



Hazel Doughty
@hazeldoughty.bsky.social
260 followers
130 following
22 posts
Assistant Professor at Leiden University, NL. Computer Vision, Video Understanding.
https://hazeldoughty.github.io
Posts
Media
Videos
Starter Packs
Reposted by Hazel Doughty

Reposted by Hazel Doughty


Reposted by Hazel Doughty
Reposted by Hazel Doughty
Dima Damen
@dimadamen.bsky.social
· Apr 3
🛑📢
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
Reposted by Hazel Doughty

Reposted by Hazel Doughty

Diane Larlus
@dlarlus.bsky.social
· Feb 7
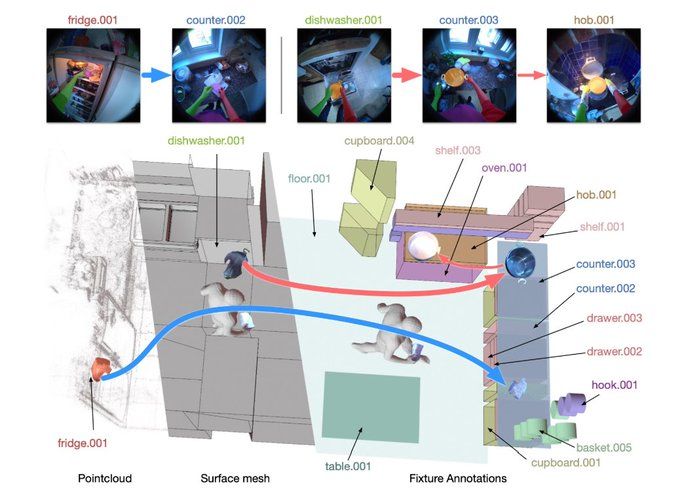
📢 Today we're releasing a new highly detailed dataset for video understanding: HD-EPIC
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.





Reposted by Hazel Doughty
Hazel Doughty
@hazeldoughty.bsky.social
· Dec 10



Hazel Doughty
@hazeldoughty.bsky.social
· Dec 10

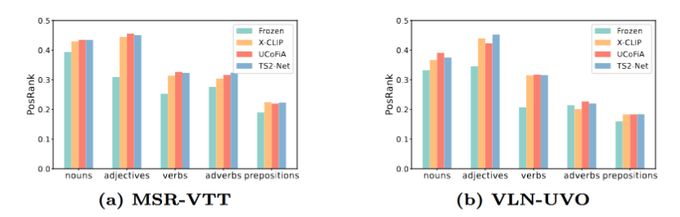
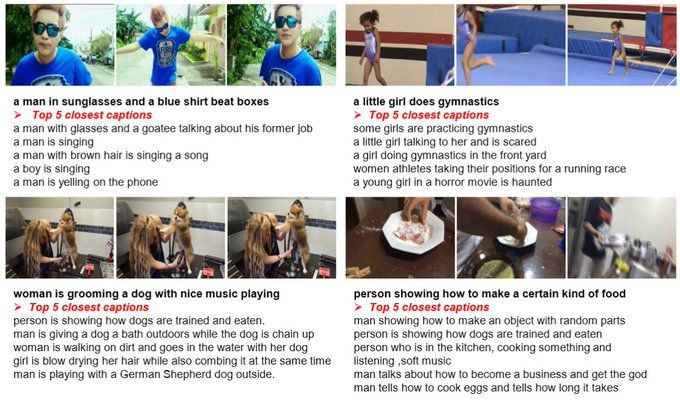
LocoMotion: Learning Motion-Focused Video-Language Representations
This paper strives for motion-focused video-language representations. Existing methods to learn video-language representations use spatial-focused data, where identifying the objects and scene is ofte...
arxiv.org
Hazel Doughty
@hazeldoughty.bsky.social
· Dec 10
