




elvis
@eos.bsky.social
Building with AI agents • Prev: Meta AI, Elastic, Galactica LLM, PhD • Prompting Guide (~6M+ learners) • I also teach how to build with AI: https://dair-ai.thinkific.com/
Hallucinations are generally bad for real-world LLM applications.
Folks like Karpathy have suggested that hallucination is an LLM's greatest feature.
Is there any evidence for the latter?
Folks like Karpathy have suggested that hallucination is an LLM's greatest feature.
Is there any evidence for the latter?

January 24, 2025 at 1:56 PM
Hallucinations are generally bad for real-world LLM applications.
Folks like Karpathy have suggested that hallucination is an LLM's greatest feature.
Is there any evidence for the latter?
Folks like Karpathy have suggested that hallucination is an LLM's greatest feature.
Is there any evidence for the latter?
Google recently published this great whitepaper on Agents.
2025 is a huge year for AI Agents.
Here's what's included:
- Introduction to AI Agents
- The role of tools in Agents
- Enhancing model performance
- Quick start to Agents with LangChain
- Production applications with Vertex AI Agents
2025 is a huge year for AI Agents.
Here's what's included:
- Introduction to AI Agents
- The role of tools in Agents
- Enhancing model performance
- Quick start to Agents with LangChain
- Production applications with Vertex AI Agents

January 6, 2025 at 7:35 PM
Google recently published this great whitepaper on Agents.
2025 is a huge year for AI Agents.
Here's what's included:
- Introduction to AI Agents
- The role of tools in Agents
- Enhancing model performance
- Quick start to Agents with LangChain
- Production applications with Vertex AI Agents
2025 is a huge year for AI Agents.
Here's what's included:
- Introduction to AI Agents
- The role of tools in Agents
- Enhancing model performance
- Quick start to Agents with LangChain
- Production applications with Vertex AI Agents
Dive into Time-Series Anomaly Detection: A Decade Review
Provides a survey of time-series anomaly detection solutions.
Provides a survey of time-series anomaly detection solutions.

January 6, 2025 at 2:18 PM
Dive into Time-Series Anomaly Detection: A Decade Review
Provides a survey of time-series anomaly detection solutions.
Provides a survey of time-series anomaly detection solutions.
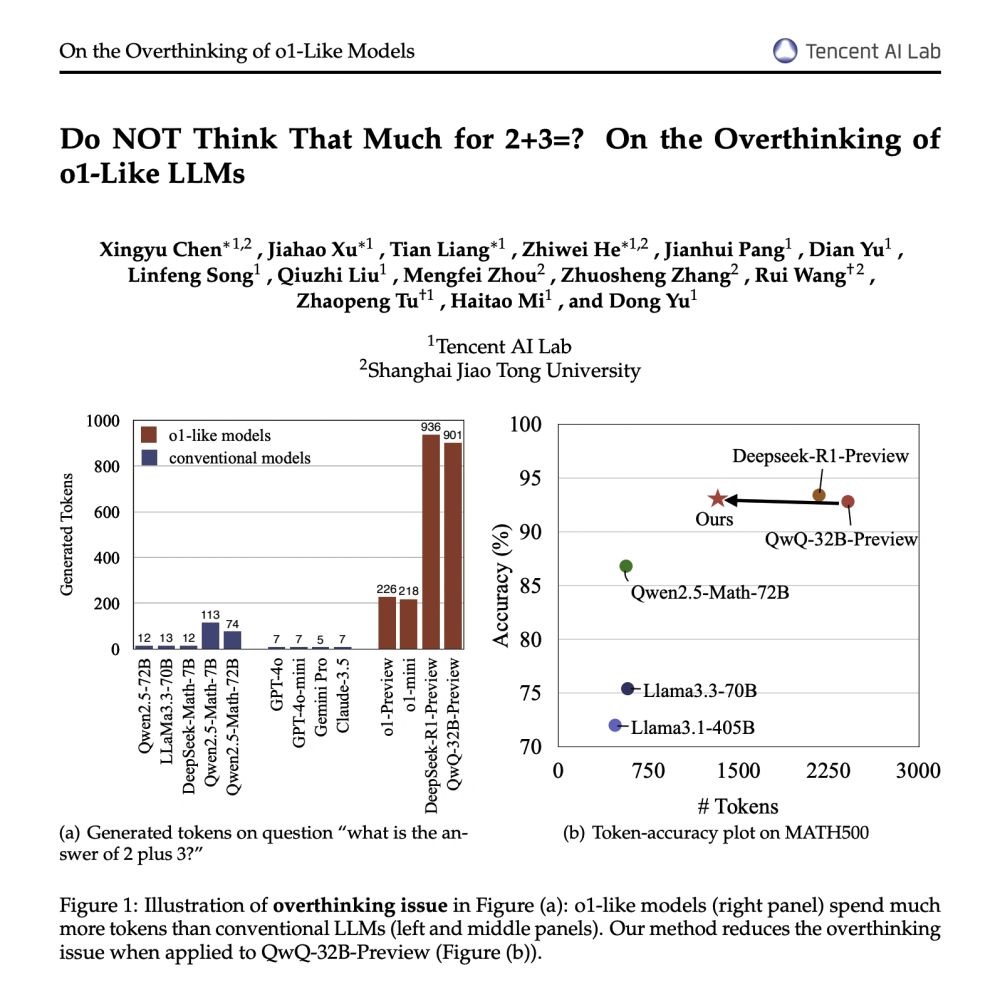
Proposes a self-training strategy to mitigate overthinking in o1-like LLMs.
This approach can reduce token output by 48.6% while maintaining accuracy on the widely-used MATH500 test set as applied to QwQ-32B-Preview.
There are three parts to this study:
- analysis of the overthinking issue
This approach can reduce token output by 48.6% while maintaining accuracy on the widely-used MATH500 test set as applied to QwQ-32B-Preview.
There are three parts to this study:
- analysis of the overthinking issue
January 2, 2025 at 4:03 PM
Proposes a self-training strategy to mitigate overthinking in o1-like LLMs.
This approach can reduce token output by 48.6% while maintaining accuracy on the widely-used MATH500 test set as applied to QwQ-32B-Preview.
There are three parts to this study:
- analysis of the overthinking issue
This approach can reduce token output by 48.6% while maintaining accuracy on the widely-used MATH500 test set as applied to QwQ-32B-Preview.
There are three parts to this study:
- analysis of the overthinking issue
Just came across this interesting project.
RWKV combines the best of RNN and transformers.
There is code for training your own model, fine-tuning, GUI, API, fast WebGPU inference, and more.
Cool project!
RWKV combines the best of RNN and transformers.
There is code for training your own model, fine-tuning, GUI, API, fast WebGPU inference, and more.
Cool project!

January 2, 2025 at 3:15 PM
Just came across this interesting project.
RWKV combines the best of RNN and transformers.
There is code for training your own model, fine-tuning, GUI, API, fast WebGPU inference, and more.
Cool project!
RWKV combines the best of RNN and transformers.
There is code for training your own model, fine-tuning, GUI, API, fast WebGPU inference, and more.
Cool project!
Agentarium is a new Python framework for managing and orchestrating AI agents.
Features include (from the repo):
• 🤖 Advanced Agent Management: Create and orchestrate multiple AI agents with different roles and capabilities
Features include (from the repo):
• 🤖 Advanced Agent Management: Create and orchestrate multiple AI agents with different roles and capabilities

December 31, 2024 at 3:22 PM
Agentarium is a new Python framework for managing and orchestrating AI agents.
Features include (from the repo):
• 🤖 Advanced Agent Management: Create and orchestrate multiple AI agents with different roles and capabilities
Features include (from the repo):
• 🤖 Advanced Agent Management: Create and orchestrate multiple AI agents with different roles and capabilities

December 20, 2024 at 3:18 PM

This is worth looking at.

December 16, 2024 at 3:10 PM
This is worth looking at.
Very exciting guide on working with LLMs.
A few chapters have been made available already like structured output and evals. More to come soon!
A few chapters have been made available already like structured output and evals. More to come soon!

December 13, 2024 at 3:20 PM
Very exciting guide on working with LLMs.
A few chapters have been made available already like structured output and evals. More to come soon!
A few chapters have been made available already like structured output and evals. More to come soon!
IBM open-sources Granite Guardian, a suite of safeguards for risk detection in LLMs.

December 11, 2024 at 2:28 PM
IBM open-sources Granite Guardian, a suite of safeguards for risk detection in LLMs.
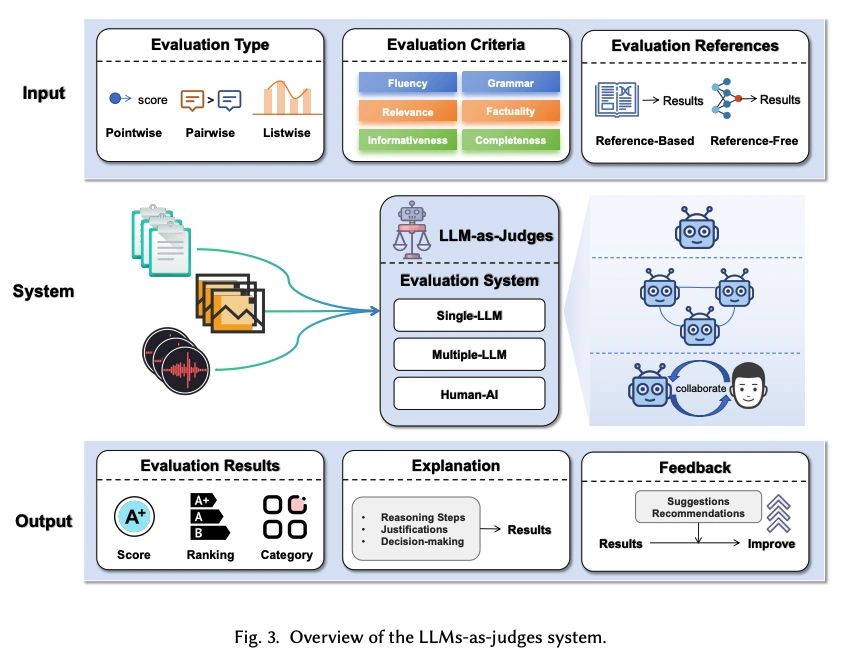
A Survey on LLMs-as-Judges
Presents a comprehensive survey of the LLMs-as-judges paradigm from five key perspectives: Functionality, Methodology, Applications, Meta-evaluation, and Limitations.
Presents a comprehensive survey of the LLMs-as-judges paradigm from five key perspectives: Functionality, Methodology, Applications, Meta-evaluation, and Limitations.
December 10, 2024 at 5:52 PM
A Survey on LLMs-as-Judges
Presents a comprehensive survey of the LLMs-as-judges paradigm from five key perspectives: Functionality, Methodology, Applications, Meta-evaluation, and Limitations.
Presents a comprehensive survey of the LLMs-as-judges paradigm from five key perspectives: Functionality, Methodology, Applications, Meta-evaluation, and Limitations.
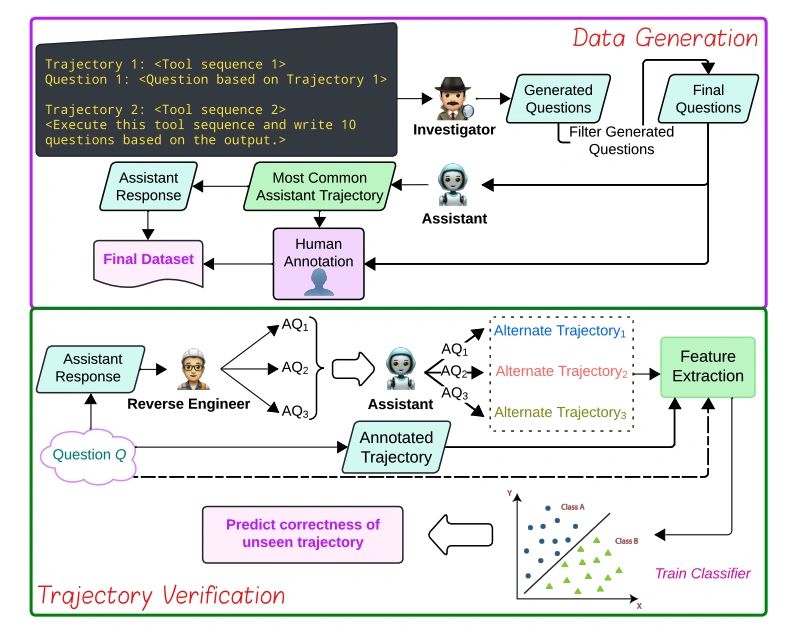
A Multi-Agent Framework for Synthetic Data Generation
Presents MAG-V, a multi-agent framework that first generates a dataset of questions that mimic customer queries. It then reverse engineer alternate questions from responses to verify agent trajectories.
arxiv.org/abs/2412.04494
Presents MAG-V, a multi-agent framework that first generates a dataset of questions that mimic customer queries. It then reverse engineer alternate questions from responses to verify agent trajectories.
arxiv.org/abs/2412.04494
December 10, 2024 at 4:02 PM
A Multi-Agent Framework for Synthetic Data Generation
Presents MAG-V, a multi-agent framework that first generates a dataset of questions that mimic customer queries. It then reverse engineer alternate questions from responses to verify agent trajectories.
arxiv.org/abs/2412.04494
Presents MAG-V, a multi-agent framework that first generates a dataset of questions that mimic customer queries. It then reverse engineer alternate questions from responses to verify agent trajectories.
arxiv.org/abs/2412.04494
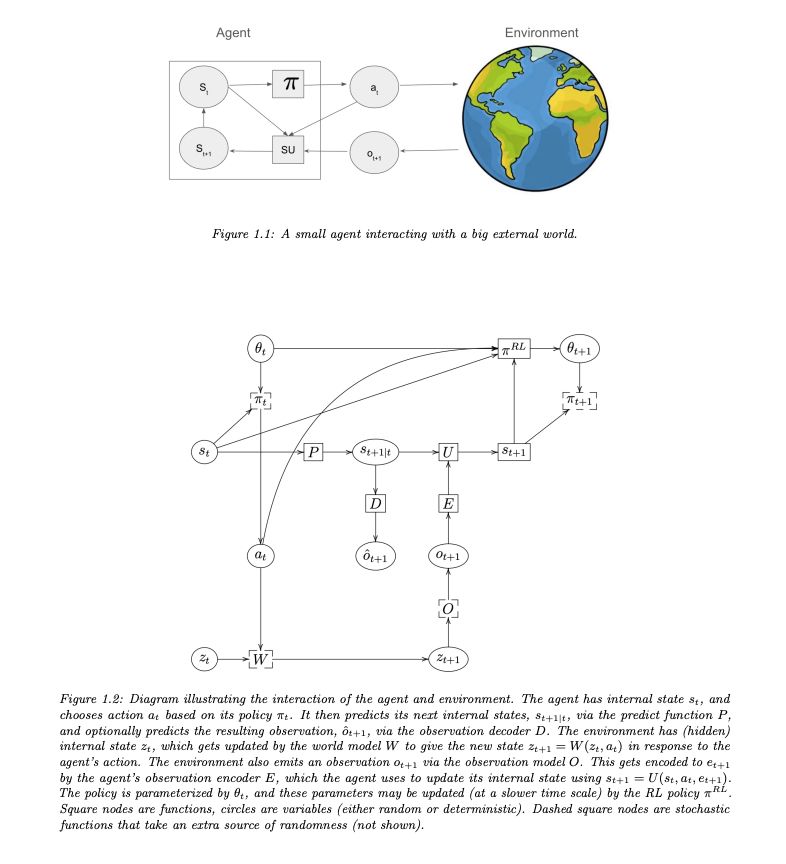
Reinforcement Learning: An Overview
This gem just dropped on arXiv.
An up-to-date overview of reinforcement learning and sequential decision-making.
arxiv.org/abs/2412.05265
This gem just dropped on arXiv.
An up-to-date overview of reinforcement learning and sequential decision-making.
arxiv.org/abs/2412.05265
December 9, 2024 at 3:38 PM
Reinforcement Learning: An Overview
This gem just dropped on arXiv.
An up-to-date overview of reinforcement learning and sequential decision-making.
arxiv.org/abs/2412.05265
This gem just dropped on arXiv.
An up-to-date overview of reinforcement learning and sequential decision-making.
arxiv.org/abs/2412.05265
RARE: Retrieval-Augmented Reasoning for LLMs
Extends the rStar reasoning framework to enhance reasoning accuracy and factual reliability of LLMs.
Extends the rStar reasoning framework to enhance reasoning accuracy and factual reliability of LLMs.

December 5, 2024 at 3:04 PM
RARE: Retrieval-Augmented Reasoning for LLMs
Extends the rStar reasoning framework to enhance reasoning accuracy and factual reliability of LLMs.
Extends the rStar reasoning framework to enhance reasoning accuracy and factual reliability of LLMs.

December 5, 2024 at 2:44 PM
DataLab: A Unified Platform for LLM-Powered Business Intelligence
Introduces DataLab, a unified BI platform that integrates an LLM-based agent framework with an augmented computational notebook interface.
Introduces DataLab, a unified BI platform that integrates an LLM-based agent framework with an augmented computational notebook interface.

December 4, 2024 at 3:14 PM
DataLab: A Unified Platform for LLM-Powered Business Intelligence
Introduces DataLab, a unified BI platform that integrates an LLM-based agent framework with an augmented computational notebook interface.
Introduces DataLab, a unified BI platform that integrates an LLM-based agent framework with an augmented computational notebook interface.
LLM-brained GUI Agents
Great survey on LLM-brained GUI agents, including techniques and applications.
https://arxiv.org/abs/2411.18279
Great survey on LLM-brained GUI agents, including techniques and applications.
https://arxiv.org/abs/2411.18279

November 28, 2024 at 1:57 PM
LLM-brained GUI Agents
Great survey on LLM-brained GUI agents, including techniques and applications.
https://arxiv.org/abs/2411.18279
Great survey on LLM-brained GUI agents, including techniques and applications.
https://arxiv.org/abs/2411.18279
This new paper extends in-context learning through high-level automated reasoning.
It achieves state-of-the-art accuracy (79.6%) on the MATH benchmark with Qwen2.5-7B-Instruct, surpassing GPT-4o (76.6%) and Claude 3.5 (71.1%).
It achieves state-of-the-art accuracy (79.6%) on the MATH benchmark with Qwen2.5-7B-Instruct, surpassing GPT-4o (76.6%) and Claude 3.5 (71.1%).

November 28, 2024 at 1:48 PM
This new paper extends in-context learning through high-level automated reasoning.
It achieves state-of-the-art accuracy (79.6%) on the MATH benchmark with Qwen2.5-7B-Instruct, surpassing GPT-4o (76.6%) and Claude 3.5 (71.1%).
It achieves state-of-the-art accuracy (79.6%) on the MATH benchmark with Qwen2.5-7B-Instruct, surpassing GPT-4o (76.6%) and Claude 3.5 (71.1%).
LLMs surpass human experts in predicting neuroscience results
Scientific discovery is the next big goal for AI. We are seeing a huge number of research studies tackling AI-powered scientific discovery from different angles and for different problems.
Scientific discovery is the next big goal for AI. We are seeing a huge number of research studies tackling AI-powered scientific discovery from different angles and for different problems.

November 27, 2024 at 2:36 PM
LLMs surpass human experts in predicting neuroscience results
Scientific discovery is the next big goal for AI. We are seeing a huge number of research studies tackling AI-powered scientific discovery from different angles and for different problems.
Scientific discovery is the next big goal for AI. We are seeing a huge number of research studies tackling AI-powered scientific discovery from different angles and for different problems.
o1 Replication Journey - Part 2
Shows that combining simple distillation from O1's API with supervised fine-tuning significantly boosts performance on complex math reasoning tasks.
Shows that combining simple distillation from O1's API with supervised fine-tuning significantly boosts performance on complex math reasoning tasks.

November 26, 2024 at 2:09 PM
o1 Replication Journey - Part 2
Shows that combining simple distillation from O1's API with supervised fine-tuning significantly boosts performance on complex math reasoning tasks.
Shows that combining simple distillation from O1's API with supervised fine-tuning significantly boosts performance on complex math reasoning tasks.
Pushing Frontiers in Open Language Model Post-Training
This is probably one of the important open-source efforts in post-training of LLMs.
This is probably one of the important open-source efforts in post-training of LLMs.

November 25, 2024 at 4:31 PM
Pushing Frontiers in Open Language Model Post-Training
This is probably one of the important open-source efforts in post-training of LLMs.
This is probably one of the important open-source efforts in post-training of LLMs.
Measuring Bullshit in the Language Games played by ChatGPT
Proposes that LLM-based chatbots play the ‘language game of bullshit’
Proposes that LLM-based chatbots play the ‘language game of bullshit’

November 25, 2024 at 3:16 PM
Measuring Bullshit in the Language Games played by ChatGPT
Proposes that LLM-based chatbots play the ‘language game of bullshit’
Proposes that LLM-based chatbots play the ‘language game of bullshit’
Cheaper and larger context-length text embedding models.
Voyage AI releases voyage-3 and voyage-3-lite embedding models.
Voyage AI releases voyage-3 and voyage-3-lite embedding models.

November 24, 2024 at 6:05 PM
Cheaper and larger context-length text embedding models.
Voyage AI releases voyage-3 and voyage-3-lite embedding models.
Voyage AI releases voyage-3 and voyage-3-lite embedding models.
Reasoning over Structured Data with LLMs
Proposes StructGPT to improve the zero-shot reasoning ability of LLMs over structured data. Effective for solving question answering tasks based on structured data.
paper: arxiv.org/abs/2305.09645
Proposes StructGPT to improve the zero-shot reasoning ability of LLMs over structured data. Effective for solving question answering tasks based on structured data.
paper: arxiv.org/abs/2305.09645

May 17, 2023 at 1:25 AM
Reasoning over Structured Data with LLMs
Proposes StructGPT to improve the zero-shot reasoning ability of LLMs over structured data. Effective for solving question answering tasks based on structured data.
paper: arxiv.org/abs/2305.09645
Proposes StructGPT to improve the zero-shot reasoning ability of LLMs over structured data. Effective for solving question answering tasks based on structured data.
paper: arxiv.org/abs/2305.09645