



Xan Gregg
@xangregg.bsky.social
1.7K followers
1.8K following
240 posts
Engineering Fellow at JMP, focused on #DataViz, preferring smoothers over fitted lines. Creator of JMP #GraphBuilder and #PackedBars chart type for high-cardinality Pareto data. #TieDye #LessIsMore
Posts
Media
Videos
Starter Packs











Xan Gregg
@xangregg.bsky.social
· Aug 20

![Screenshot from a Python notebook shared with the paper. Code part reads:
with plt.rc_context({'figure.autolayout': True}):
fig, ax = plt.subplots(figsize=(4, 2));
pre_x = range(-35, -5);
y = np.random.normal(loc=from_df.loc[from_df['from_loc'] == 'Seattle, WA', 'pre_avg'], scale=50., size=(len(pre_x), ));
plt.plot(pre_x, y, lw=5., c='#aa3939');
plt.ylim(5800, 7000);
ax.grid(False);
for item in ([ax.xaxis.label, ax.yaxis.label] + ax.get_xticklabels() + ax.get_yticklabels()):
item.set_fontsize(axis_fontsize);
ax.set(xlabel=r'Days from Move $\left(t - t_{move}\right)$', ylabel='Daily Steps', xticks=range(-35, -4, 10));
fig.tight_layout()
plt.savefig('../output/fig1b_subplots/seattle_from.png',
dpi=600);](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:vum7yuqczgryxehx6ozitxjg/bafkreifl6rfkiphf3g3ryzskgo4vg6vj2pw7wcwhh4e3jr6rxf52434bqy@jpeg)
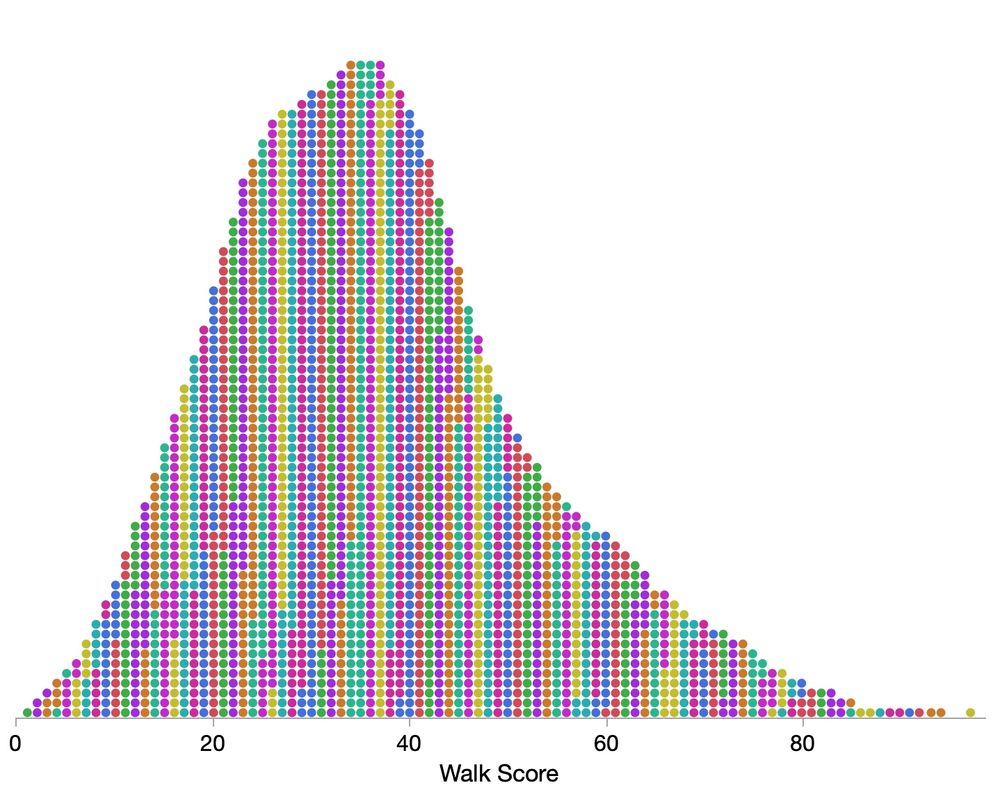
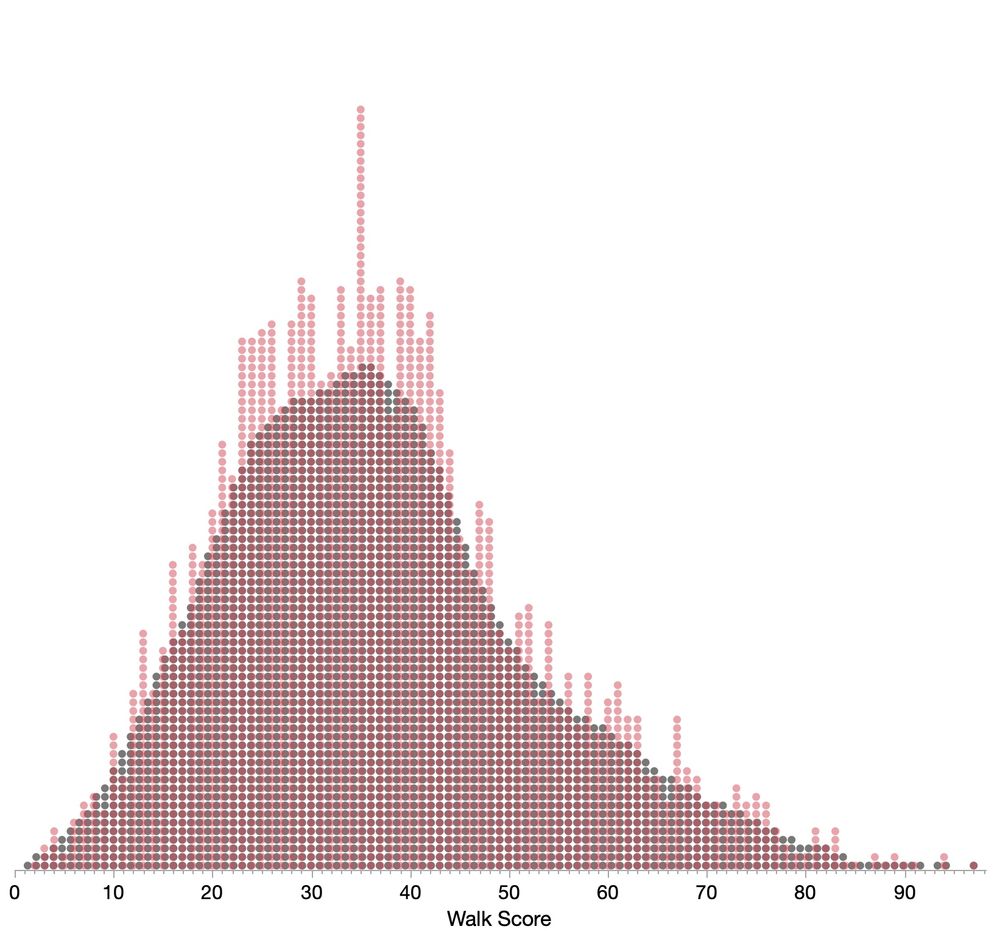




Xan Gregg
@xangregg.bsky.social
· Aug 10
Xan Gregg
@xangregg.bsky.social
· Aug 10
Xan Gregg
@xangregg.bsky.social
· Aug 10

Xan Gregg
@xangregg.bsky.social
· Jul 23




Xan Gregg
@xangregg.bsky.social
· Jun 30

Xan Gregg
@xangregg.bsky.social
· Jun 30

