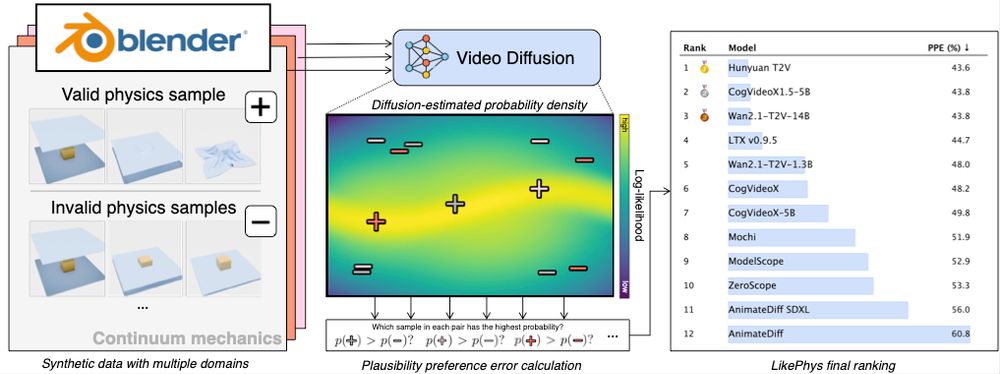
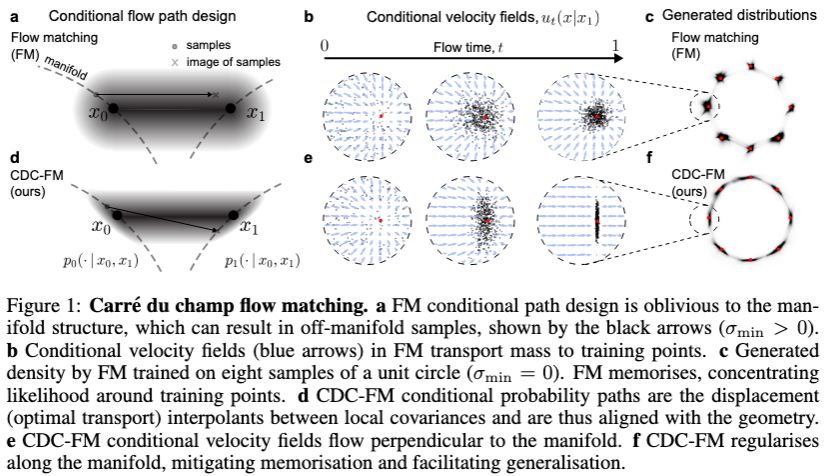
Kwang Moo Yi
@kmyid.bsky.social
38 followers
39 following
20 posts
Assistant Professor of Computer Science at the University of British Columbia. I also post my daily finds on arxiv.
Posts
Media
Videos
Starter Packs