



Jean Czerlinski Ortega
@jeanimal.bsky.social
Sometimes Google engineer modeling things and celebrating non-things: machine learning, incentives, behavior, ethics, physics.
Former member of Gigerenzer's Adaptive Behavior and Cognition group.
Former member of Gigerenzer's Adaptive Behavior and Cognition group.
🧵1/
Fast-moving domains like cybersecurity evolve too quickly for static rules.
Adaptive regulation has scheduled review and updates, but hackers evolve faster.
An approach I call “hindsight accountability” can help:
medium.com/@jeanimal/hi...
Fast-moving domains like cybersecurity evolve too quickly for static rules.
Adaptive regulation has scheduled review and updates, but hackers evolve faster.
An approach I call “hindsight accountability” can help:
medium.com/@jeanimal/hi...

Hindsight Accountability: Deterring the Gaming of Regulations
From sports dopers to hackers, some cheaters can only be caught in hindsight
medium.com
May 21, 2025 at 9:33 AM
🧵1/
Fast-moving domains like cybersecurity evolve too quickly for static rules.
Adaptive regulation has scheduled review and updates, but hackers evolve faster.
An approach I call “hindsight accountability” can help:
medium.com/@jeanimal/hi...
Fast-moving domains like cybersecurity evolve too quickly for static rules.
Adaptive regulation has scheduled review and updates, but hackers evolve faster.
An approach I call “hindsight accountability” can help:
medium.com/@jeanimal/hi...
LLM-lasso keeps the theory of Lasso, while using an LLM to analyze domain-specific metadata to improve the weights of the regularizer. Result: better performance on biomedical case studies.
Plus, since lasso reduces the number of features, it's more interpretable!
arxiv.org/abs/2502.10648
Plus, since lasso reduces the number of features, it's more interpretable!
arxiv.org/abs/2502.10648

LLM-Lasso: A Robust Framework for Domain-Informed Feature Selection and Regularization
We introduce LLM-Lasso, a novel framework that leverages large language models (LLMs) to guide feature selection in Lasso $\ell_1$ regression. Unlike traditional methods that rely solely on numerical ...
arxiv.org
March 2, 2025 at 4:36 PM
LLM-lasso keeps the theory of Lasso, while using an LLM to analyze domain-specific metadata to improve the weights of the regularizer. Result: better performance on biomedical case studies.
Plus, since lasso reduces the number of features, it's more interpretable!
arxiv.org/abs/2502.10648
Plus, since lasso reduces the number of features, it's more interpretable!
arxiv.org/abs/2502.10648
Reposted by Jean Czerlinski Ortega

The slides for my lectures on (Bayesian) Active Learning, Information Theory, and Uncertainty are online now 🥳 They cover quite a bit from basic information theory to some recent papers:
blackhc.github.io/balitu/
and I'll try to add proper course notes over time 🤗
blackhc.github.io/balitu/
and I'll try to add proper course notes over time 🤗
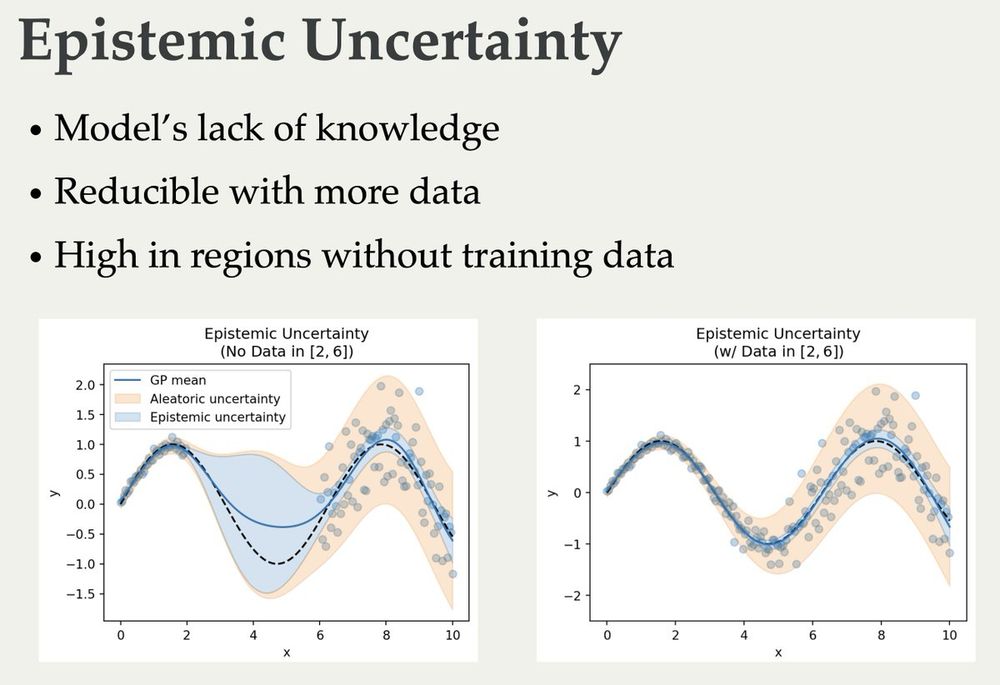
December 17, 2024 at 6:50 AM
The slides for my lectures on (Bayesian) Active Learning, Information Theory, and Uncertainty are online now 🥳 They cover quite a bit from basic information theory to some recent papers:
blackhc.github.io/balitu/
and I'll try to add proper course notes over time 🤗
blackhc.github.io/balitu/
and I'll try to add proper course notes over time 🤗
Reposted by Jean Czerlinski Ortega

Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the technique behind its success: scaling test-time compute
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!

December 16, 2024 at 9:42 PM
Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the technique behind its success: scaling test-time compute
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
Double descent enables a chat bot with a billion parameters to perform well and not overfit. But how does double descent work? I use simulations fitting linear regressions, plots, and tables for solving systems of equations to build intuition.
medium.com/@jeanimal/ho...
medium.com/@jeanimal/ho...

How double descent breaks the shackles of the interpolation threshold
Insights for deep learning from solving N equations with N unknowns
medium.com
October 20, 2024 at 3:23 PM
Double descent enables a chat bot with a billion parameters to perform well and not overfit. But how does double descent work? I use simulations fitting linear regressions, plots, and tables for solving systems of equations to build intuition.
medium.com/@jeanimal/ho...
medium.com/@jeanimal/ho...