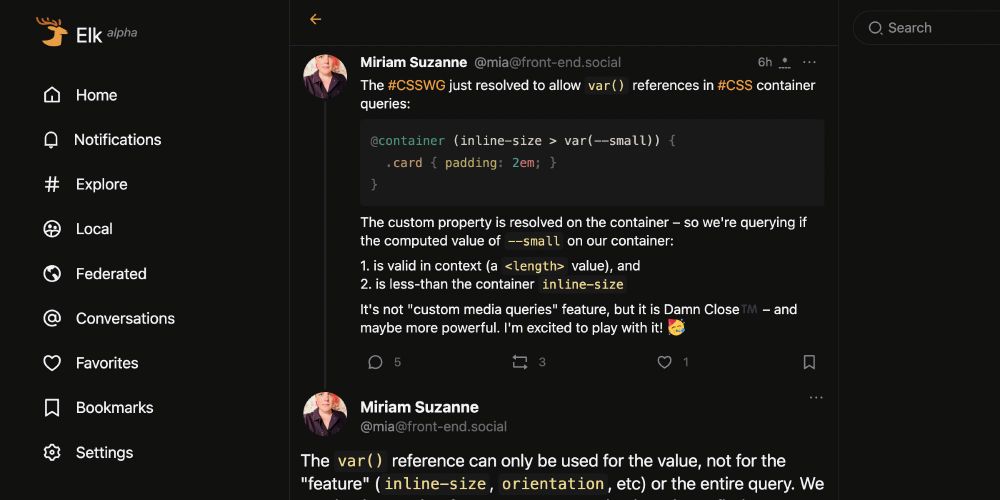
November 24, 2024 at 10:19 AM
code boxes with syntax highlighting 😍
typical engineer writing copy
in plain english i'd say "2 conversions at the same time"
in plain english i'd say "2 conversions at the same time"

November 23, 2024 at 5:38 PM
typical engineer writing copy
in plain english i'd say "2 conversions at the same time"
in plain english i'd say "2 conversions at the same time"
lesson: if you care about the performance of something, you gotta run your own benchmarks

A new paper, "Let Me Speak Freely" has been spreading rumors that structured generation hurts LLM evaluation performance.
Well, we've taken a look and found serious issue in this paper, and shown, once again, that structured generation *improves* evaluation performance!
Well, we've taken a look and found serious issue in this paper, and shown, once again, that structured generation *improves* evaluation performance!
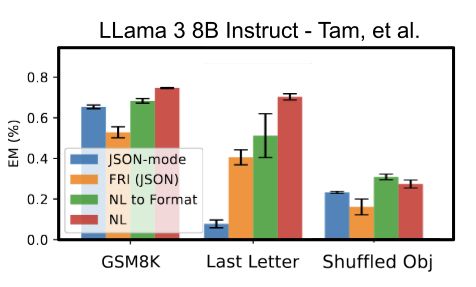
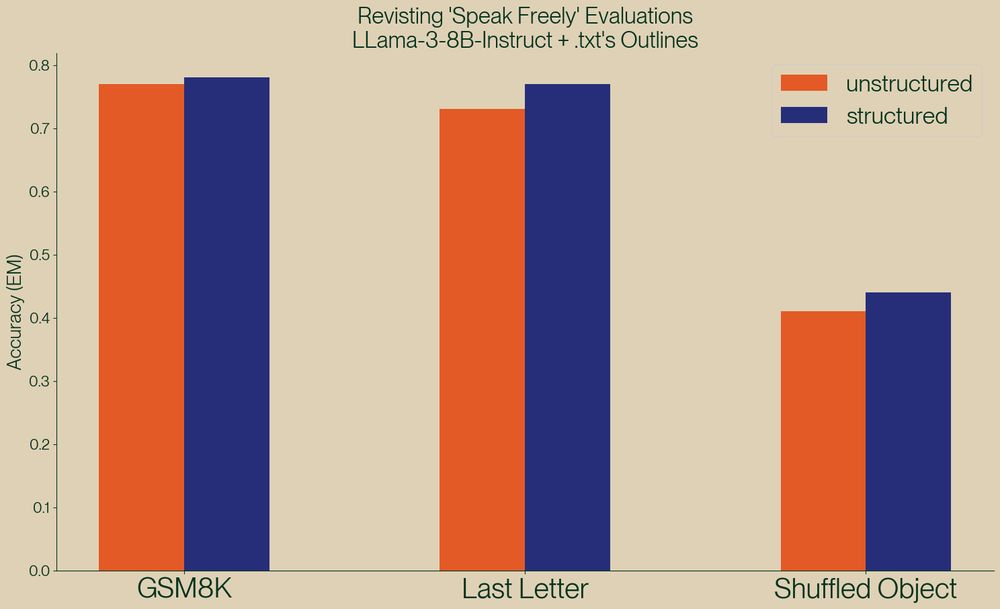
November 22, 2024 at 8:07 AM
lesson: if you care about the performance of something, you gotta run your own benchmarks
Just wrote some golang for fun.
Damn, I had almost forgotten how enjoyable it’s to program in.
Just breezing through the code. If I need thousands of threads, it’s just there.
Damn, I had almost forgotten how enjoyable it’s to program in.
Just breezing through the code. If I need thousands of threads, it’s just there.
November 19, 2024 at 9:23 PM
Just wrote some golang for fun.
Damn, I had almost forgotten how enjoyable it’s to program in.
Just breezing through the code. If I need thousands of threads, it’s just there.
Damn, I had almost forgotten how enjoyable it’s to program in.
Just breezing through the code. If I need thousands of threads, it’s just there.
A while ago I started experimenting with compiling the Python interpreter to WASM.
To build a secure, fast, and lightweight sandbox for code execution — ideal for running LLM-generated Python code.
- Send code simply as a POST request
- 1-2ms startup times
github.com/ErikKaum/run...
To build a secure, fast, and lightweight sandbox for code execution — ideal for running LLM-generated Python code.
- Send code simply as a POST request
- 1-2ms startup times
github.com/ErikKaum/run...

GitHub - ErikKaum/runner: Experimental wasm32-unknown-wasi runtime for Python code execution
Experimental wasm32-unknown-wasi runtime for Python code execution - ErikKaum/runner
github.com
November 18, 2024 at 9:21 AM
A while ago I started experimenting with compiling the Python interpreter to WASM.
To build a secure, fast, and lightweight sandbox for code execution — ideal for running LLM-generated Python code.
- Send code simply as a POST request
- 1-2ms startup times
github.com/ErikKaum/run...
To build a secure, fast, and lightweight sandbox for code execution — ideal for running LLM-generated Python code.
- Send code simply as a POST request
- 1-2ms startup times
github.com/ErikKaum/run...
There are now /llms.txt files for a few of @huggingface.bsky.social docs 🔥
huggingface-projects-docs-llms-txt.hf.space/transformers...
huggingface-projects-docs-llms-txt.hf.space/transformers...
huggingface-projects-docs-llms-txt.hf.space
November 16, 2024 at 10:16 AM
There are now /llms.txt files for a few of @huggingface.bsky.social docs 🔥
huggingface-projects-docs-llms-txt.hf.space/transformers...
huggingface-projects-docs-llms-txt.hf.space/transformers...
@huggingface.bsky.social off-site 🤙🏼

November 8, 2024 at 10:42 AM
@huggingface.bsky.social off-site 🤙🏼
"If you're thinking without writing, you only think you're thinking."
Same applies imo to coding and why it's so important to open your editor, start tinkering and sketching things out.
quote from: paulgraham.com/writes.html
Same applies imo to coding and why it's so important to open your editor, start tinkering and sketching things out.
quote from: paulgraham.com/writes.html
Writes and Write-Nots
paulgraham.com
November 1, 2024 at 12:51 PM
"If you're thinking without writing, you only think you're thinking."
Same applies imo to coding and why it's so important to open your editor, start tinkering and sketching things out.
quote from: paulgraham.com/writes.html
Same applies imo to coding and why it's so important to open your editor, start tinkering and sketching things out.
quote from: paulgraham.com/writes.html