
Yuki Asano
@yukimasano.bsky.social
1.3K followers
56 following
19 posts
Professor at University of Technology Nuremberg
Head of Fundamental AI Lab
Posts
Media
Videos
Starter Packs



Yuki Asano
@yukimasano.bsky.social
· Dec 23


Yuki Asano
@yukimasano.bsky.social
· Dec 10

Reposted by Yuki Asano

Reposted by Yuki Asano




Yuki Asano
@yukimasano.bsky.social
· Nov 28

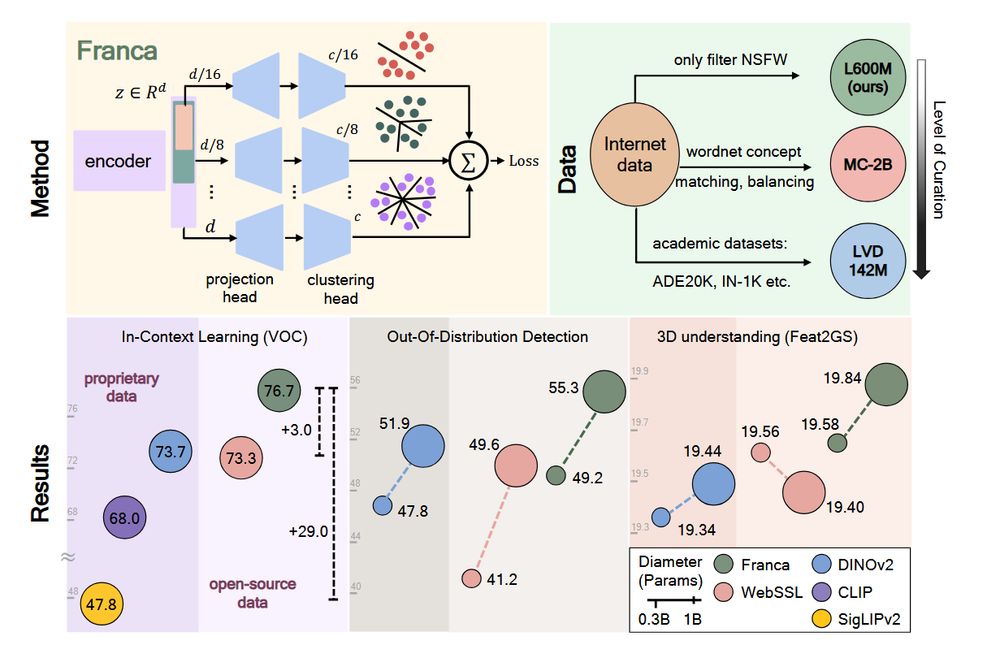
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
Decoder-only large language model (LLM)-based embedding models are beginning to outperform BERT or T5-based embedding models in general-purpose text embedding tasks, including dense vector-based retri...
arxiv.org






Yuki Asano
@yukimasano.bsky.social
· Nov 26

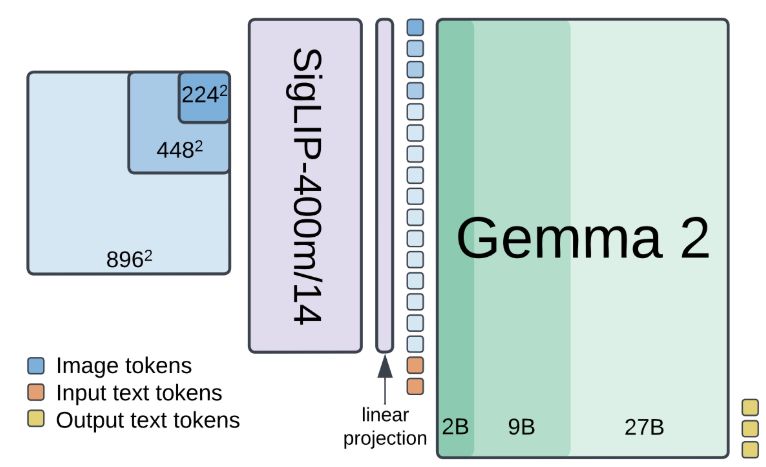
Do better language models have crisper vision?
How well do text-only Large Language Models (LLMs) grasp the visual world? As LLMs are increasingly used in computer vision, addressing this question becomes both fundamental and pertinent. However, e...
arxiv.org
Reposted by Yuki Asano


Yuki Asano
@yukimasano.bsky.social
· Nov 26
Yuki Asano
@yukimasano.bsky.social
· Nov 26
Prompt Generation Networks for Input-Space Adaptation of Frozen Vision Transformers
With the introduction of the transformer architecture in computer vision, increasing model scale has been demonstrated as a clear path to achieving performance and robustness gains. However, with mode...
arxiv.org




Yuki Asano
@yukimasano.bsky.social
· Nov 26
Yuki Asano
@yukimasano.bsky.social
· Nov 26
Yuki Asano
@yukimasano.bsky.social
· Nov 20
Reposted by Yuki Asano

Kosta Derpanis
@csprofkgd.bsky.social
· Nov 19

