




Thomas Wimmer
@wimmerthomas.bsky.social
PhD Candidate at the Max Planck ETH Center for Learning Systems working on 3D Computer Vision.
https://wimmerth.github.io
https://wimmerth.github.io
Reposted by Thomas Wimmer

DUSt3R et al. are impressive, but how do they actually work? We investigate this in our project 𝘜𝘯𝘥𝘦𝘳𝘴𝘵𝘢𝘯𝘥𝘪𝘯𝘨 𝘔𝘶𝘭𝘵𝘪-𝘝𝘪𝘦𝘸 𝘛𝘳𝘢𝘯𝘴𝘧𝘰𝘳𝘮𝘦𝘳𝘴!
We share findings on the iterative nature of reconstruction, the roles of cross and self-attention, and the emergence of correspondences across the network [1/8] ⬇️
We share findings on the iterative nature of reconstruction, the roles of cross and self-attention, and the emergence of correspondences across the network [1/8] ⬇️

𝗨𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱𝗶𝗻𝗴 𝗠𝘂𝗹𝘁𝗶-𝗩𝗶𝗲𝘄 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀
Michal Stary, Julien Gaubil, Ayush Tewari, Vincent Sitzmann
arxiv.org/abs/2510.24907
Trending on www.scholar-inbox.com
Michal Stary, Julien Gaubil, Ayush Tewari, Vincent Sitzmann
arxiv.org/abs/2510.24907
Trending on www.scholar-inbox.com




November 4, 2025 at 7:40 PM
DUSt3R et al. are impressive, but how do they actually work? We investigate this in our project 𝘜𝘯𝘥𝘦𝘳𝘴𝘵𝘢𝘯𝘥𝘪𝘯𝘨 𝘔𝘶𝘭𝘵𝘪-𝘝𝘪𝘦𝘸 𝘛𝘳𝘢𝘯𝘴𝘧𝘰𝘳𝘮𝘦𝘳𝘴!
We share findings on the iterative nature of reconstruction, the roles of cross and self-attention, and the emergence of correspondences across the network [1/8] ⬇️
We share findings on the iterative nature of reconstruction, the roles of cross and self-attention, and the emergence of correspondences across the network [1/8] ⬇️
Reposted by Thomas Wimmer

ICCV 2025 🌺 Aloha from Hawaii! MPI-INF (D2) is presenting 4 papers this year (one Highlight). Thread 👇

October 19, 2025 at 7:49 AM
ICCV 2025 🌺 Aloha from Hawaii! MPI-INF (D2) is presenting 4 papers this year (one Highlight). Thread 👇
I am on my way to #ICCV2025 to present DIY-SC, where we refine foundational features for better semantic correspondence performance. Please come by our poster poster #538 (Session 2) if you're interested or want to chat about my latest project, AnyUp!
Super excited to introduce
✨ AnyUp: Universal Feature Upsampling 🔎
Upsample any feature - really any feature - with the same upsampler, no need for cumbersome retraining.
SOTA feature upsampling results while being feature-agnostic at inference time.
🌐 wimmerth.github.io/anyup/
✨ AnyUp: Universal Feature Upsampling 🔎
Upsample any feature - really any feature - with the same upsampler, no need for cumbersome retraining.
SOTA feature upsampling results while being feature-agnostic at inference time.
🌐 wimmerth.github.io/anyup/
October 18, 2025 at 4:10 AM
I am on my way to #ICCV2025 to present DIY-SC, where we refine foundational features for better semantic correspondence performance. Please come by our poster poster #538 (Session 2) if you're interested or want to chat about my latest project, AnyUp!
Reposted by Thomas Wimmer

🤔 What if you could generate an entire image using just one continuous token?
💡 It works if we leverage a self-supervised representation!
Meet RepTok🦎: A generative model that encodes an image into a single continuous latent while keeping realism and semantics. 🧵 👇
💡 It works if we leverage a self-supervised representation!
Meet RepTok🦎: A generative model that encodes an image into a single continuous latent while keeping realism and semantics. 🧵 👇

October 17, 2025 at 10:21 AM
🤔 What if you could generate an entire image using just one continuous token?
💡 It works if we leverage a self-supervised representation!
Meet RepTok🦎: A generative model that encodes an image into a single continuous latent while keeping realism and semantics. 🧵 👇
💡 It works if we leverage a self-supervised representation!
Meet RepTok🦎: A generative model that encodes an image into a single continuous latent while keeping realism and semantics. 🧵 👇
Super excited to introduce
✨ AnyUp: Universal Feature Upsampling 🔎
Upsample any feature - really any feature - with the same upsampler, no need for cumbersome retraining.
SOTA feature upsampling results while being feature-agnostic at inference time.
🌐 wimmerth.github.io/anyup/
✨ AnyUp: Universal Feature Upsampling 🔎
Upsample any feature - really any feature - with the same upsampler, no need for cumbersome retraining.
SOTA feature upsampling results while being feature-agnostic at inference time.
🌐 wimmerth.github.io/anyup/
October 16, 2025 at 9:07 AM
Super excited to introduce
✨ AnyUp: Universal Feature Upsampling 🔎
Upsample any feature - really any feature - with the same upsampler, no need for cumbersome retraining.
SOTA feature upsampling results while being feature-agnostic at inference time.
🌐 wimmerth.github.io/anyup/
✨ AnyUp: Universal Feature Upsampling 🔎
Upsample any feature - really any feature - with the same upsampler, no need for cumbersome retraining.
SOTA feature upsampling results while being feature-agnostic at inference time.
🌐 wimmerth.github.io/anyup/
Reposted by Thomas Wimmer

Suppose you have separate datasets X, Y, Z, without known correspondences.
We do the simplest thing: just train a model (e.g., a next-token predictor) on all elements of the concatenated dataset [X,Y,Z].
You end up with a better model of dataset X than if you had trained on X alone!
6/9
We do the simplest thing: just train a model (e.g., a next-token predictor) on all elements of the concatenated dataset [X,Y,Z].
You end up with a better model of dataset X than if you had trained on X alone!
6/9

October 10, 2025 at 10:13 PM
Suppose you have separate datasets X, Y, Z, without known correspondences.
We do the simplest thing: just train a model (e.g., a next-token predictor) on all elements of the concatenated dataset [X,Y,Z].
You end up with a better model of dataset X than if you had trained on X alone!
6/9
We do the simplest thing: just train a model (e.g., a next-token predictor) on all elements of the concatenated dataset [X,Y,Z].
You end up with a better model of dataset X than if you had trained on X alone!
6/9
Happy to find my name on the list of outstanding reviewers :]
Come and check out our poster on learning better features for semantic correspondence in Hawaii!
📍 Poster #538 (Session 2)
🗓️ Oct 21 | 3:15 – 5:00 p.m. HST
genintel.github.io/DIY-SC
Come and check out our poster on learning better features for semantic correspondence in Hawaii!
📍 Poster #538 (Session 2)
🗓️ Oct 21 | 3:15 – 5:00 p.m. HST
genintel.github.io/DIY-SC

There’s no conference without the efforts of our reviewers. Special shoutout to our #ICCV2025 outstanding reviewers 🫡
iccv.thecvf.com/Conferences/...
iccv.thecvf.com/Conferences/...
2025 ICCV Program Committee
iccv.thecvf.com
October 7, 2025 at 3:05 PM
Happy to find my name on the list of outstanding reviewers :]
Come and check out our poster on learning better features for semantic correspondence in Hawaii!
📍 Poster #538 (Session 2)
🗓️ Oct 21 | 3:15 – 5:00 p.m. HST
genintel.github.io/DIY-SC
Come and check out our poster on learning better features for semantic correspondence in Hawaii!
📍 Poster #538 (Session 2)
🗓️ Oct 21 | 3:15 – 5:00 p.m. HST
genintel.github.io/DIY-SC
🚀 Just accepted to ICCV 2025!
In DIY-SC, we improve foundational features using a light-weight adapter trained with carefully filtered and refined pseudo-labels.
🔧 Drop-in alternative to plain DINOv2 features!
📦 Code + pre-trained weights available now.
🔥 Try it in your next vision project!
In DIY-SC, we improve foundational features using a light-weight adapter trained with carefully filtered and refined pseudo-labels.
🔧 Drop-in alternative to plain DINOv2 features!
📦 Code + pre-trained weights available now.
🔥 Try it in your next vision project!

Are you using DINOv2 for tasks that require semantic features? DIY-SC might be the alternative!
It refines DINOv2 or SD+DINOv2 features and achieves a new SOTA on the semantic correspondence dataset SPair-71k when not relying on annotated keypoints! [1/6]
genintel.github.io/DIY-SC
It refines DINOv2 or SD+DINOv2 features and achieves a new SOTA on the semantic correspondence dataset SPair-71k when not relying on annotated keypoints! [1/6]
genintel.github.io/DIY-SC
June 26, 2025 at 2:28 PM
🚀 Just accepted to ICCV 2025!
In DIY-SC, we improve foundational features using a light-weight adapter trained with carefully filtered and refined pseudo-labels.
🔧 Drop-in alternative to plain DINOv2 features!
📦 Code + pre-trained weights available now.
🔥 Try it in your next vision project!
In DIY-SC, we improve foundational features using a light-weight adapter trained with carefully filtered and refined pseudo-labels.
🔧 Drop-in alternative to plain DINOv2 features!
📦 Code + pre-trained weights available now.
🔥 Try it in your next vision project!
The CVML group at the @mpi-inf.mpg.de has been busy for CVPR. Check out our papers and come by the presentations!
🎉 Exciting News #CVPR2025!
We’re proud to announce that we have 5 papers accepted to the main conference and 7 papers accepted at various CVPR workshops this year!
We’re looking forward to sharing our research with the community in Nashville!
Stay tuned for more details! @mpi-inf.mpg.de
We’re proud to announce that we have 5 papers accepted to the main conference and 7 papers accepted at various CVPR workshops this year!
We’re looking forward to sharing our research with the community in Nashville!
Stay tuned for more details! @mpi-inf.mpg.de

June 11, 2025 at 12:07 PM
The CVML group at the @mpi-inf.mpg.de has been busy for CVPR. Check out our papers and come by the presentations!
Reposted by Thomas Wimmer
Hello world, we are now on Bluesky 🦋! Follow us to receive updates on exciting research and projects from our group!
#computervision #machinelearning #research
#computervision #machinelearning #research
April 9, 2025 at 1:03 PM
Hello world, we are now on Bluesky 🦋! Follow us to receive updates on exciting research and projects from our group!
#computervision #machinelearning #research
#computervision #machinelearning #research
Had the honor to present "Gaussians-to-Life" at #3DV2025 yesterday. In this work, we used video diffusion models to animate arbitrary 3D Gaussian Splatting scenes.
This work was a great collaboration with @moechsle.bsky.social, @miniemeyer.bsky.social, and Federico Tombari.
🧵⬇️
This work was a great collaboration with @moechsle.bsky.social, @miniemeyer.bsky.social, and Federico Tombari.
🧵⬇️

March 28, 2025 at 8:35 AM
Had the honor to present "Gaussians-to-Life" at #3DV2025 yesterday. In this work, we used video diffusion models to animate arbitrary 3D Gaussian Splatting scenes.
This work was a great collaboration with @moechsle.bsky.social, @miniemeyer.bsky.social, and Federico Tombari.
🧵⬇️
This work was a great collaboration with @moechsle.bsky.social, @miniemeyer.bsky.social, and Federico Tombari.
🧵⬇️
Can you do reasoning with diffusion models?
The answer is yes!
Take a look at Spatial Reasoning Models. Hats off for this amazing work!
The answer is yes!
Take a look at Spatial Reasoning Models. Hats off for this amazing work!

Can image generators solve visual Sudoku?
Naively, no, with sequentialization and the correct order, they can!
Check out @chriswewer.bsky.social's and Bart's SRM's for details.
Project: geometric-rl.mpi-inf.mpg.de/srm/
Paper: arxiv.org/abs/2502.21075
Code: github.com/Chrixtar/SRM
Naively, no, with sequentialization and the correct order, they can!
Check out @chriswewer.bsky.social's and Bart's SRM's for details.
Project: geometric-rl.mpi-inf.mpg.de/srm/
Paper: arxiv.org/abs/2502.21075
Code: github.com/Chrixtar/SRM
March 3, 2025 at 5:48 PM
Can you do reasoning with diffusion models?
The answer is yes!
Take a look at Spatial Reasoning Models. Hats off for this amazing work!
The answer is yes!
Take a look at Spatial Reasoning Models. Hats off for this amazing work!
Reposted by Thomas Wimmer

🏔️⛷️ Looking back on a fantastic week full of talks, research discussions, and skiing in the Austrian mountains!

January 31, 2025 at 7:38 PM
🏔️⛷️ Looking back on a fantastic week full of talks, research discussions, and skiing in the Austrian mountains!
Give a warm welcome to @janericlenssen.bsky.social!
Hello bluesky-world :)
Introducing 𝗠𝗘𝘁𝟯𝗥: 𝗠𝗲𝗮𝘀𝘂𝗿𝗶𝗻𝗴 𝗠𝘂𝗹𝘁𝗶-𝗩𝗶𝗲𝘄 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 𝗶𝗻 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗲𝗱 𝗜𝗺𝗮𝗴𝗲𝘀.
Lacking 3D consistency in generated images is a limitation of many current multi-view/video/world generative models. To quantitatively measure these inconsistencies, check out Mohammad Asims new work!
Introducing 𝗠𝗘𝘁𝟯𝗥: 𝗠𝗲𝗮𝘀𝘂𝗿𝗶𝗻𝗴 𝗠𝘂𝗹𝘁𝗶-𝗩𝗶𝗲𝘄 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 𝗶𝗻 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗲𝗱 𝗜𝗺𝗮𝗴𝗲𝘀.
Lacking 3D consistency in generated images is a limitation of many current multi-view/video/world generative models. To quantitatively measure these inconsistencies, check out Mohammad Asims new work!
January 16, 2025 at 5:29 PM
Give a warm welcome to @janericlenssen.bsky.social!
Quantitative evaluation of diffusion model outputs is hard!
We realized that we are often lacking metrics for comparing the quality of video and multi-view diffusion models. Especially the quantification of multi-view 3D consistency across frames is difficult.
But not anymore: Introducing MET3R 🧵
We realized that we are often lacking metrics for comparing the quality of video and multi-view diffusion models. Especially the quantification of multi-view 3D consistency across frames is difficult.
But not anymore: Introducing MET3R 🧵
January 15, 2025 at 5:21 PM
Quantitative evaluation of diffusion model outputs is hard!
We realized that we are often lacking metrics for comparing the quality of video and multi-view diffusion models. Especially the quantification of multi-view 3D consistency across frames is difficult.
But not anymore: Introducing MET3R 🧵
We realized that we are often lacking metrics for comparing the quality of video and multi-view diffusion models. Especially the quantification of multi-view 3D consistency across frames is difficult.
But not anymore: Introducing MET3R 🧵
Reposted by Thomas Wimmer

MEt3R: Measuring Multi-View Consistency in Generated Images
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, Jan Eric Lenssen
tl;dr: DUSt3R + DINO + FeatUp together want to be FID for multiview generation
arxiv.org/abs/2501.06336
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, Jan Eric Lenssen
tl;dr: DUSt3R + DINO + FeatUp together want to be FID for multiview generation
arxiv.org/abs/2501.06336

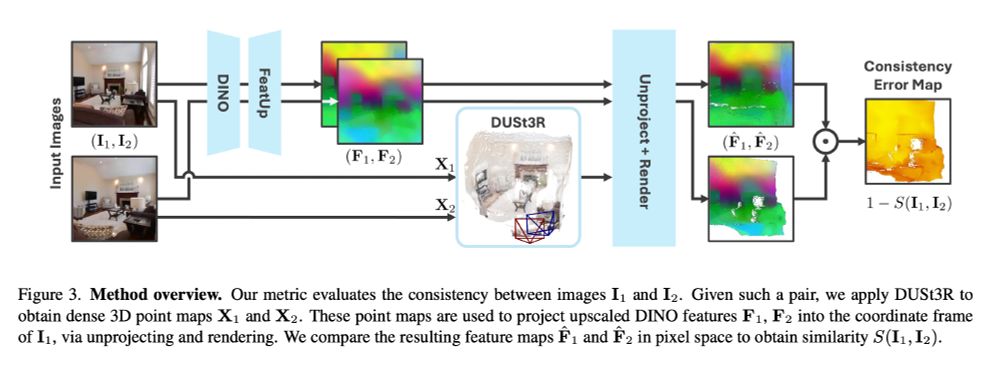
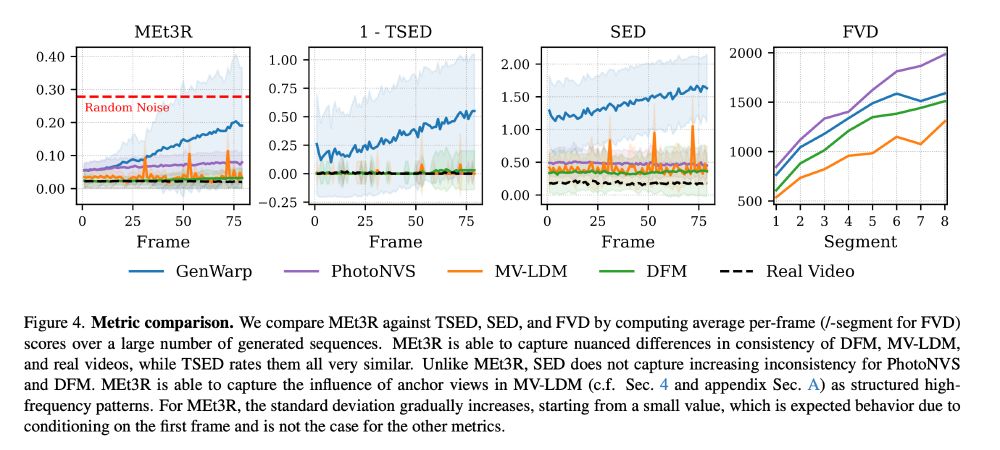

January 15, 2025 at 9:36 AM
MEt3R: Measuring Multi-View Consistency in Generated Images
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, Jan Eric Lenssen
tl;dr: DUSt3R + DINO + FeatUp together want to be FID for multiview generation
arxiv.org/abs/2501.06336
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, Jan Eric Lenssen
tl;dr: DUSt3R + DINO + FeatUp together want to be FID for multiview generation
arxiv.org/abs/2501.06336

MEt3R: Measuring Multi-View Consistency in Generated Images
Mohammad Asim, Christopher Wewer, @wimmerthomas.bsky.social, Bernt Schiele, Jan Eric Lenssen
tl;dr: DUSt3R-based method to measure multi-view consistency of generated views without given camera poses
arxiv.org/abs/2501.06336
Mohammad Asim, Christopher Wewer, @wimmerthomas.bsky.social, Bernt Schiele, Jan Eric Lenssen
tl;dr: DUSt3R-based method to measure multi-view consistency of generated views without given camera poses
arxiv.org/abs/2501.06336




January 14, 2025 at 1:19 PM
Reposted by Thomas Wimmer

After my general computer vision starter pack is now full (150/150 entries reached), here is one specific to 3D Vision: go.bsky.app/Cfm9XFe
November 21, 2024 at 8:15 AM
After my general computer vision starter pack is now full (150/150 entries reached), here is one specific to 3D Vision: go.bsky.app/Cfm9XFe