



Giwon Hong
@giwonhong.bsky.social
PhD student in ILCC (NLP) program at the University of Edinburgh
Reposted by Giwon Hong

MMLU-Redux just touched down at #NAACL2025! 🎉
Wish I could be there for our "Are We Done with MMLU?" poster today (9:00-10:30am in Hall 3, Poster Session 7), but visa drama said nope 😅
If anyone's swinging by, give our research some love! Hit me up if you check it out! 👋
Wish I could be there for our "Are We Done with MMLU?" poster today (9:00-10:30am in Hall 3, Poster Session 7), but visa drama said nope 😅
If anyone's swinging by, give our research some love! Hit me up if you check it out! 👋

May 2, 2025 at 1:00 PM
MMLU-Redux just touched down at #NAACL2025! 🎉
Wish I could be there for our "Are We Done with MMLU?" poster today (9:00-10:30am in Hall 3, Poster Session 7), but visa drama said nope 😅
If anyone's swinging by, give our research some love! Hit me up if you check it out! 👋
Wish I could be there for our "Are We Done with MMLU?" poster today (9:00-10:30am in Hall 3, Poster Session 7), but visa drama said nope 😅
If anyone's swinging by, give our research some love! Hit me up if you check it out! 👋
Reposted by Giwon Hong

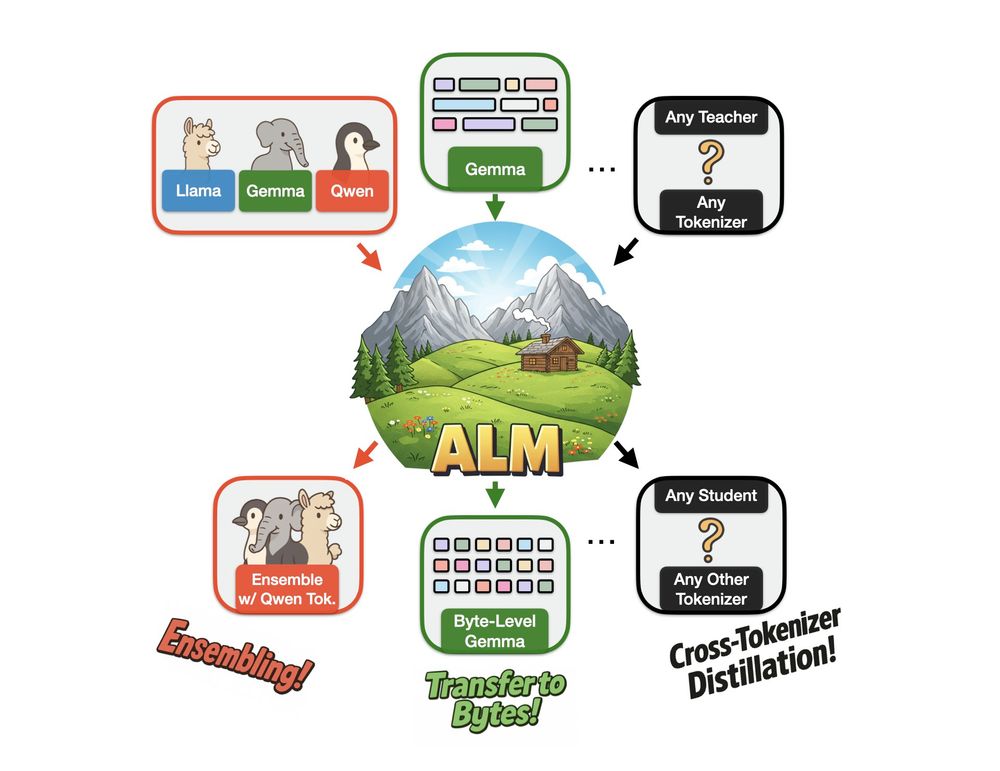
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
April 2, 2025 at 6:36 AM
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
Reposted by Giwon Hong

Joining the Generative AI Lab (GAIL, gail.ed.ac.uk) at the University of Edinburgh as a GAIL Fellow! Excited for what's ahead 🤗

Generative AI Laboratory
gail.ed.ac.uk
November 19, 2024 at 11:17 PM
Joining the Generative AI Lab (GAIL, gail.ed.ac.uk) at the University of Edinburgh as a GAIL Fellow! Excited for what's ahead 🤗
🤔How to achieve efficient ICL without storing a huge dataset in one prompt?
💡Mixtures of In-Context Learners (𝗠𝗼𝗜𝗖𝗟): we treat LLMs prompted with subsets of demonstrations as experts and learn a weighting function to optimise the distribution over the continuation (🧵1/n)
💡Mixtures of In-Context Learners (𝗠𝗼𝗜𝗖𝗟): we treat LLMs prompted with subsets of demonstrations as experts and learn a weighting function to optimise the distribution over the continuation (🧵1/n)

November 18, 2024 at 6:36 PM
🤔How to achieve efficient ICL without storing a huge dataset in one prompt?
💡Mixtures of In-Context Learners (𝗠𝗼𝗜𝗖𝗟): we treat LLMs prompted with subsets of demonstrations as experts and learn a weighting function to optimise the distribution over the continuation (🧵1/n)
💡Mixtures of In-Context Learners (𝗠𝗼𝗜𝗖𝗟): we treat LLMs prompted with subsets of demonstrations as experts and learn a weighting function to optimise the distribution over the continuation (🧵1/n)
Reposted by Giwon Hong
I’ll be travelling to London from Wednesday to Friday for an upcoming event and would be very happy to meet up! 🚀
I'd love to chat about my recent works (DeCoRe, MMLU-Redux, etc.). DM me if you’re around! 👋
DeCoRe: arxiv.org/abs/2410.18860
MMLU-Redux: arxiv.org/abs/2406.04127
I'd love to chat about my recent works (DeCoRe, MMLU-Redux, etc.). DM me if you’re around! 👋
DeCoRe: arxiv.org/abs/2410.18860
MMLU-Redux: arxiv.org/abs/2406.04127

November 18, 2024 at 1:48 PM
I’ll be travelling to London from Wednesday to Friday for an upcoming event and would be very happy to meet up! 🚀
I'd love to chat about my recent works (DeCoRe, MMLU-Redux, etc.). DM me if you’re around! 👋
DeCoRe: arxiv.org/abs/2410.18860
MMLU-Redux: arxiv.org/abs/2406.04127
I'd love to chat about my recent works (DeCoRe, MMLU-Redux, etc.). DM me if you’re around! 👋
DeCoRe: arxiv.org/abs/2410.18860
MMLU-Redux: arxiv.org/abs/2406.04127