

Hamish Ivison
@hamishivi.bsky.social
1.2K followers
370 following
62 posts
I (try to) do NLP research. Antipodean abroad.
currently doing PhD @uwcse,
prev @usyd @ai2
🇦🇺🇨🇦🇬🇧
ivison.id.au
Posts
Media
Videos
Starter Packs
Reposted by Hamish Ivison





Reposted by Hamish Ivison

Nathan Lambert
@natolambert.bsky.social
· Mar 17
Hamish Ivison
@hamishivi.bsky.social
· Mar 4

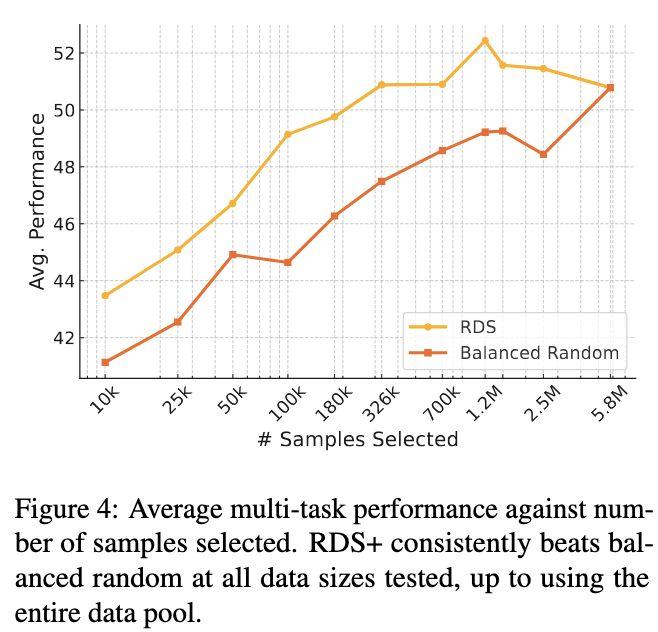

Hamish Ivison
@hamishivi.bsky.social
· Mar 4



Hamish Ivison
@hamishivi.bsky.social
· Feb 20

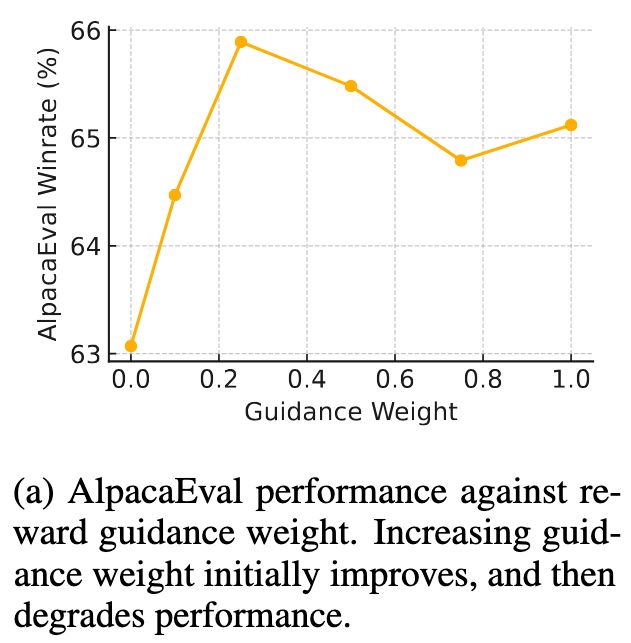
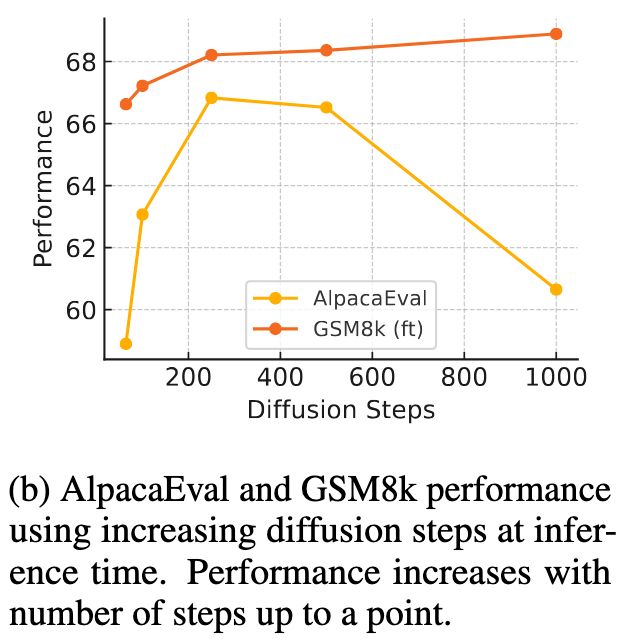
Hamish Ivison
@hamishivi.bsky.social
· Feb 20
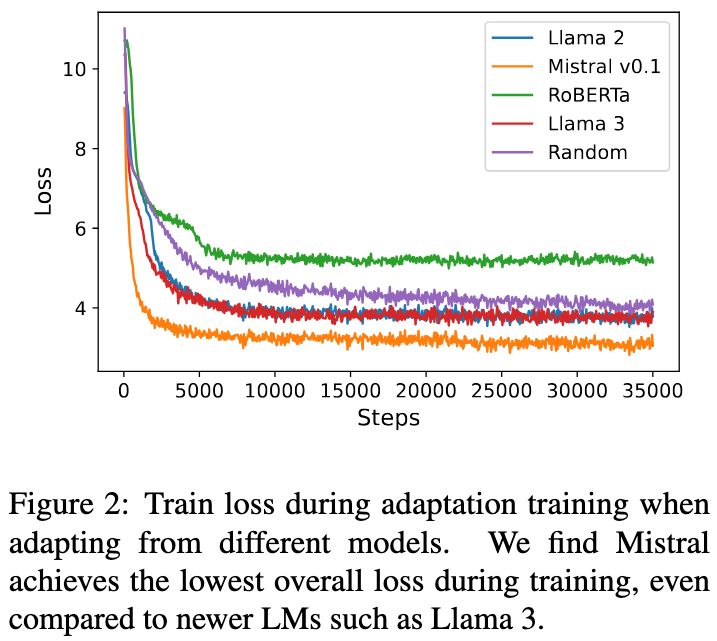


Reposted by Hamish Ivison


Hamish Ivison
@hamishivi.bsky.social
· Jan 30